Resource Model
Colocation is a set of resource scheduling solutions for the fine grained orchestration of latency sensitive workloads with the big data computing workloads. It needs to solve two major problems:
- How to schedule resources for latency sensitive workloads to meet performance and long-tail latency requirements, the key points are resource scheduling strategies and QoS-aware strategies.
- How to schedule and arrange big data computing workloads to meet the needs of jobs for computing resources at a lower cost. The key is how to achieve reasonable resource overcommitment and QoS protection in extreme abnormal scenarios.
Definition
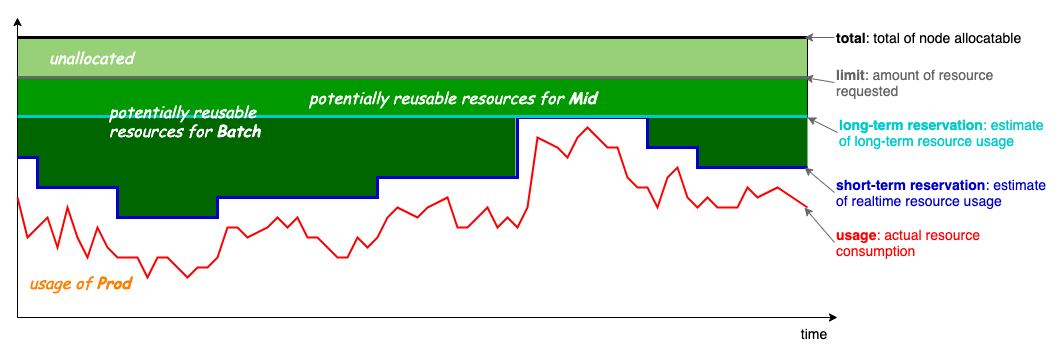
The above figure is the Koordinator colocation resource model, the basic idea is to use those allocated but unused resources to run low-priority pods. Four lines as shown:
- limit: gray, the amount of resources requested by the high-priority Pod, corresponding to the Pod request of kubernetes.
- usage: red, the amount of resources actually used by the Pod, the horizontal axis is the time line, and the red line is the fluctuation curve of the Pod load over time.
- short-term reservation: dark blue, which is based on the resource usage of usage in the past (shorter) period, and the estimation of its resource usage in the future period of time. The difference between reservation and limit is the allocated unused ( resources that will not be used in the future) can be used to run short-lived batch pods.
- long-term reservation: light blue, similar to short-term reservation but the estimated historical period of use is longer. The resources from reservation to limit can be used for pods with a longer life cycle, compared with the predicted value of short-term, fewer resources available but more stability.
The entire co-located resource scheduling building is constructed based on the resource model shown above, which can not only meet the resource requirements of various workloads, but also make full use of the idle resources of the cluster.
SLO Description
A Pod resource SLO running in a cluster consists of two concepts, Priority and QoS:
- Priority, the resource priority, represents the priority of the request being scheduled. Typically, Priority affects the relative position of the request in the scheduler pending queue.
- QoS, which represents the quality of service when the Pod runs. Such as cgroups cpu shares, cfs quota, LLC, memory bandwidth, OOM Priority, etc.
It should be noted that Priority and QoS are two-dimensional concepts, but in real business scenarios, there will be some constraints between the two (not all combinations are legal).
What's Next
Here are some recommended next steps: