背景
Koordinator 作为一个积极发展的开源项目,自 2022 年 4 月发布 v0.1.0 版本以来,经历了多次迭代,持续为 Kubernetes 生态系统带来创新和增强。项目的核心是提供混部工作负载编排、混部资源调度、混部资源隔离和混部性能调优的综合解决方案,帮助用户优化容器性能,并提升集群资源使用效率。
在过去的版本迭代中,Koordinator 社区不断壮大,已经得到了包括阿里巴巴、蚂蚁科技、Intel、小米、小红书、爱奇艺、360、有赞、趣玩、美亚柏科、PITS 等知名企业工程师的积极参与和贡献。每一个版本都是在社区共同努力下推进的,反映了项目在实际生产环境中解决问题的能力。
今天我们很高兴的向大家宣布,Koordinator v1.4.0 版本正式发布。在本次发布中,Koordinator 引入了 Kubernetes 与 YARN 负载混部、NUMA 拓扑对齐策略、CPU 归一化和冷内存上报等新特性,同时重点增强了弹性配额管理、宿主机非容器化应用的 QoS 管理、重调度防护策略等领域的功能。这些新增和改进点旨在更好地支持企业级 Kubernetes 集群环境,特别是对于复杂和多样化的应用场景。
v1.4.0 版本的发布,将为用户带来更多的计算负载类型支持和更灵活的资源管理机制,我们期待这些改进能够帮助用户应对更多企业资源管理挑战。在 v1.4.0 版本中,共有 11 位新加入的开发者参与到了 Koordinator 社区的建设,他们是 @shaloulcy,@baowj-678,@zqzten,@tan90github,@pheianox,@zxh326,@qinfustu,@ikaven1024,@peiqiaoWang,@bogo-y,@xujihui1985,感谢期间各位社区同学的积极参与和贡献,也感谢所有同学在社区的持续投入。
版本功能特性解读
1. 支持 K8s 与 YARN 混部
Koordinator 已经支持了 K8s 生态内的在离线混部,然而在 K8s 生态外,仍有相当数量的大数据任务运行在传统的 Hadoop YARN 之上。YARN 作为发展多年的大数据生态下的资源管理系统,承载了包括 MapReduce、Spark、Flink 以及 Presto 等在内的多种计算引擎。
Koordinator 社区会同来自阿里云、小红书、蚂蚁金服的开发者们共同启动了 Hadoop YARN 与 K8s 混部项目 Koordinator YARN Copilot,支持将 Hadoop NodeManager 运行在 kubernetes 集群中,充分发挥不同类型负载错峰复用的技术价值。Koordinator YARN Copilot 具备以下特点:
- 面向开源生态:基于 Hadoop YARN 开源版本,不涉及对 YARN 的侵入式改造;
- 统一资源优先级和 QoS 策略:YARN NM 使用 Koordinator 的 Batch 优先级资源,遵循 Koordinator QoS 管理策略;
- 节点级别的资源共享:Koordinator 提供的混部资源,既可被 K8s Pod 使用,也可被 YARN task使用,不同类型的离线应用可运行在同一节点。

关于 Koordinator YARN Copilot 的详细设计,以及在小红书生产环境的使用情况,请参考往期文章以及社区官方文档。
2. 引入 NUMA 拓扑对齐策略
运行在 Kubernetes 集群中的工作负载日益多样化。尤其是在机器学习等领域,对于高性能计算资源的需求持续上升。在这些领域中,不仅需要大量 CPU 资源,还经常需要 GPU 和 RDMA 等其他高速计算资源配合使用;并且,为了获得最佳的性能,这些资源往往需要在同一个 NUMA 节点,甚至同一个 PCIE 中。
Kubernetes 的 Kubelet 提供了 Topology Manager 来管理资源分配的 NUMA 拓扑,试图在 Kubelet 的 Admission 阶段从节点层面对齐多种资源的拓扑。然而,节点组件没有调度器的全局视角以及为 Pod 选择节点的时机,可能导致 Pod 被调度到无法满足拓扑对齐策略的节点上,从而导致 Pod 由于 Topology Affinity错误无法启动。
为了解决这一问题,Koordinator 将 NUMA 拓扑选择和对齐的时机放在中心调度器中,从集群级别优化资源之间的 NUMA 拓扑。在本次发布的版本中,Koordinator 将 CPU 资源(包含 Batch 资源)的 NUMA 感知调度和 GPU 设备的 NUMA 感知调度作为 alpha 功能支持,整套 NUMA 感知调度快速演进中。
koordinator 支持用户通过节点的 Label 配置节点上多种资源的 NUMA 拓扑对齐策略,可配置策略如下:
None是默认策略,不执行任何拓扑对齐。BestEffort表示节点不严格按照 NUMA 拓扑对齐来分配资源。只要节点的剩余总量满足 Pods 的需求,调度器总是可以将这样的节点分配给 Pods。Restricted表示节点严格按照 NUMA 拓扑对齐来分配资源,即调度器在分配多个资源时必须只选择相同的一个或多个 NUMA 节点,否则不应使用该节点;可以使用多个 NUMA 节点。例如,如果一个Pod请求 33C,并且每个 NUMA 节点有 32C,那么它可以被分配使用两个 NUMA 节点。如果这个Pod还需要请求 GPU/RDMA,那么它需要位于与 CPU 相同的 NUMA 节点上。SingleNUMANode与Restricted类似,也是严格按照 NUMA 拓扑对齐,但与Restricted不同的是,Restricted允许使用多个NUMA节点,而SingleNUMANode只允许使用一个NUMA 节点。
举例,我们可以为 node-0设置策略 SingleNUMANode:
apiVersion: v1
kind: Node
metadata:
labels:
node.koordinator.sh/numa-topology-policy: "SingleNUMANode"
name: node-0
spec:
...
