
背景
Koordinator 旨在为用户提供完整的混部工作负载编排、混部资源调度、混部资源隔离及性能调优解决方案,帮助用户提高延迟敏感服务的运行性能,挖掘空闲节点资源并分配给真正有需要的计算任务,从而提高全局的资源利用效率。
从 2022 年 4 月发布以来,Koordinator 迄今一共迭代发布了 9 个版本。项目经历的大半年发展过程中,社区吸纳了包括阿里巴巴、小米、小红书、爱奇艺、360、有赞 等在内的大量优秀工程师,贡献了众多的想法、代码和场景,一起推动 Koordinator 项目的成熟。
今天,很高兴的宣布 Koordinator v1.1 正式发布,它包含了负载感知调度/重调度、cgroup v2 支持、干扰检测指标采集,以及其他一系列优化点。接下来我们就针对这些新增特性做深入解读与说明。
版本特性深入解读
负载感知调度
支持按工作负载类型统计和均衡负载水位
Koordinator v1.0 及之前的版本,提供了负载感知调度提供基本的利用率阈值过滤保护高负载水位的节点继续恶化影响工作负载的运行时质量,以及通过预估机制解决解决冷节点过载的情况。已有的负载感知调度能解决很多常见场景的问题。但负载感知调度作为一种优化手段,还有比较多的场景是需要完善的。
目前的负载感知调度主要解决了集群内整机维度的负载均衡效果,但有可能出现一些特殊的情况:节点部署了不少离线Pod运行,拉高了整机的利用率,但在线应用工作负载的整体利用率偏低。这个时候如果有新的在线Pod,且整个集群内的资源比较紧张时,会有如下的问题:
- 有可能因为整机利用率超过整机安全阈值导致无法调度到这个节点上的;
- 还可能出现一个节点的利用率虽然相对比较低,但上面跑的全是在线应用率,从在线应用角度看,利用率已经偏高了,但按照当前的调度策略,还会继续调度这个Pod上来,导致该节点堆积了大量的在线应用,整体的运行效果并不好。
在 Koordinator v1.1 中,koord-scheduler 支持感知工作负载类型,区分不同的水位和策略进行调度。
在 Filter 阶段,新增 threshold 配置 prodUsageThresholds,表示在线应用的安全阈值,默认为空。如果当前调度的 Pod 是 Prod 类型,koord-scheduler 会从当前节点的 NodeMetric 中统计所有在线应用的利用率之和,如果超过了 prodUsageThresholds 就过滤掉该节点;如果是离线 Pod,或者没有配置 prodUsageThresholds,保持原有的逻辑,按整机利用率处理。
在 Score 阶段,新增开关 scoreAccordingProdUsage 表示是否按 Prod 类型的利用率打分均衡。默认不启用。当开启后,且当前 Pod 是 Prod 类型的话,koord-scheduler 在预估算法中只处理 Prod 类型的 Pod,并对 NodeMetrics 中记录的其他的未使用预估机制处理的在线应用的 Pod 的当前利用率值进行求和,求和后的值参与最终的打分。如果没有开启 scoreAccordingProdUsage,或者是离线Pod,保持原有逻辑,按整机利用率处理。
支持按百分位数利用率均衡
Koordinator v1.0及以前的版本都是按照 koordlet 上报的平均利用率数据进行过滤和打分。但平均值隐藏了比较多的信息,因此在 Koordinator v1.1 中 koordlet 新增了根据百分位数统计的利用率聚合数据。调度器侧也跟着做了相应的适配。
更改调度器的 LoadAware 插件的配置,aggregated 表示按照百分位数聚合数据进行打分和过滤。aggregated.usageThresholds 表示过滤时的水位阈值;aggregated.usageAggregationType 表示过滤阶段要使用的百分位数类型,支持 avg,p99, p95, p90 和 p50;aggregated.usageAggregatedDuration 表示过滤阶段期望使用的聚合周期,如果不配置,调度器将使用 NodeMetrics 中上报的最大周期的数据;aggregated.scoreAggregationType 表示在打分阶段期望使用的百分位数类型;aggregated.scoreAggregatedDuration 表示打分阶段期望使用的聚合周期,如果不配置,调度器将使用 NodeMetrics 中上报的最大周期的数据。
