Background
AI and batch workloads continue to drive the evolution of Kubernetes scheduling. As clusters grow larger and workloads become more diverse, users demand richer queueing semantics, more accurate resource reservation, deeper observability, and unified management across increasingly heterogeneous hardware.
Since its open-source release in April 2022, Koordinator has delivered 16 major versions, providing an end-to-end solution for workload orchestration, co-location, fine-grained scheduling, isolation, and performance optimization. We sincerely thank engineers from Alibaba, Ant Group, Intel, XiaoHongShu, Xiaomi, iQIYI, 360, YouZan, PITS Global Data Recovery Services, Quwan, meiyapico, dewu, Asiainfo, CaoCao Mobility, i-Tudou, NVIDIA, NIO, Mammotion, Zhongrui Group, Heshan Dehao, and many other organizations for their continuous contributions.
Today, we are excited to announce the release of Koordinator v1.8.0. This release introduces Koord-Queue, a native Kubernetes job queueing system built for the Koordinator ecosystem; enhances Resource Reservation with Pre-Allocation (cluster mode and multiple pre-allocated pods); adds the Scheduling Hint internal protocol to enable cooperative scheduling decisions; expands heterogeneous device support to MetaX GPU/sGPU and Huawei Ascend 300I Duo; ships new Grafana Dashboards for scheduler and descheduler; and upgrades the platform baseline to Kubernetes 1.35.
Key Features
1. Koord-Queue: Native Job-Level Queueing for Kubernetes
Multi-tenant AI/ML and batch clusters require job-level queueing, admission control, and resource fairness on top of Pod-level scheduling. Koordinator v1.8.0 introduces Koord-Queue, a new component purpose-built for these scenarios.
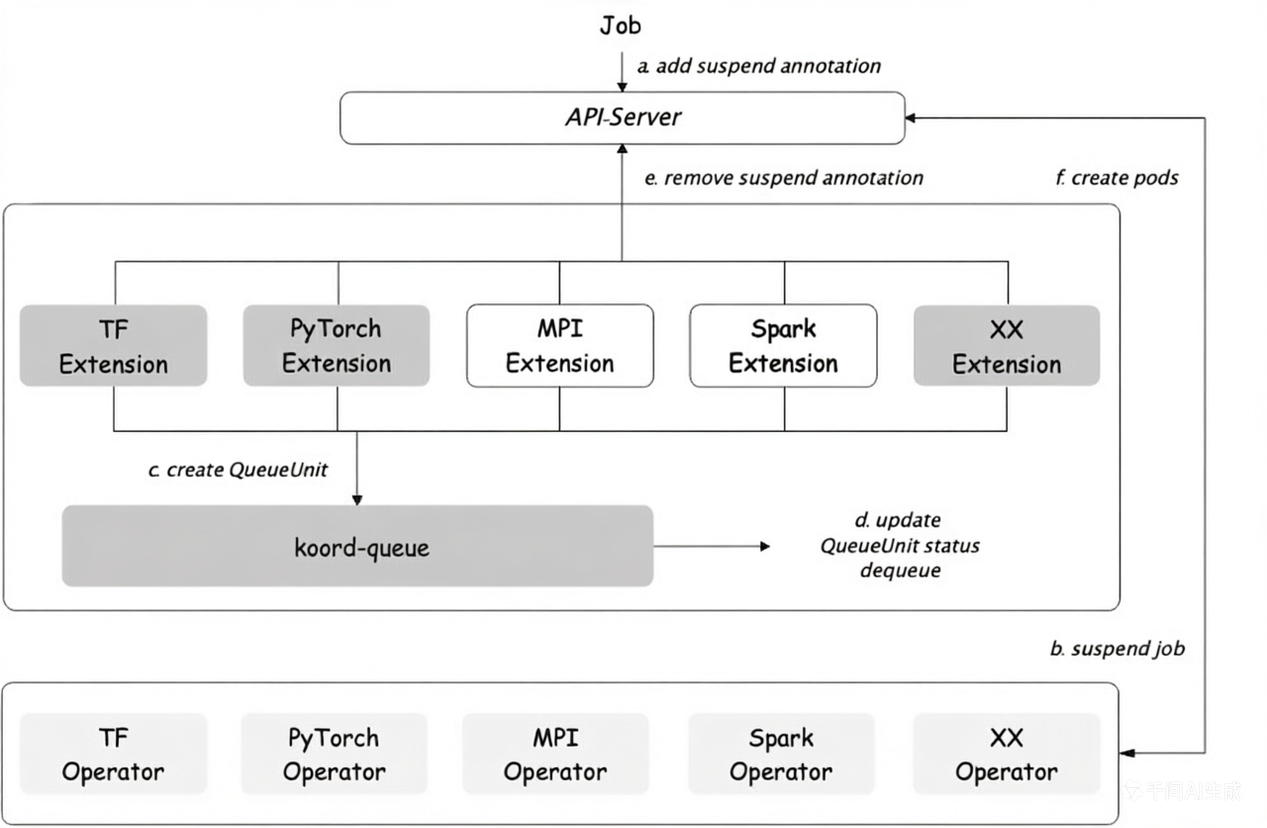
Koord-Queue provides:
- Job-level queueing: Manages queue units representing whole jobs (TFJob, PyTorchJob, MPIJob, Spark, Argo Workflow, Ray, native Kubernetes Jobs) rather than individual pods.
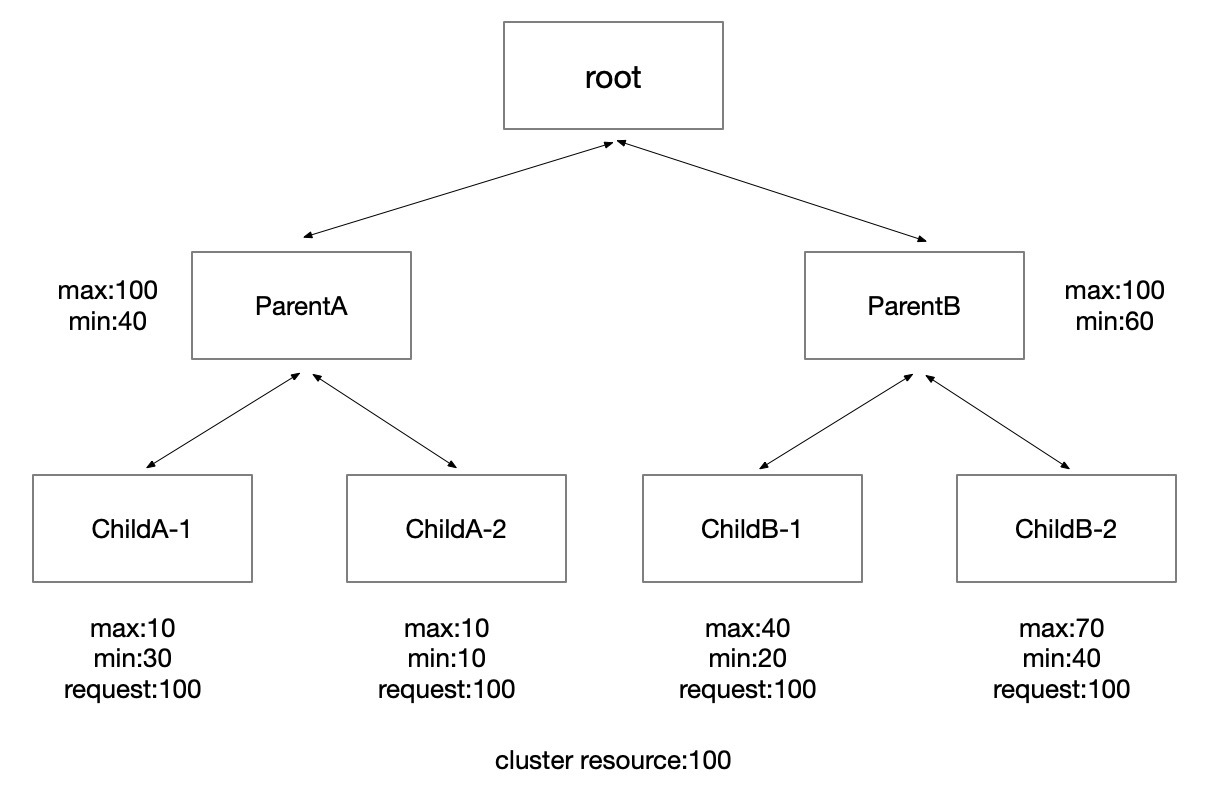
- Deep ElasticQuota integration: Integrates with Koordinator's
ElasticQuotaCRD (scheduling.sigs.k8s.io/v1alpha1) for elastic borrowing, min/max guarantees, and hierarchical fair-sharing. - Pluggable queueing policies: Supports both
Priority(priority + creation-time ordering) andBlock(strict blocking) policies per queue. - Pre-scheduling admission: Reduces scheduler pressure by gating jobs before they hit the Pod scheduler, through a plugin framework with
MultiQueueSort,QueueSort,QueueUnitMapping,Filter, andReserveextension points. - Admission check framework (WIP): API-compatible with Kueue's
AdmissionCheck, enabling custom gates such as quota validation, capacity checks, or external approvals.
Example Queue with ElasticQuota integration:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Queue
metadata:
name: team-a-queue
namespace: koord-queue
spec:
queuePolicy: Priority
priority: 100
Koord-Queue is deployed separately via Helm:
helm install koord-queue koordinator-sh/koord-queue --version 1.8.0 \
--namespace koord-queue
For details, please see the Koord-Queue design document and the Queue Management user manual.
2. Resource Reservation: Pre-Allocation with Cluster Mode and Multiple Pods
In v1.8.0, Koordinator's Reservation CRD is extended with Pre-Allocation, enabling users to pre-allocate node resources for future demands even when the resources are not currently allocatable. This is particularly useful for inference orchestration, rolling upgrades, and priority-based capacity planning.
Key enhancements:
Clusterpre-allocation mode viapreAllocationPolicy.mode: Cluster: instead of matching pre-allocatable pods through the Reservation's Owner matchers (theDefaultmode), the scheduler identifies candidate pods by cluster-wide label/annotation selectors. Pods marked with the labelpod.koordinator.sh/is-pre-allocatable: "true"become pre-allocatable, which is especially useful in multi-tenant clusters where pre-allocatable pods may belong to different owners and should be managed centrally.- Multiple pre-allocated pods via
preAllocationPolicy.enableMultiple: true: when disabled, only a single pod can be pre-allocated against the Reservation; when enabled, multiple pods can jointly satisfy the reservation's resource requirements — useful when no single pod can consume all the reserved resources due to resource fragmentation. - Pre-allocation priority through the
pod.koordinator.sh/pre-allocatable-priorityannotation (numeric string, higher = higher priority), giving fine-grained control over which candidate pods are picked first. - Integration with NodeNUMAResource and DeviceShare, so pre-allocation reserves CPUs, NUMA nodes, and GPU devices in a consistent way with regular scheduling.
Example snippet enabling Cluster mode and multi-pod pre-allocation:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Reservation
metadata:
name: pre-alloc-cluster
spec:
preAllocation: true
preAllocationPolicy:
mode: Cluster
enableMultiple: true
For more information, please see Resource Reservation.