在生产环境中,用户可能已经开启了 Kubelet 的拓扑对齐策略,这个策略会由 koordlet 更新到 NodeResourceTopologyCRD 对象中的 TopologyPolicies字段。当 Kubelet 的策略和用户在 Node 上设置的策略相冲突时,以 Kubelet 策略为准。Koordinator 调度器基本采用与 Kubelet Topology Manager 相同的 NUMA 对齐策略语义,Kubelet 策略 SingleNUMANodePodLevel 和SingleNUMANodeContainerLevel被映射为 SingleNUMANode。
在为节点配置好 NUMA 对齐策略的前提下,调度器可以为每个 Pod 选出许多个符合条件的 NUMA Node 分配结果。Koordinator 当前支持 NodeNUMAResource 插件配置 CPU 和内存资源的 NUMA Node 分配结果打分策略,包括 LeastAllocated和 MostAllocated, 默认为 LeastAllocated 策略,资源支持配置权重。调度器最终将选择得分最高的 NUMA Node 分配结果。如下例,我们配置 NUMA Node 分配结果打分策略为 MostAllocated:
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- name: NodeNUMAResource
args:
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: NodeNUMAResourceArgs
scoringStrategy: # Here configure Node level scoring strategy
type: MostAllocated
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: "kubernetes.io/batch-cpu"
weight: 1
- name: "kubernetes.io/batch-memory"
weight: 1
numaScoringStrategy: # Here configure NUMA-Node level scoring strategy
type: MostAllocated
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: "kubernetes.io/batch-cpu"
weight: 1
- name: "kubernetes.io/batch-memory"
weight: 1
3. ElasticQuota 再进化
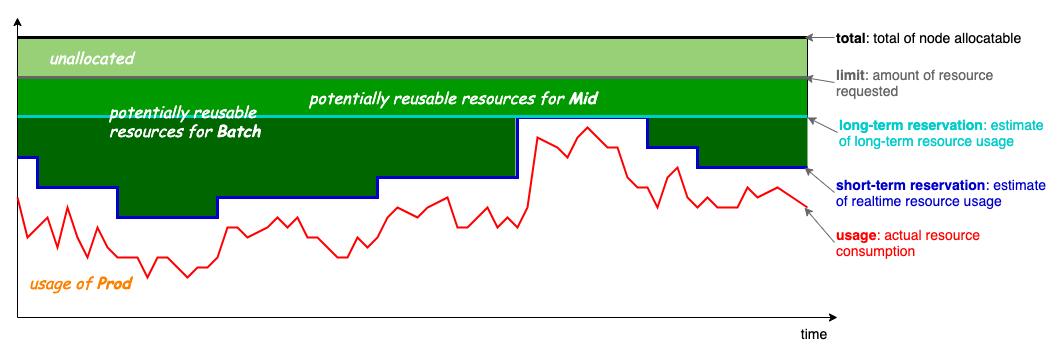
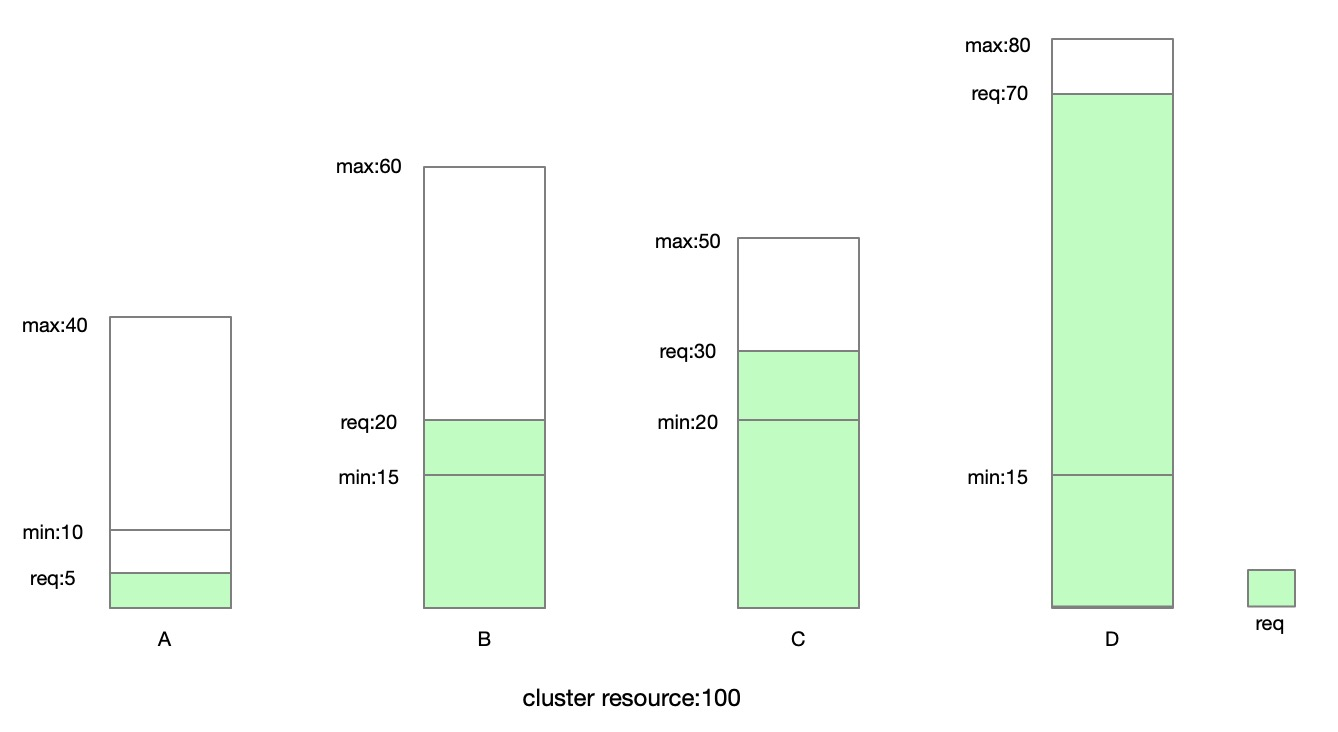
为了充分地利用集群资源、降低管控系统成本,用户常常将多个租户的负载部署在一个集群中。在集群资源有限的情况下,不同租户之间必然会发生资源争抢。有的租户的负载可能一直被满足,而有的租户的负载一直无法得到执行。这就产生对公平性的诉求。配额机制是非常自然地保障租户间公平性的方式,给每个租户一个配额,租户可以使用配额内的资源,超过配额的任务将不被调度和执行。然而,简单的配额管理无法满足租户对云的弹性期待。用户希望除了配额之内的资源请求可以被满足外,配额之外的资源请求也可以按需地被满足。
在之前的版本中,Koordinator 复用了上游 ElasticQuota 的协议,允许租户设置 Min 表达其一定要满足的资源诉求,允许设置 Max 限制其最大可以使用的资源和表达在集群资源不足的情况下对集群剩余资源的使用权重。另外,koordinator 观察到,一些租户可能通过 Min 申请了配额,但是实际的任务申请可能并没有充分利用该配额。由此,为了更近一步地提高资源利用率,Koordinator 允许租户间借用/归还资源。
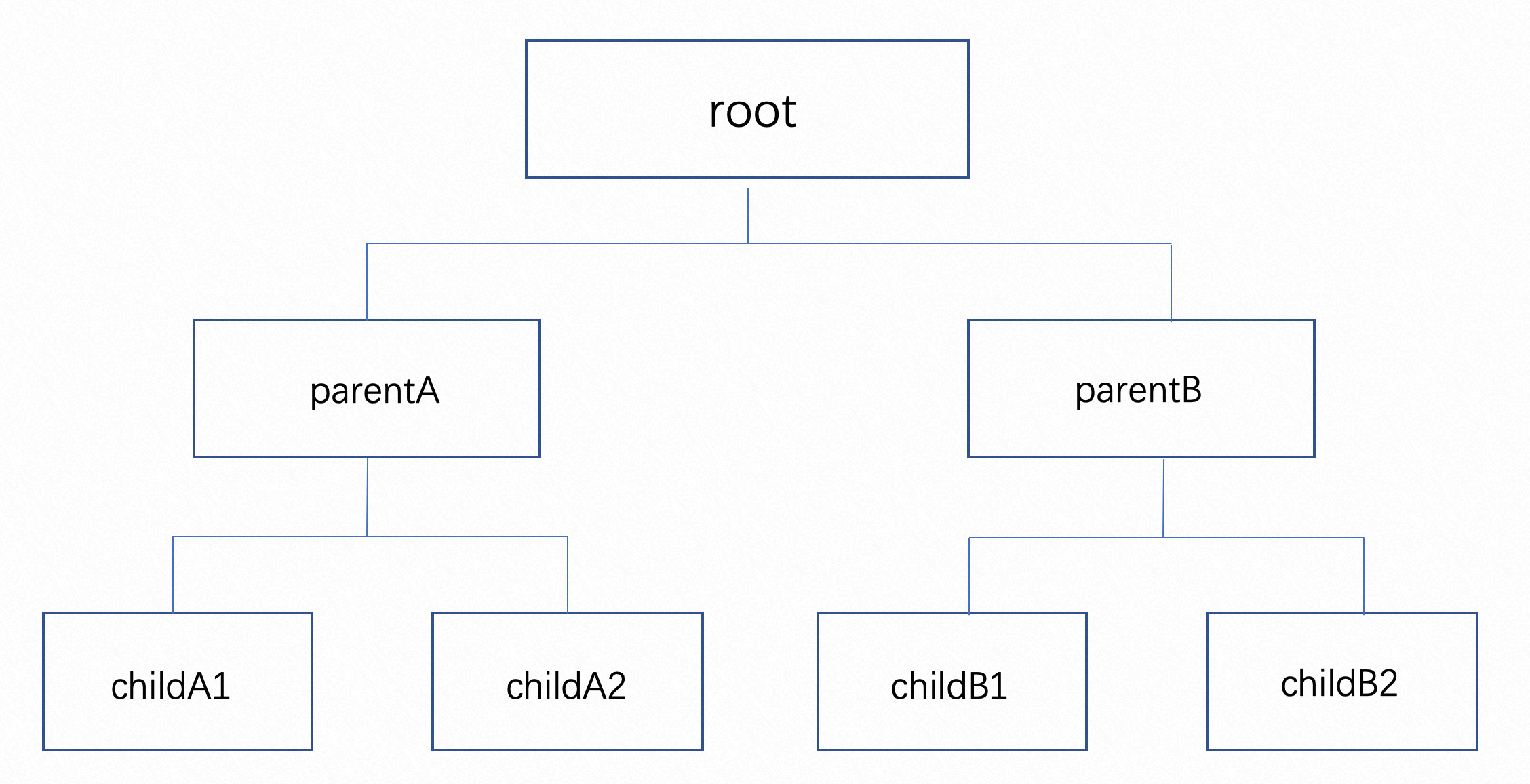
除了提供弹性的配额机制满足租户按需诉求外,Koordinator 在 ElasticQuota 上增加注解将其组织成树的结构,方便用户表达树形的组织架构。
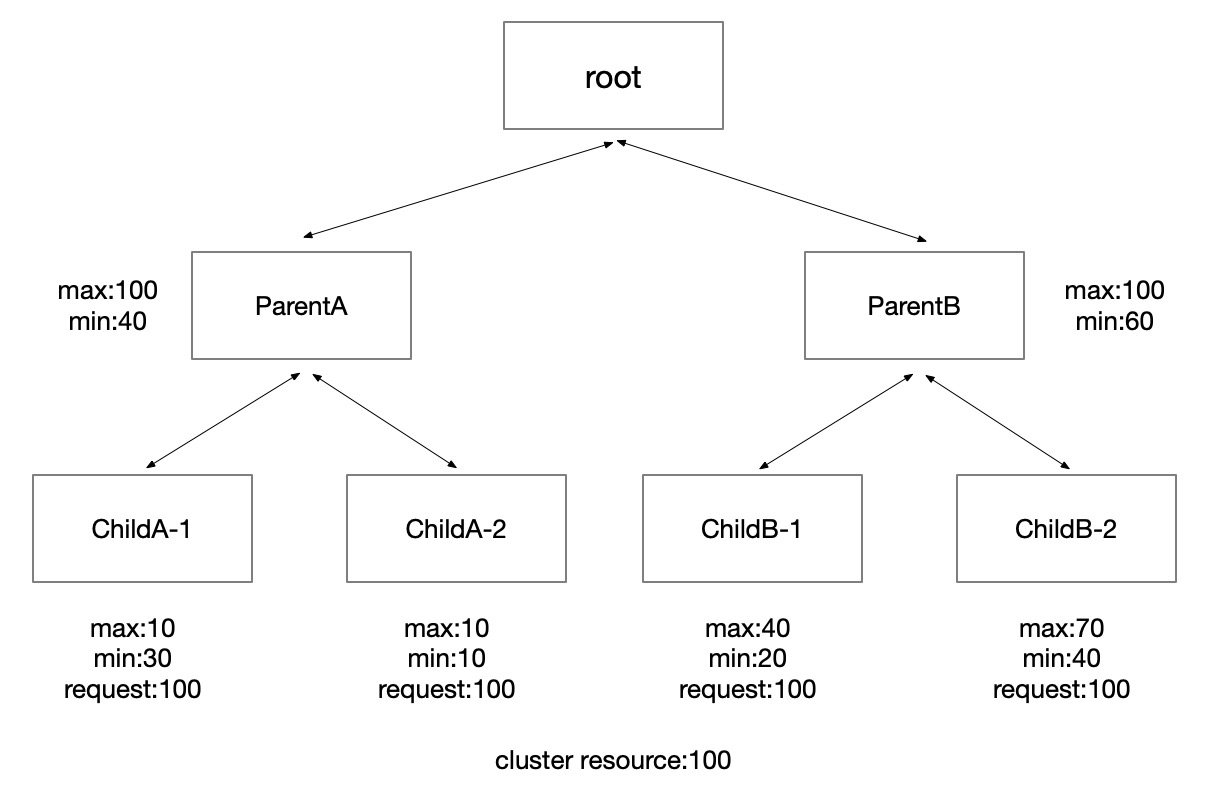
上图是使用了 Koordinator 弹性配额的集群中常见的 Quota 结构树。Root Quota 是连接配额与集群中实际资源之间的桥梁。在之前的设计中,Root Quota 只在调度器逻辑中存在,在本次发布中,我们将 Root Quota 也通过 CRD 的形式暴露给用户,用户可以通过 koordinator-root-quota 这个 ElasticQuota CRD 查看 Root Quota 信息。
3.1 引入 Multi QuotaTree
大型集群中的节点的形态是多样的,例如云厂商提供的 ECS VM 会有不同的架构,常见的是 amd64 和 arm64,相同架构又会有不同种类的机型,而且一般会把节点按可用区划分。不同类型的节点放到同一个 Quota Tree 中管理时,其特有的属性将丢失,当用户希望精细化管理机器的特有属性时,当前的 ElasticQuota 显得不够精确。为了满足用户灵活的资源管理或资源隔离诉求,Koordinator 支持用户将集群中的资源划分为多份,每一份由一个 Quota Tree 来管理,如下图所示:
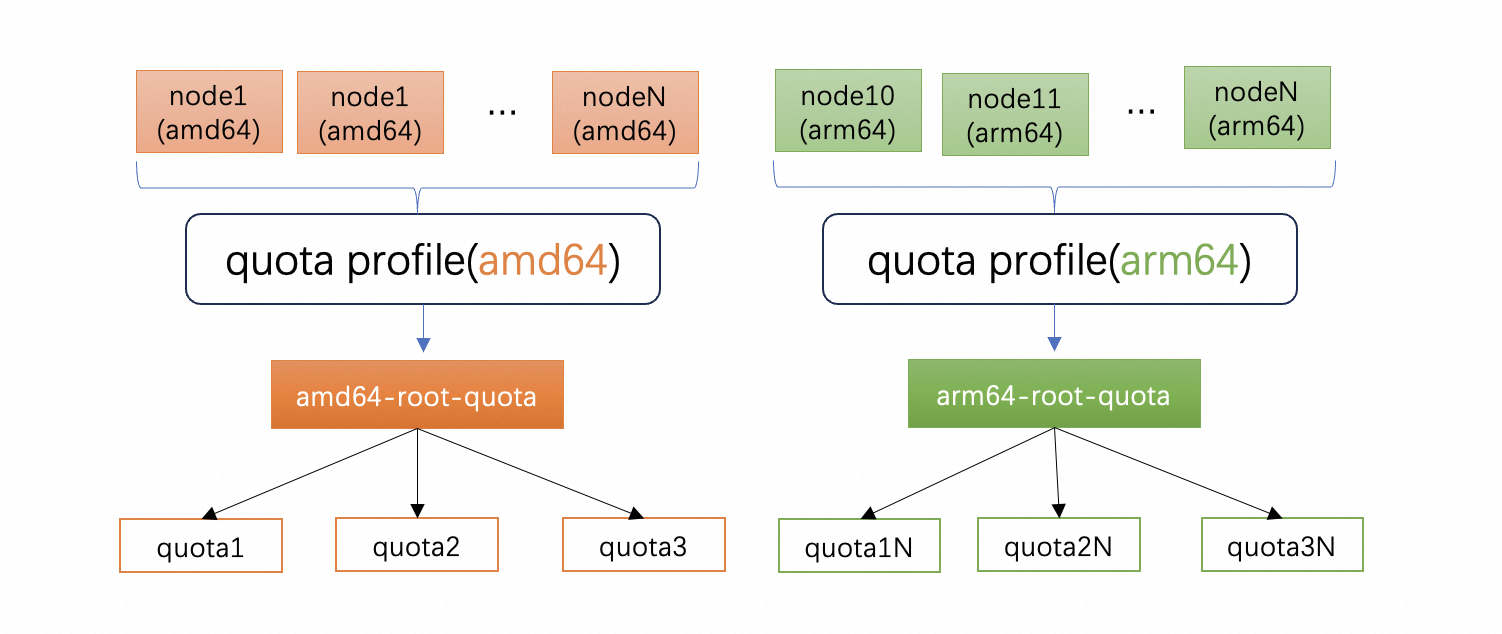
同时,为了帮助用户简化管理复杂性,Koordinator 在 v1.4.0 中 引入了 ElasticQuotaProfile 机制,用户可以通过 nodeSelector 快速的将节点关联到不同的 QuotaTree 中,如下实例所示:
apiVersion: quota.koordinator.sh/v1alpha1
kind: ElasticQuotaProfile
metadata:
labels:
kubernetes.io/arch: amd64
name: amd64-profile
namespace: kube-system
spec:
nodeSelector:
matchLabels:
kubernetes.io/arch: amd64 // 挑选 amd64 节点
quotaName: amd64-root-quota // 匹配的 root quota 名称
---
apiVersion: quota.koordinator.sh/v1alpha1
kind: ElasticQuotaProfile
metadata:
labels:
kubernetes.io/arch: arm64
name: arm64-profile
namespace: kube-system
spec:
nodeSelector:
matchLabels:
kubernetes.io/arch: arm64 // 挑选 arm64 节点
quotaName: arm64-root-quota // 匹配的 root quota 名称
关联好 QuotaTree 之后,用户在每一个 QuotaTree 中与之前的 ElasticQuota 用法一致。当用户提交 Pod 到对应的 Quota 时,当前仍然需要用户完成 Pod NodeAffinity 的管理,以确保 Pod 运行在正确的节点上。未来,我们会增加一个特性帮助用户自动管理 Quota 到 Node 的映射关系。
3.2 支持 non-preemptible
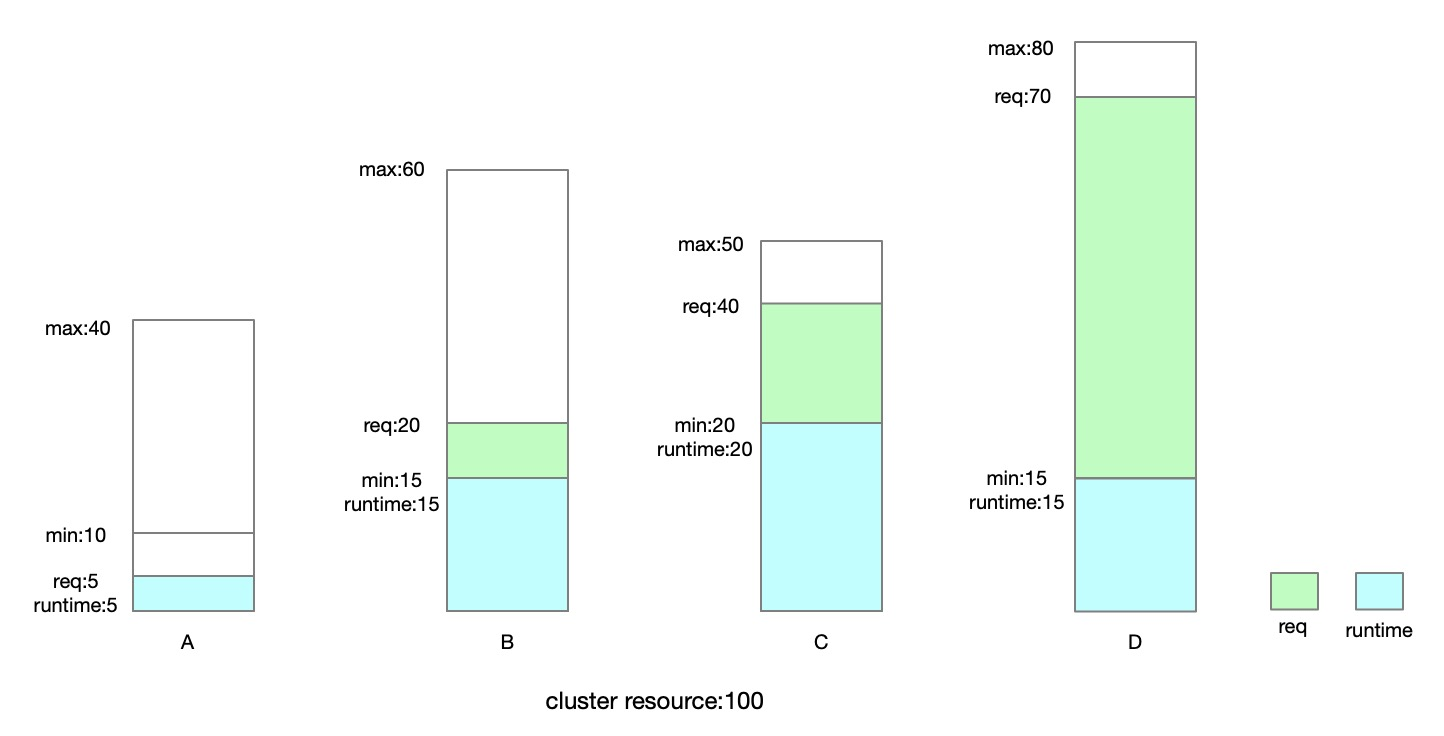
Koordinator ElasticQuota 支持把 ElasticQuota 中 Min 未使用的部分共享给其他 ElasticQuota 使用从而提高资源利用效率,但当资源紧张时,会通过抢占机制把借用配额的 Pod 抢占驱逐走拿回资源。
在实际生产环境中,有一些在线服务如果从其他 ElasticQuota 中借用了这部分额度,后续又发生了抢占,是可能影响服务质量的。这类工作负载实质上是不能被抢占的。
为了实现这个机制,Koordinator v1.4.0 引入了新的 API,用户只需要在 Pod 上声明 quota.scheduling.koordinator.sh/preemptible: false 表示这个 Pod 不可以被抢占。
调度器调度时发现 Pod 声明了不可抢占,那么此类 Pod 的可用配额的上限不能超过 min,所以这里也需要注意的是,启用该能力时,一个 ElasticQuota 的 min 需要设置的合理,并且集群内有相应的资源保障。
这个特性不会破坏原有的行为。
apiVersion: v1
kind: Pod
metadata:
name: pod-example
namespace: default
labels:
quota.scheduling.koordinator.sh/name: "quota-example"
quota.scheduling.koordinator.sh/preemptible: false
spec:
...
3.3 其它改进
- Koordinator Scheduler 过去支持跨 Namespace 使用同一个 ElasticQuota 对象,但有一些场景下,希望只被一个或者多个有限的 Namespace 可以共享同一个对象,为了支持这个场景,用户可以在 ElasticQuota 上增加 annotation
quota.scheduling.koordinator.sh/namespaces,对应的值为一个 JSON 字符串数组。 - 性能优化:过去的实现中,当 ElasticQuota 发生变化时,ElasticQuota 插件会重建整棵 Quota 树,在 v1.4.0 版本中做了优化。
- 支持忽略 Overhead:当 Pod 使用一些安全容器时,一般是在 Pod 中声明 Overhead 表示安全容器自身的资源开销,但这部分资源成本最终是否归于终端用户承担取决于资源售卖策略。当期望不用用户承担这部分成本时,那么就要求 ElaticQuota 忽略 overhead。在 v1.4.0 版本中,可以开启 featureGate
ElasticQuotaIgnorePodOverhead启用该功能。
4. CPU 归一化
随着 Kubernetes 集群中节点硬件的多样化,不同架构和代数的 CPU 之间性能差异显著。因此,即使 Pod 的 CPU 请求相同,实际获得的计算能力也可能大不相同,这可能导致资源浪费或应用性能下降。CPU 归一化的目标是通过标准化节点上可分配 CPU 的性能,来保证每个 CPU 单元在 Kubernetes 中提供的计算能力在异构节点间保持一致。
为了解决该问题,Koordinator 在 v1.4.0 版本中实现了一套支持 CPU 归一化机制,根据节点的资源放大策略,调整节点上可分配的 CPU 资源数量,使得集群中每个可分配的 CPU 通过缩放实现算力的基本一致。整体的架构如下图所示:

CPU 归一化分为两个步骤:
- CPU 性能评估,计算不同 CPU 的性能基准,可以参考工业级性能评测标准 SPEC CPU,这部分 Koordinator 项目未提供;
- 配置 CPU 归一化系数到 Koordinator,调度系统基于归一化系数来调度资源,这部分 Koordinator 提供;
将 CPU 归一化比例信息配置到 koord-manager 的 slo-controller-config 中,配置示例如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: slo-controller-config
namespace: koordinator-system
data:
cpu-normalization-config: |
{
"enable": true,
"ratioModel": {
"Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz": {
"baseRatio": 1.29,
"hyperThreadEnabledRatio": 0.82,
"turboEnabledRatio": 1.52,
"hyperThreadTurboEnabledRatio": 1.0
},
"Intel Xeon Platinum 8369B CPU @ 2.90GHz": {
"baseRatio": 1.69,
"hyperThreadEnabledRatio": 1.06,
"turboEnabledRatio": 1.91,
"hyperThreadTurboEnabledRatio": 1.20
}
}
}
# ...
对于配置了 CPU 归一化的节点,Koordinator 通过 Webhook 拦截 Kubelet 对 Node.Status.Allocatable 的更新以实现 CPU 资源的缩放,最终在节点上呈现出归一后的 CPU 资源可分配量。
5. 改进的重调度防护策略
Pod 迁移是一个复杂的过程,涉及审计、资源分配、应用启动等步骤,并且与应用升级、扩展场景以及集群管理员的资源操作和维护操作混合在一起。因此,如果同时有大量 Pods 正在进行迁移,可能会对系统的稳定性产生影响。此外,如果同一工作负载的许多Pods同时被迁移,也会影响应用的稳定性。此外,如果同时迁移多个作业中的 Pods,可能会造成惊群效应。因此,我们希望顺序处理每个作业中的 Pods。
Koordinator 在之前提供的 PodMigrationJob 功能中已经提供了一些防护策略来解决上述问题。在 v1.4.0 版本中,Koordinator 将之前的防护策略增强为仲裁机制。当有大量的 PodMigrationJob 可以被执行时,由仲裁器通过排序和筛选,来决定哪些 PodMigrationJob 可以得到执行。
排序过程如下:
- 根据迁移开始时间与当前时间的间隔进行排序,间隔越小,排名越高。
- 根据 PodMigrationJob 的 Pod 优先级进行排序,优先级越低,排名越高。
- 按照工作负载分散 Jobs,使得同一作业中的 PodMigrationJobs 靠近。
- 如果作业中已有 Pods 正在迁移,则该 PodMigrationJob 的排名更高。
筛选过程如下:
- 根据工作负载、节点、命名空间等对 PodMigrationJob 进行分组和筛选。
- 检查每个工作负载中正在运行状态的 PodMigrationJob 数量,达到一定阈值的将被排除。
- 检查每个工作负载中不可用副本的数量是否超出了最大不可用副本数,超出的将被排除。
- 检查目标 Pod 所在节点上正在迁移的 Pod 数量是否超过单个节点的最大迁移量,超出的将被排除。
6. 冷内存上报
为提升系统性能,内核一般尽可能不让应用程序请求的页面缓存空闲,而是尽可能将其分配给应用程序。虽然内核分配了这些内存,但是应用可能不再访问,这些内存被称为冷内存。
Koordinator 在 1.4 版本中引入冷内存上报功能,主要为未来冷内存回收功能打下基础。冷内存回收主要用于应对两个场景:
- 对于标准的 Kubernetes 集群,当节点内存水位过高时,突发的内存请求容器导致系统直接内存回收,操作系统的直接内存回收触发时会影响已经运行容器的性能,如果回收不及时极端场景可能触发整机 oom。保持节点内存资源的相对空闲,对提升运行时稳定性至关重要
- 在混部场景中,高优先级应用程序请求但未使用的资源可以被低优先级应用程序回收利用。对内存而言,操作系统未回收的内存,是不能被 Koordinator 调度系统看到的。为了提高混部资源效率,回收容器未使用的内存页面可以提高整机的资源利用效率
Koordlet 在 Collector Plugins 中添加了一个冷页面回收器,用于读取由 kidled(Anolis 内核)、kstaled(Google)或 DAMON(Amazon)导出的 cgroup 文件 memory.idle_stat。该文件包含页面缓存中的冷页面信息,并存在于 memory 的每个层次结构中。目前 koordlet 已经对接了 kidled 冷页面收集器并提供了其他冷页面收集器接口。
在收集冷页面信息后,冷页面回收器将把收集到的指标(例如节点、Pod 和容器的热页面使用量和冷页面大小)存到 metriccache 中,最后该数据会被上报到 NodeMetric CRD 中。
用户可以通过 NodeMetric 启用冷内存回收和配置冷内存收集策略,当前提供了 usageWithHotPageCache、usageWithoutPageCache 和 usageWithPageCache 三种策略,更多的细节详见社区设计文档。
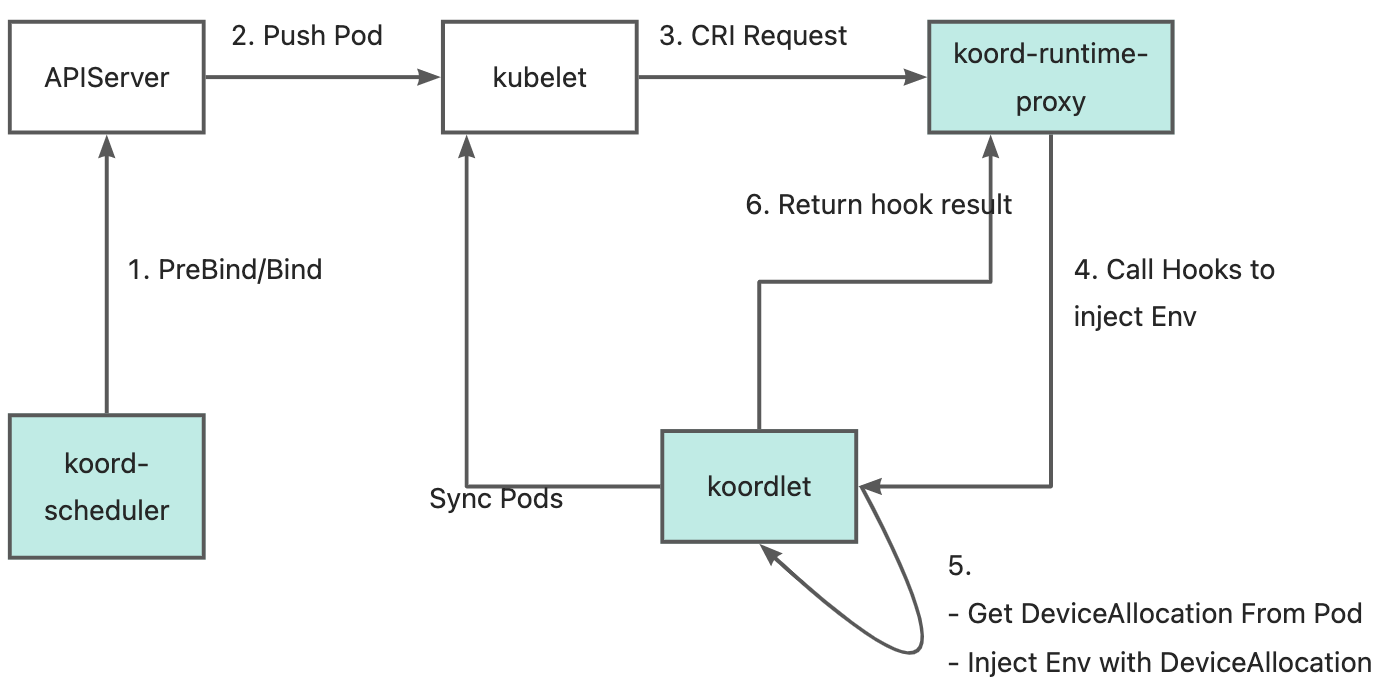
7. 非容器化应用的 QoS 管理
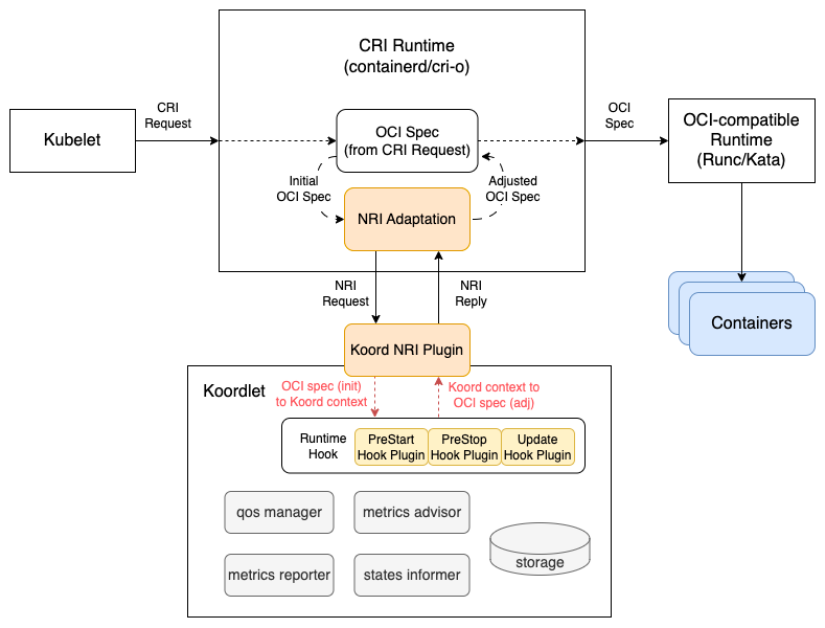
在企业容器化过程中,除了已经运行在 K8s 上的应用,可能还会存在一些非容器化的应用运行在主机上。为了更好兼容企业在容器化过程这一过渡态,Koordinator 开发了节点资源预留机制,可以未尚未容器化的应用预留资源并赋予特定的 QoS 特性。与 Kubelet 提供的资源预留配置不同,Koordinator 主要目标是解决这些非容器化应用与容器化应用运行时的 QoS 问题,整体的方案如下图所示:

目前,应用程序需要按照规范将进程启动到对应的 cgroup 中,Koordinator 未实现自动的 cgroup 搬迁工具。针对宿主机非容器化应用,支持 QoS 如下:
LS (Latency Sensitive)
- CPU QoS(Group Identity):应用按照规范将进程运行在 cgroup 的 cpu 子系统中,koordlet 根据 CPU QoS 的配置 resource-qos-config 为其设置 Group Identity 参数;
- CPUSet Allocation:应用按照规范将进程运行在 cgroup 的 cpu 子系统中,koordlet 将为其设置 cpu share pool 中的所有 CPU 核心。
BE (Best-effort)
- CPU QoS(Group Identity):应用按照规范将进程运行在 cgroup 的 cpu 子系统中,koordlet 根据 CPU QoS 的配置为其设置 Group Identity 参数。
关于宿主机应用 QoS 管理的详细设计,可以参考社区文档,后续我们将陆续增加其他QoS策略对宿主机应用的支持。
8. 其它特性
除了上述新特性和功能增强外,Koordinator 在 v1.4.0 版本还做了一些如下的 bugfix 和优化:
- RequiredCPUBindPolicy:精细化 CPU 编排支持 Required 的 CPU 绑定策略配置,表示严格按照指定的 CPU 绑定策略分配 CPU,否则调度失败。
- CICD:Koordinator 社区在 v1.4.0 提供了一套 e2e 测试的 Pipeline;提供了 ARM64 镜像。
- Batch 资源计算策略优化:支持了 maxUsageRequest 的计算策略,用于更保守地超卖高优资源;优化了节点上短时间大量 Pod 启停时,Batch allocatable 被低估的问题;完善了对 hostApplication、thirdparty allocatable、dangling pod used 等特殊情况的考虑。
- 其它:利用 libpfm4&perf group 优化 CPI 采集、SystemResourceCollector 支持自定义的过期时间配置、BE Pod 支持根据 evictByAllocatable 策略计算CPU 满足度、Koordlet CPUSetAllocator 修复了对于 LS 和 None Qos 的 Pod 的过滤逻辑、RDT 资源控制支持获得 sandbox 容器的 task IDs 等
通过 v1.4.0 Release 页面,可以看到更多包含在 v1.4.0 版本的新增功能。
未来计划
在接下来的版本中,Koordinator 目前规划了以下功能:
- Core Scheduling。在运行时侧,Koordinator 开始探索下一代 CPU QoS 能力,通过利用 Linux Core Scheduling 等内核机制,增强的物理核维度的资源隔离,降低混部的安全性风险,相关工作详见 Issue #1728。
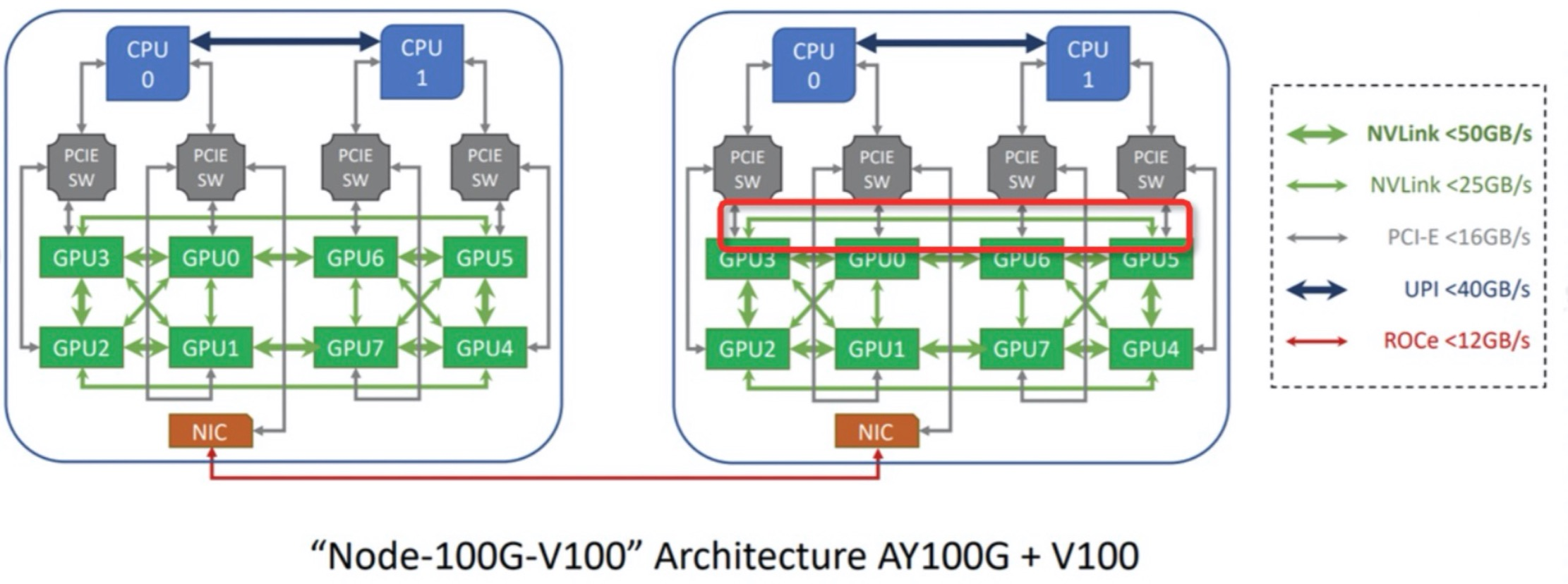
- 设备联合分配。在 AI 大模型分布式训练场景中,不同机器 GPU 之间通常需要通过高性能网卡相互通信,且 GPU 和高性能网卡就近分配的时候性能更好。Koordinator 正在推进支持多种异构资源的联合分配,目前已经在协议上和调度器分配逻辑上支持联合分配;单机侧关于网卡资源的上报逻辑正在探索中。
更多信息,敬请关注 Milestone v1.5.0。
结语
最后,我们十分感谢 Koordinator 社区的所有贡献者和用户,是您们的积极参与和宝贵意见让 Koordinator 不断进步。我们期待您继续提供反馈,并欢迎新的贡献者加入我们的行列。