在 Filter 阶段,如果配置了 aggregated.usageThresholds 以及对应的聚合类型,调度器将按该百分位数统计值进行过滤;
在 Score 阶段,如果配置了 aggregated.scoreAggregationType,调度器将会按该百分位数统计值打分;目前暂时不支持 Prod Pod 使用百分位数过滤。
负载感知重调度
Koordinator 在过去的几个版本中,持续的演进重调度器,先后了开源完整的框架,加强了安全性,避免因过度驱逐 Pod 影响在线应用的稳定性。这也影响了重调度功能的进展,过去 Koordinator 暂时没有太多力量建设重调度能力。这一情况将会得到改变。
Koordinator v1.1 中我们新增了负载感知重调度功能。新的插件称为 LowNodeLoad,该插件配合着调度器的负载感知调度能力,可以形成一个闭环,调度器的负载感知调度在调度时刻决策选择最优节点,但随着时间和集群环境以及工作负载面对的流量/请求的变化时,负载感知重调度可以介入进来,帮助优化负载水位超过安全阈值的节点。 LowNodeLoad 与 K8s descheduler 的插件 LowNodeUtilization 不同的是,LowNodeLoad是根据节点真实利用率的情况决策重调度,而 LowNodeUtilization 是根据资源分配率决策重调度。
LowNodeLoad 插件有两个最重要的参数,分别是 highThresholds 和 lowThresholds:
highThresholds表示负载水位的警戒阈值,超过该阈值的节点上的Pod将参与重调度;lowThresholds表示负载水位的安全水位。低于该阈值的节点上的Pod不会被重调度。
以下图为例,lowThresholds 为45%,highThresholds 为 70%,那么低于 45% 的节点是安全的,因为水位已经很低了;高于45%,但是低于 70%的是区间是我们期望的负载水位范围;高于70%的节点就不安全了,应该把超过70%的这部分(假设当前节点A的负载水位是85%),那么 85% - 70% = 15% 的负载降低,筛选 Pod 后执行迁移。
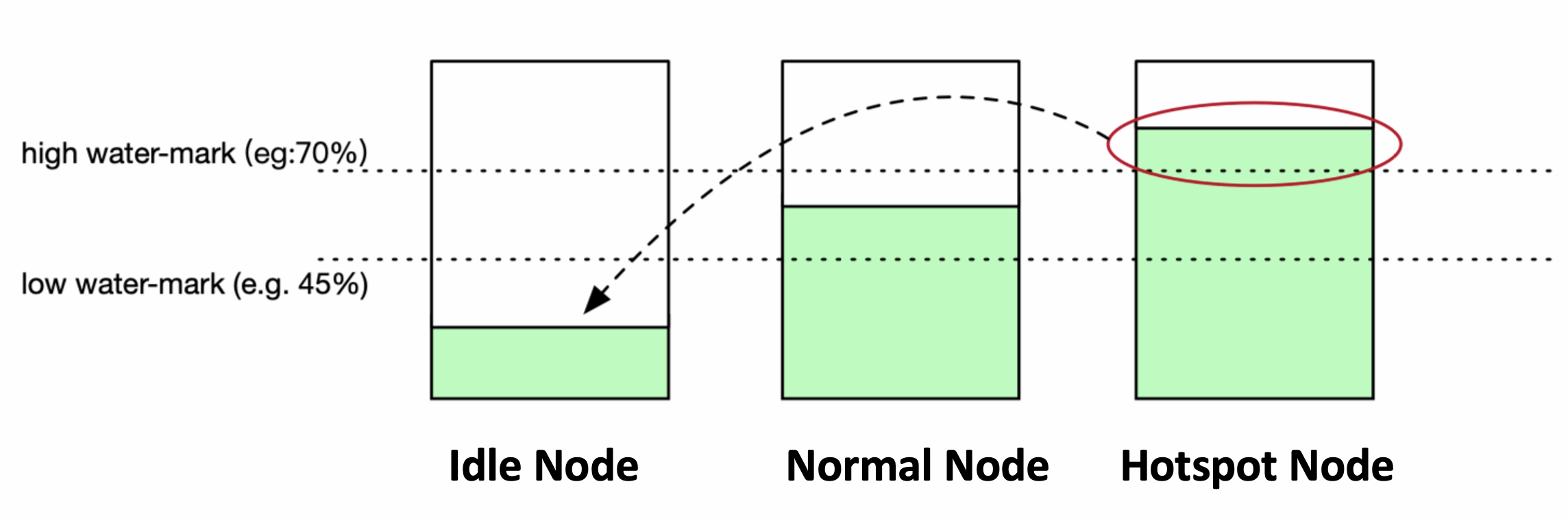
迁移时,还要考虑到低于 45% 的这部分节点是我们重调度后要承载新Pod的节点,我们需要确保迁移的Pod的负载总量不会超过这些低负载节点的承载上限。这个承载上限即是 highThresholds - 节点当前负载,假设节点B的负载水位是20%,那么 70%-20% = 50%,这50%就是可以承载的容量了。因此迁移时每驱逐一个 Pod,这个承载容量就应该扣掉当前重调度 Pod 的当前负载或者预估负载或者画像值(这部分值与负载调度里的值对应)。这样就可以确保不会多迁移。
如果一个集群总是可能会出现某些节点的负载就是比较高,而且数量并不多,这个时候如果频繁的重调度这些节点,也会带来安全隐患,因此可以让用户按需设置 numberOfNodes。
另外,LowNodeLoad 识别出超过阈值的节点后会筛选 Pod,当筛选 Pod 时,可以配置要支持或者过滤的 namespace,或者配置 pod selector 筛选,也可以配置 nodeFit 检查每个备选 Pod 对应的 Node Affinity/Node Selector/Toleration 是否有与之匹配的 Node,如果没有的话,这种节点也会被忽略。当然可以考虑不启用这个能力,通过配置 nodeFit 为 false 后即可禁用,此时完全由底层的 MigrationController 通过 Koordinator Reservation 预留资源;
当筛选出 Pod 后,会对这些 Pod 进行排序。会依靠Koordinator QoSClass、Kubernetes QoSClass、Priority、用量和创建时间等多个维度排序。
cgroup v2 支持
背景
Koordinator 中众多单机 QoS 能力和资源压制/弹性策略构建在 Linux Control Group (cgroups) 机制上,比如 CPU QoS (cpu)、Memory QoS (memory)、CPU Burst (cpu)、CPU Suppress (cpu, cpuset),koordlet 组件可以通过 cgroups (v1) 限制容器可用资源的时间片、权重、优先级、拓扑等属性。Linux 高版本内核也在持续增强和迭代了 cgroups 机制,带来了 cgroups v2 机制,统一 cgroups 目录结构,改善 v1 中不同 subsystem/cgroup controller 之间的协作,并进一步增强了部分子系统的资源管理和监控能力。Kubernetes 自 1.25 起将 cgroups v2 作为 GA (general availability) 特性,在 Kubelet 中启用该特性进行容器的资源管理,在统一的 cgroups 层次下设置容器的资源隔离参数,支持 MemoryQoS 的增强特性。

在 Koordinator v1.1 中,单机组件 koordlet 新增对 cgroups v2 的支持,包括如下工作:
- 重构了 Resource Executor 模块,以统一相同或近似的 cgroup 接口在 v1 和 v2 不同版本上的文件操作,便于 koordlet 特性兼容 cgroups v2 和合并读写冲突。
- 在当前已开放的单机特性中适配 cgroups v2,采用新的 Resource Executor 模块替换 cgroup 操作,优化不同系统环境下的报错日志。
Koordinator v1.1 中大部分 koordlet 特性已经兼容 cgroups v2,包括但不限于:
- 资源利用率采集
- 动态资源超卖
- Batch 资源隔离(BatchResource,废弃BECgroupReconcile)
- CPU QoS(GroupIdentity)
- Memory QoS(CgroupReconcile)
- CPU 动态压制(BECPUSuppress)
- 内存驱逐(BEMemoryEvict)
- CPU Burst(CPUBurst)
- L3 Cache 及内存带宽隔离(RdtResctrl)
遗留的未兼容特性如 PSICollector 将在接下来的 v1.2 版本中进行适配,可以跟进 issue#407 获取最新进展。接下来的 Koordinator 版本中也将逐渐引入更多 cgroups v2 的增强功能,敬请期待。
使用 cgroups v2
在 Koordinator v1.1 中,koordlet 对 cgroups v2 的适配对上层功能配置透明,除了被废弃特性的 feature-gate 以外,您无需变动 ConfigMap slo-controller-config 和其他 feature-gate 配置。当 koordlet 运行在启用 cgroups v2 的节点上时,相应单机特性将自动切换到 cgroups-v2 系统接口进行操作。
此外,cgroups v2 是 Linux 高版本内核(建议 >=5.8)的特性,对系统内核版本和 Kubernetes 版本有一定依赖。建议采用默认启用 cgroups v2 的 Linux 发行版以及 Kubernetes v1.24 以上版本。
更多关于如何启用 cgroups v2 的说明,请参照 Kubernetes 社区文档。
干扰检测指标采集
在真实的生产环境下,单机的运行时状态是一个“混沌系统”,资源竞争产生的应用干扰无法绝对避免。Koordinator 正在建立干扰检测与优化的能力,通过提取应用运行状态的指标,进行实时的分析和检测,在发现干扰后对目标应用和干扰源采取更具针对性的策略。
当前 Koordinator 已经实现了一系列 Performance Collector,在单机侧采集与应用运行状态高相关性的底层指标,并通过 Prometheus 暴露出来,为干扰检测能力和集群应用调度提供支持。
指标采集
Performance Collector 由多个 feature-gate 进行控制,Koordinator 目前提供以下几个指标采集器:
CPICollector:用于控制 CPI 指标采集器。CPI:Cycles Per Instruction。指令在计算机中执行所需要的平均时钟周期数。CPI 采集器基于 Cycles 和 Instructions 这两个 Kernel PMU(Performance Monitoring Unit)事件以及 perf_event_open(2) 系统调用实现。PSICollector:用于控制 PSI 指标采集器。PSI:Pressure Stall Information。表示容器在采集时间间隔内,因为等待 cpu、内存、IO 资源分配而阻塞的任务数。使用 PSI 采集器前,需要在 Anolis OS 中开启 PSI 功能,您可以参考文档获取开启方法。
Performance Collector 目前是默认关闭的。您可以通过修改 Koordlet 的 feature-gates 项来使用它,此项修改不会影响其他 feature-gate
kubectl edit ds koordlet -n koordinator-system
...
spec:
...
spec:
containers:
- args:
...
# modify here
# - -feature-gates=BECPUEvict=true,BEMemoryEvict=true,CgroupReconcile=true,Accelerators=true
- -feature-gates=BECPUEvict=true,BEMemoryEvict=true,CgroupReconcile=true,Accelerators=true,CPICollector=true,PSICollector=true
ServiceMonitor
v1.1.0 版本的 Koordinator 为 Koordlet 增加了 ServiceMonitor 的能力,将所采集指标通过 Prometheus 暴露出来,用户可基于此能力采集相应指标进行应用系统的分析与管理。
ServiceMonitor 由 Prometheus 引入,故在 helm chart 中设置默认不开启安装,可以通过以下命令安装ServiceMonitor:
helm install koordinator https://... --set koordlet.enableServiceMonitor=true
部署后可在 Prometheus UI 找到该 Targets。
# HELP koordlet_container_cpi Container cpi collected by koordlet
# TYPE koordlet_container_cpi gauge
koordlet_container_cpi{container_id="containerd://498de02ddd3ad7c901b3c80f96c57db5b3ed9a817dbfab9d16b18be7e7d2d047",container_name="koordlet",cpi_field="cycles",node="your-node-name",pod_name="koordlet-x8g2j",pod_namespace="koordinator-system",pod_uid="3440fb9c-423b-48e9-8850-06a6c50f633d"} 2.228107503e+09
koordlet_container_cpi{container_id="containerd://498de02ddd3ad7c901b3c80f96c57db5b3ed9a817dbfab9d16b18be7e7d2d047",container_name="koordlet",cpi_field="instructions",node="your-node-name",pod_name="koordlet-x8g2j",pod_namespace="koordinator-system",pod_uid="3440fb9c-423b-48e9-8850-06a6c50f633d"} 4.1456092e+09
可以期待的是,Koordinator 干扰检测的能力在更复杂的真实场景下还需要更多检测指标的补充,后续将在如内存、磁盘 IO 等其他诸多资源的指标采集建设方面持续发力。
其他更新点
通过 v1.1 release 页面,可以看到更多版本所包含的新增功能。