3. Scheduling Hint: Cooperative Scheduling Between Components
Koordinator v1.8.0 introduces Scheduling Hint, an internal protocol that allows scheduling-related components (for example, Koord-Queue or network-topology-aware pre-schedulers) to pass hints to koord-scheduler for more efficient decisions without overriding its authority.
The first supported hint is preferredNodeNames, a list of candidate nodes the scheduler tries first before falling back to normal scheduling:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-hint
annotations:
internal.scheduling.koordinator.sh/scheduling-hint: '{"preferredNodeNames": ["node-1", "node-2"]}'
spec:
schedulerName: koord-scheduler
containers:
- name: app
image: nginx
Unlike status.nominatedNodeName, Scheduling Hint:
- Accepts a list of nodes instead of a single node, providing natural fallback options.
- Does not consume node capacity in the Assume phase, leaving other pods unaffected.
- Falls back gracefully to normal scheduling when preferred nodes don't work.
For more information, please see Scheduling Hint.
4. Expanded Heterogeneous Device Support: MetaX GPU/sGPU and Huawei Ascend 300I Duo
Building on the Ascend NPU and Cambricon MLU support added in v1.7.0, Koordinator v1.8.0 further extends the unified device scheduling framework:
- MetaX GPU/sGPU support through
koord-device-daemonand fine-grained device scheduling. MetaX full cards and sGPU virtual slices are reported asDeviceCRs with standardkoordinator.sh/gpu-*resources, allowing scheduling policies (partition-aware, topology-aware, GPU-Share) to work consistently across vendors. - Huawei Ascend 300I Duo adaptation in the device-scheduling DP adapter, complementing the existing 910B family and providing inference-optimized scheduling for Ascend 300I Duo cards.
- NVIDIA GPU health condition reporting, giving upstream systems richer signals about node-level GPU health.
Example Pod requesting a MetaX virtual GPU (sGPU) with a specified compute percentage, GPU memory, and QoS policy:
apiVersion: v1
kind: Pod
metadata:
labels:
app: demo-sleep
name: test-metax-sgpu
namespace: default
annotations:
metax-tech.com/sgpu-qos-policy: "fixed-share" # fixed-share/best-effort/burst-share
spec:
containers:
- command:
- sleep
- infinity
image: ubuntu:22.04
imagePullPolicy: IfNotPresent
name: demo-sleep
resources:
limits:
cpu: "32"
memory: 64Gi
koordinator.sh/gpu.shared: "1"
koordinator.sh/gpu-memory: "1Gi"
koordinator.sh/gpu-core: "10"
metax-tech.com/sgpu: "1"
requests:
cpu: "32"
memory: 64Gi
koordinator.sh/gpu.shared: "1"
koordinator.sh/gpu-memory: "1Gi"
koordinator.sh/gpu-core: "10"
metax-tech.com/sgpu: "1"
For more information, please see Device Scheduling – Metax GPU and Fine-Grained Device Scheduling.
5. Descheduling with Custom Priority
v1.8.0 introduces a new CustomPriority balance plugin in koord-descheduler that deschedules Pods according to a user-defined node priority order. Nodes are split into multiple priority tiers based on business semantics — for example pay-as-you-go vs. pay-by-year-or-month, shared vs. dedicated pools, or spot vs. on-demand instances. When a lower-priority tier has enough capacity to accommodate Pods running on a higher-priority tier, the descheduler proactively evicts those Pods so they can be rescheduled onto the cheaper (or more reclaimable) pool.
Typical use cases:
- Cost optimization: migrate workloads from pay-as-you-go nodes onto pay-by-year-or-month nodes.
- Resource consolidation: gradually shift load from one type of node to another so that the source nodes can be safely scaled down, maintained, or returned.
- Tiered pools: enforce a strict ordering between multiple node pools and let workloads “sink” toward the lower tiers over time.
Each descheduling cycle the plugin executes the following steps:
- Group all nodes in the cluster according to the order defined in
evictionOrder. A node is assigned to the first matching priority tier only. - Starting from the highest-priority tier (the one listed first), use it as the source pool and treat all subsequent lower-priority tiers together as the target pool candidates.
- For every Pod on a source node, apply the namespace /
podSelector/ Evictor filters and sort the candidate Pods to be evicted by ascending CPU and Memory request. - Run the eviction strategy according to
mode:BestEffort(default — evict any individual Pod as soon as a single target node can accommodate it) orDrainNode(only evict Pods on a source node when all candidate Pods on that node can be placed onto target-pool nodes, optionally cordoning it viaautoCordon). - Actual Pod eviction is performed asynchronously by the
Evictor, which honors all rate-limit and safety mechanisms.
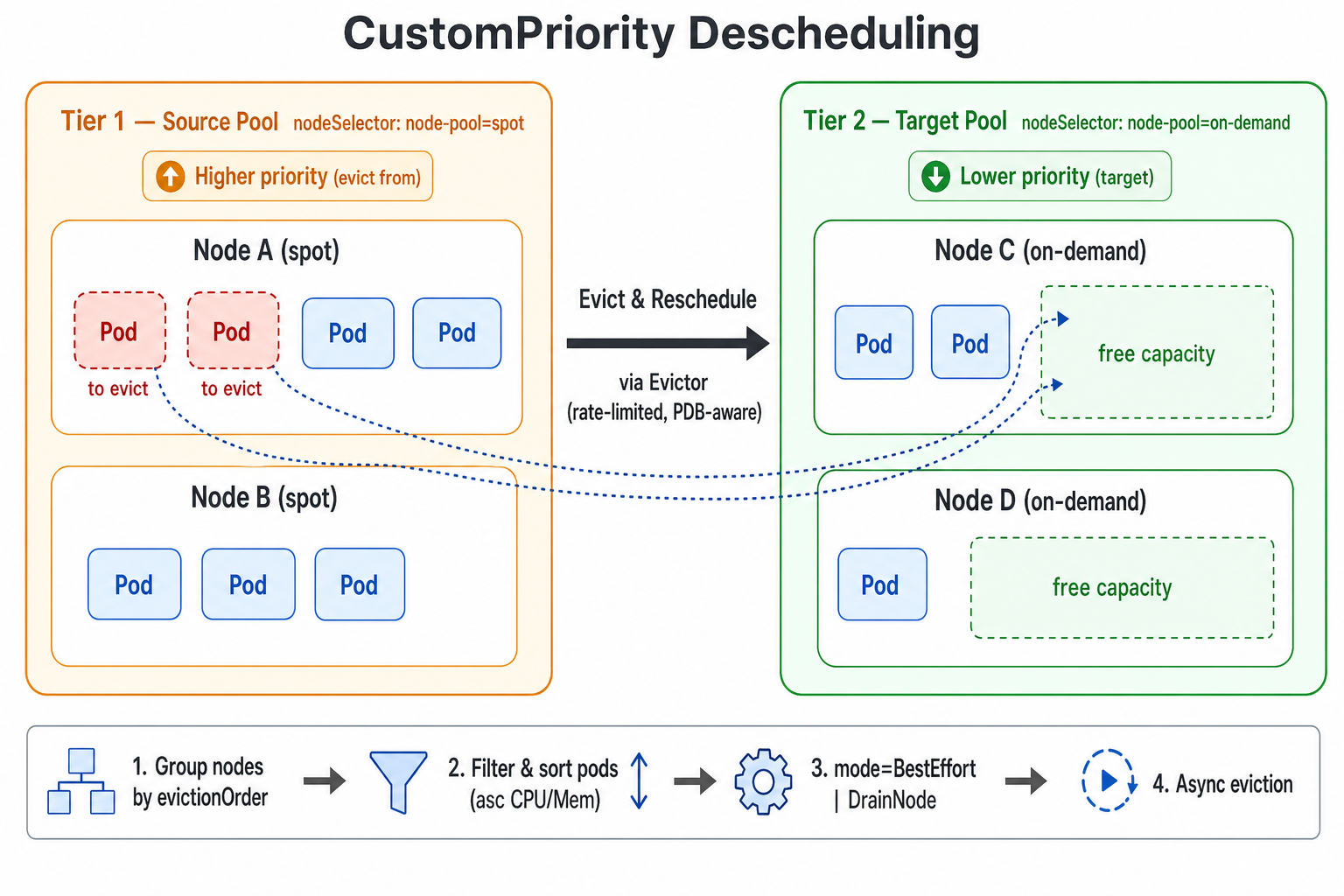
For more information, please see Descheduling with Custom Priority.
6. Observability: Grafana Dashboards for Scheduler and Descheduler
v1.8.0 ships a set of curated Grafana dashboards for koord-scheduler and koord-descheduler, covering scheduling throughput, queue latency, plugin latency, preemption activity, and descheduler evictions. Combined with the PodMonitor parameters introduced in the Helm chart, users can now light up production-grade observability with a single Helm flag:
helm install koordinator koordinator-sh/koordinator --version 1.8.0 \
--set scheduler.monitorEnabled=true \
--set descheduler.monitorEnabled=true
Example dashboards:
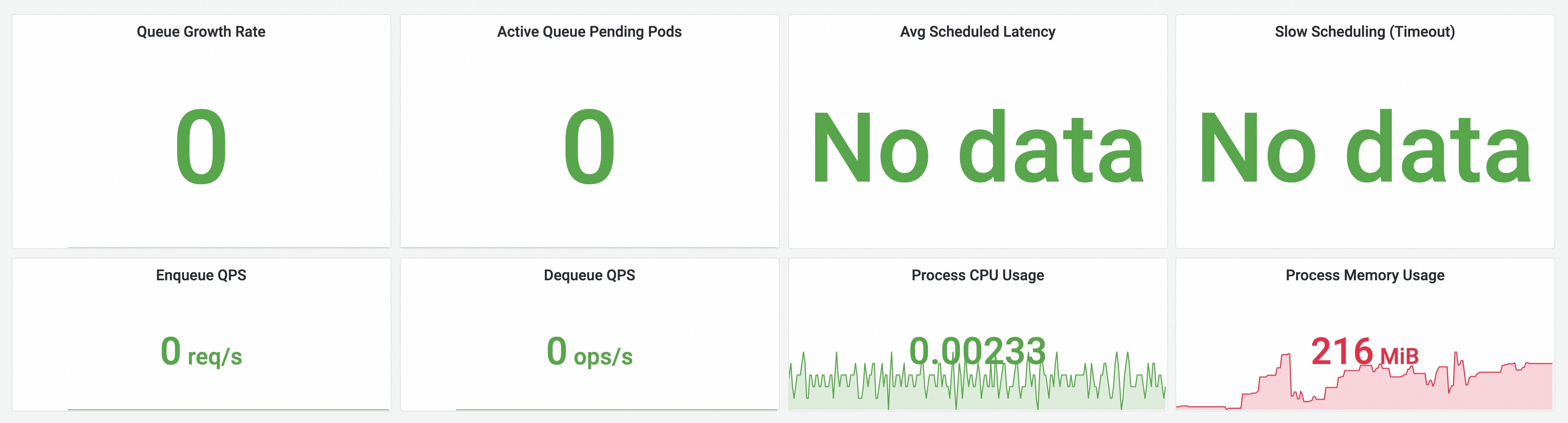
Scheduler Basic Summary — queue growth, pending pods, scheduling latency, enqueue/dequeue QPS, and scheduler process resource usage, providing an at-a-glance view of koord-scheduler health and throughput.
Descheduler Eviction Overview — cumulative and real-time eviction counts, success/failure rates, and current eviction rate, giving a quick snapshot of koord-descheduler activity.

For more information, please see Scheduling Monitoring and Descheduling Monitoring.
7. Platform and Compatibility
v1.8.0 brings a number of platform-wide improvements:
- Upgrade to Kubernetes 1.35.2, including controller-gen
v0.20.0andk8s.io/utils/ptrmigration. v1.8 formally supports Kubernetes 1.24, 1.28, and 1.35. Kubernetes 1.22 and 1.20 remain only partially supported: certain Koordinator components have moved to newer Kubernetes APIs that do not exist on those older clusters, so they no longer work there, while core co-location, QoS, and scheduling capabilities continue to function. For details, please see Kubernetes Compatibility. - Multi-scheduler / multi-profile hardening: extensive refinement of reservation, coscheduling, PreBind, PreBindReservation, ForgetPod, and framework-extender flows so that koord-scheduler runs reliably alongside other schedulers or in backup-scheduler setups.
- Protobuf for native resources:
kubeclientsnow uses protobuf for core resources, reducing API Server CPU footprint. - NRI upgrade to 0.11.0 and refined NRI server in koordlet.
- Koordlet improvements: static reserved mode for mid resource, allocatable-based eviction, BE CPU-suppress fix when BE pods exist, container-level cfs_quota unbinding fix, cpuset share-pool metric, GPU init-failure handling when a GPU is lost.
- Descheduler improvements: skip eviction gates support, anomaly condition fixes, nodePool inheritance of top-level defaults, raw-allocatable based thresholds in
LowNodeLoad(see section 5 above for the newCustomPriorityplugin).
Contributors
Koordinator is an open-source community. Thanks to all long-time maintainers and first-time contributors. We welcome more developers to join the Koordinator community.
New Contributors
- @IULeen made their first contribution in #2595
- @lujinda made their first contribution in #2679
- @hunshcn made their first contribution in #2707
- @summingyu made their first contribution in #2711
- @ikukaku made their first contribution in #2684
- @AutuSnow made their first contribution in #2767
- @PixelPixel00 made their first contribution in #2802
- @106umao made their first contribution in #2819
- @manukasvi made their first contribution in #2815
- @aviralgarg05 made their first contribution in #2838
Future Plan
Koordinator tracks its roadmap via GitHub Milestones. The following items are planned for the upcoming v1.8.1 patch and the longer-term aspirational-26 milestone.
Near-term (v1.8.1)
- Scheduler – Inference Orchestration: Inference Orchestration Enhancement with Grove Integration (#2821).
- Scheduler – Reservation: Support reservation scale update by spec (#2859).
- Scheduler – Diagnosis & Audit: Diagnosis API (#2607); customizable preemption diagnosis (#2632); tooling for schedule diagnosis (#2669); optimize schedule audit with queue (#2676); optimize
failedDetail/alreadyWaitForBoundand add TTL for explanations (#2792); workload auditor (#2872); schedule suggestions on job/pod scheduling failure (#2873). - Scheduler – Platform: Refactor
ForceSyncFromInformerto align with vanilla kube-scheduler behavior (#2875); honor-stderrthresholdwhen-logtostderr=true(#2874). - Descheduler: Lambda-G scoring function for resource imbalance detection and balanced rescheduling (#2837).
- Koordlet: Add cpuset share-pool CPU info to metrics (#2800); resolve CPUBurst triggering cfsScaleDown on CgroupV2 nodes (#2801); Memory NUMA Topology Alignment (#2826).
Longer-term (aspirational-26, by the end of 2026)
- Align with Kubernetes 1.35 capabilities (#2851 – umbrella): SchedulerQueueingHints (#2852), Non-blocking API Calls (#2853), Opportunistic Batching (#2854), Gang Scheduling enhancements (#2856), Asynchronous Preemption (#2857), and NominatedNodeName for expectation (#2858).
- Dynamic Resource Allocation (DRA): End-to-end DRA support across koord-scheduler, koord-manager, koord-device-daemon, and koordlet (#2855).
- Multi-scheduler architecture: Support shared states between multiple profiles in a single scheduler (#2749); provide documentation for multi-master scheduler deployment (#2758).
- Queueing & Job scheduling: JobNomination mechanism (#2803); optimize Kueue AdmissionCheck with Koordinator Reservation (#2754); resource estimation strategy for DAG-type workflows (e.g., Argo) in koord-queue (#2786).
- Rescheduling & Balancing: Rescheduling to address the imbalance of different resource types on a single node (#2332); shrink binpack strategy (#2790).
- QoS & Koordlet: PSI-based QoS reconciler (#2463); pod-level CPU burst strategies for fine-grained control (#2557); memory NUMA topology alignment proposal (#2590); ensure NRI Hooks that Pods depend on work as expected (#2579); support evicting YARN containers (#2464).
- Scheduling Diagnosis: Continue enhancing the scheduler's ability to investigate abnormal Pod scheduling (#2348).
We encourage user feedback on usage experiences and welcome more developers to participate in the Koordinator project, jointly driving its development!
Acknowledgement
Since the project was open-sourced, Koordinator has released more than 16 versions with 120+ contributors. The community continues to grow, and we thank all community members for their active participation and valuable feedback. We also thank the CNCF and related community members for their support.
Welcome more developers and end users to join us! Whether you are a beginner or an expert in Cloud Native communities, we look forward to hearing your voice!
For the full change log, please see v1.8.0 Release.
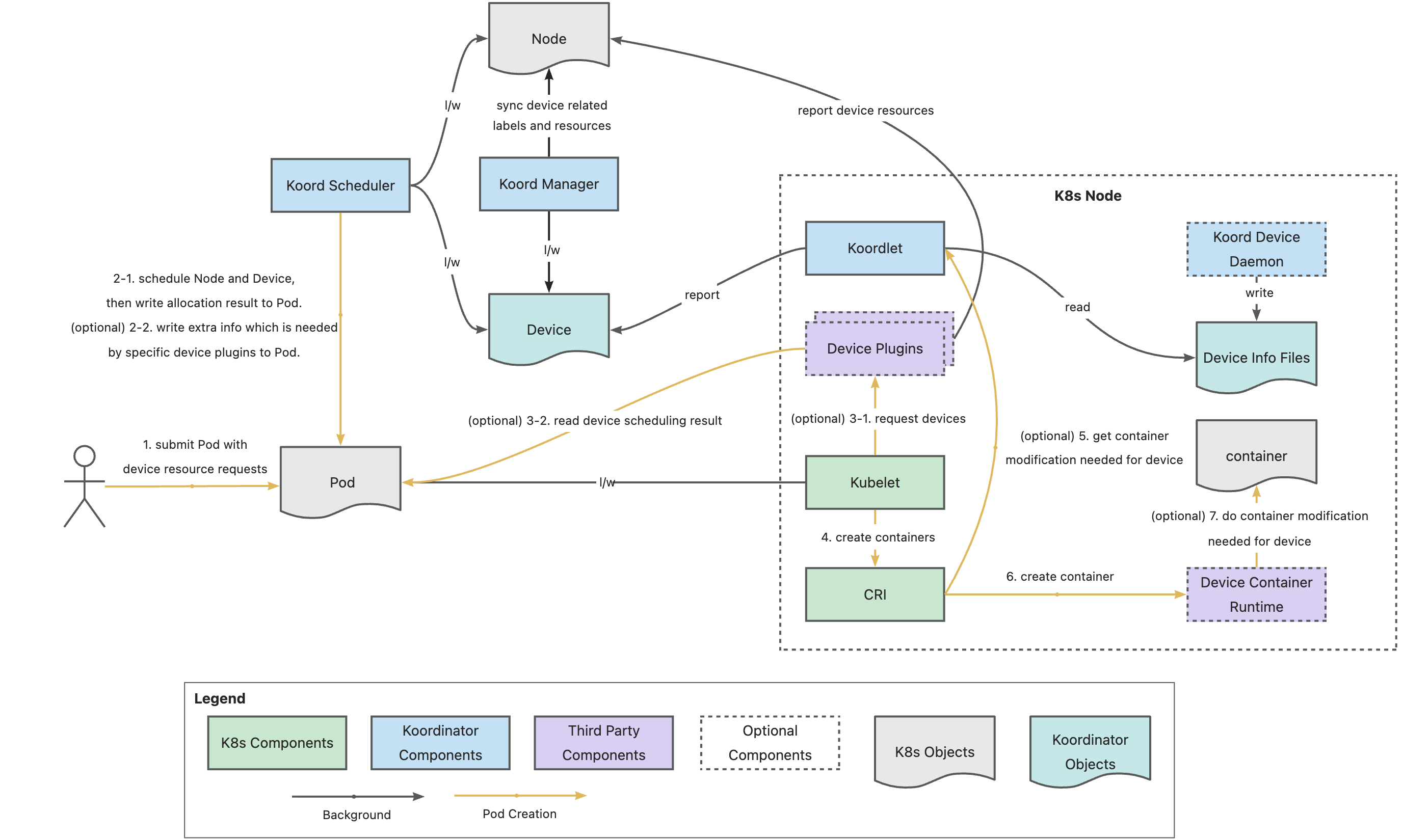
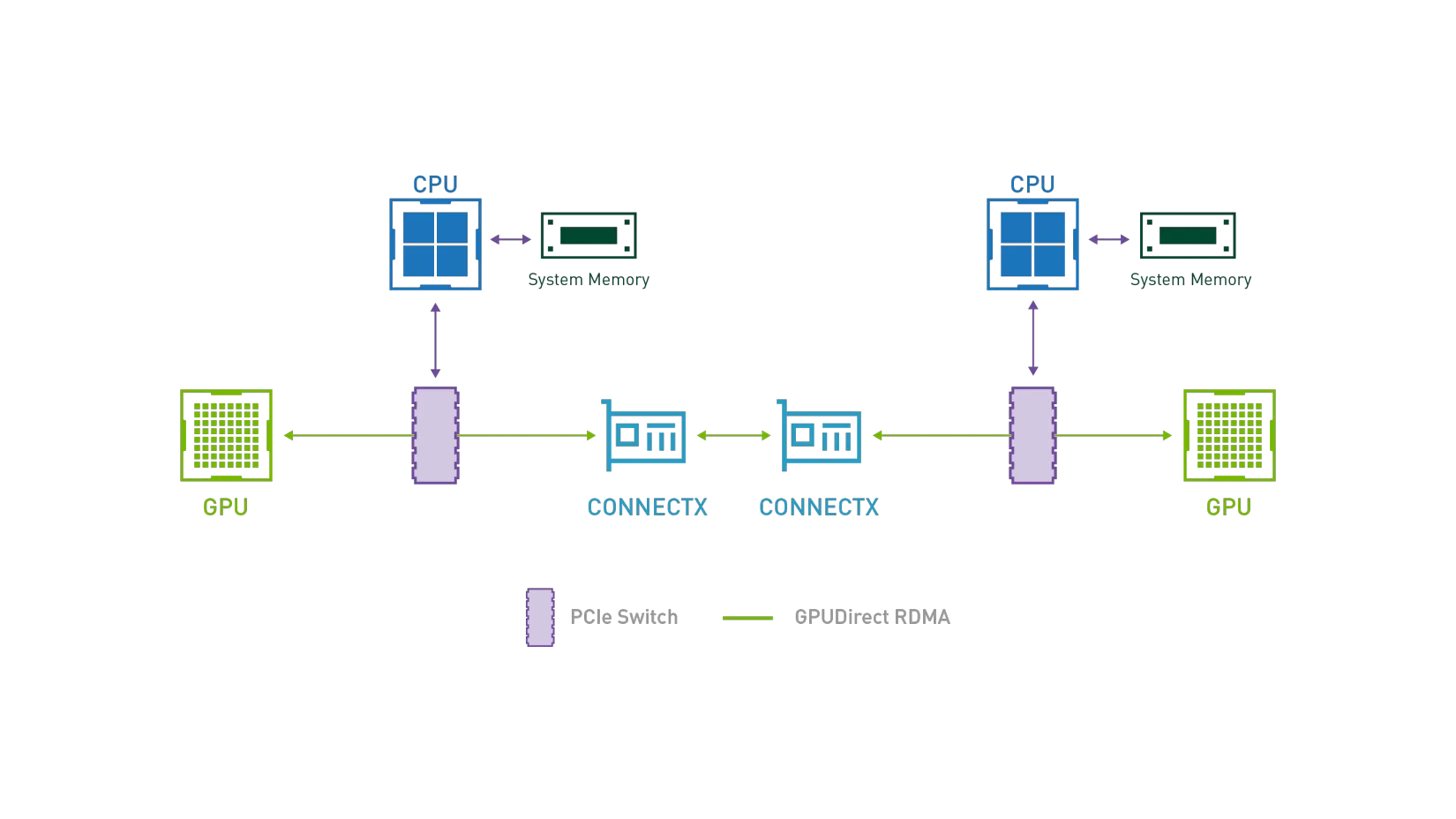 In AI model training scenarios, GPUs frequently require collective communication to synchronize updated weights during training iterations. GDR (GPUDirect RDMA) aims to solve the efficiency problem of exchanging data between multi-machine GPU devices. By using GDR technology, GPUs can exchange data directly without involving CPUs or memory, significantly reducing CPU/Memory overhead while lowering latency. To achieve this goal, Koordinator v1.6.0 introduces GPU/RDMA device joint scheduling capabilities, with the overall architecture outlined below:
In AI model training scenarios, GPUs frequently require collective communication to synchronize updated weights during training iterations. GDR (GPUDirect RDMA) aims to solve the efficiency problem of exchanging data between multi-machine GPU devices. By using GDR technology, GPUs can exchange data directly without involving CPUs or memory, significantly reducing CPU/Memory overhead while lowering latency. To achieve this goal, Koordinator v1.6.0 introduces GPU/RDMA device joint scheduling capabilities, with the overall architecture outlined below:
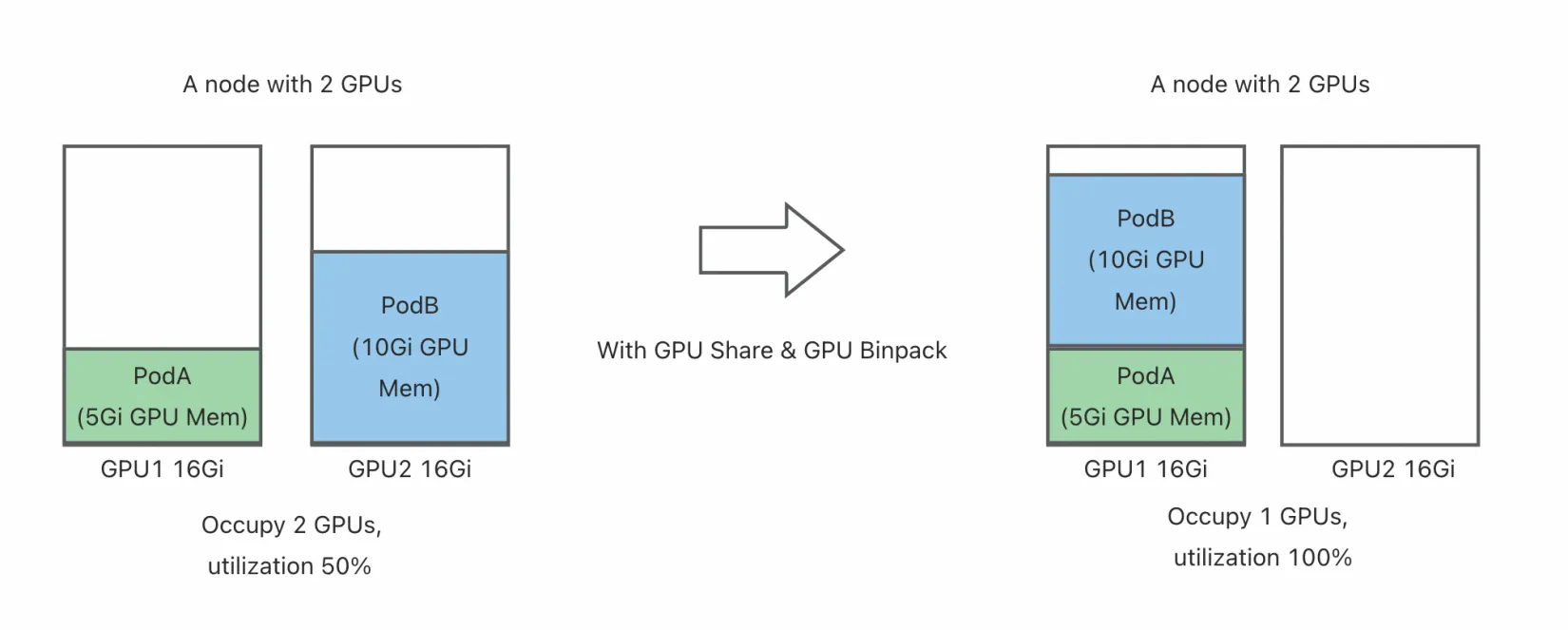
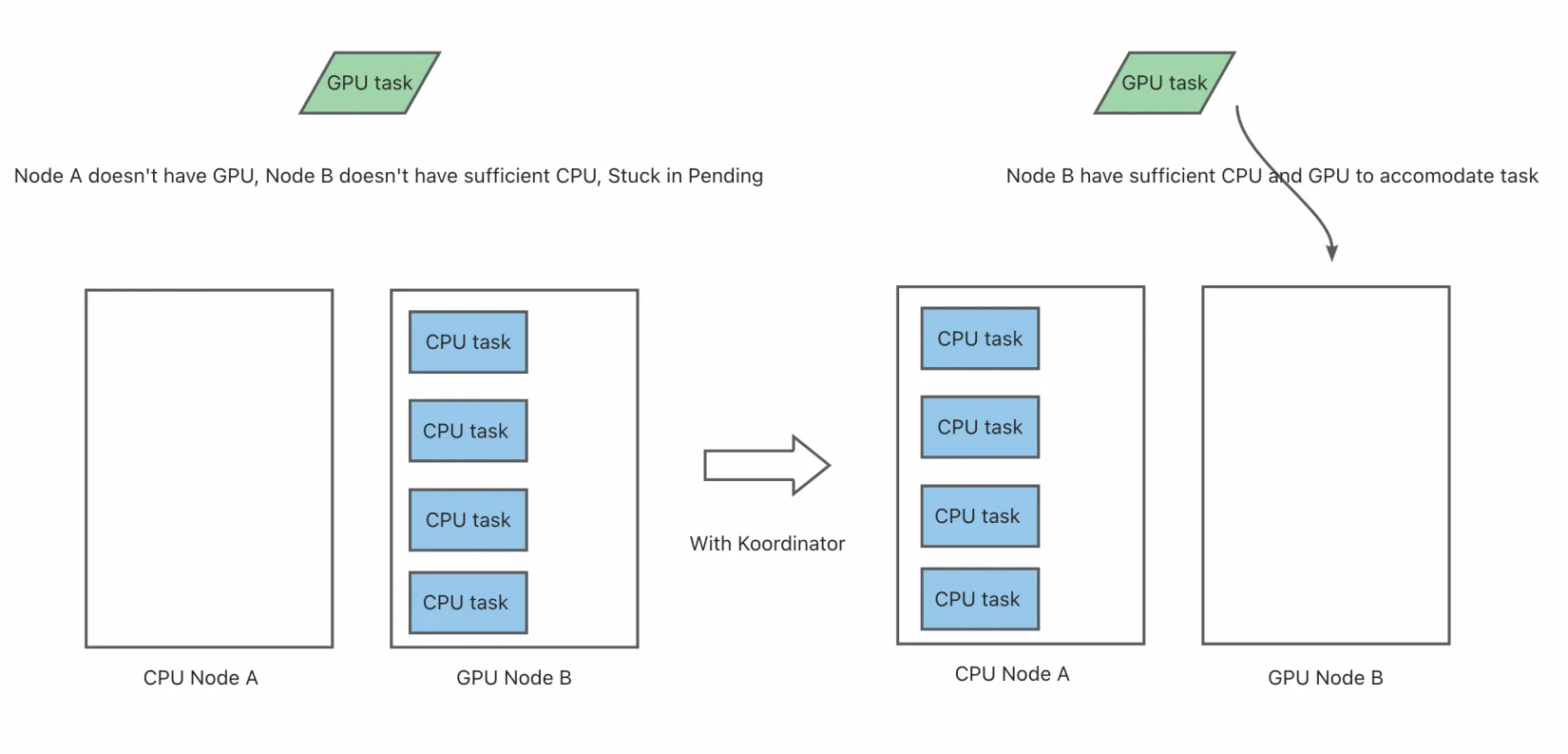 The native Kubernetes NodeResourcesFit plugin currently supports configuring the same scoring strategy for different resources, as shown below:
The native Kubernetes NodeResourcesFit plugin currently supports configuring the same scoring strategy for different resources, as shown below: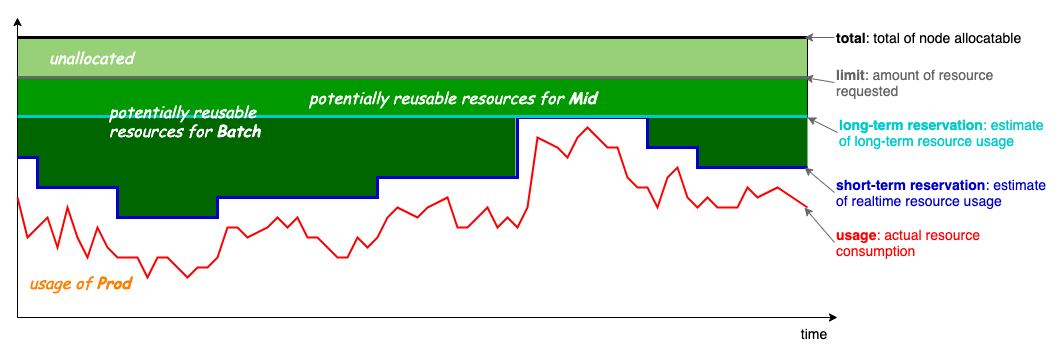 In v1.6, Koordinator updated the oversubscription formula as follows:
In v1.6, Koordinator updated the oversubscription formula as follows: Vote address:
Vote address: