Device
Device is an abstraction of heterogeneous devices on a K8s node.
Definition
Device represents all heterogeneous devices on a K8s node, typically including GPU, RDMA, FPGA, etc. In a K8s cluster, it exists as a CRD. For every K8s Node, there is a corresponding Device object that contains basic information, resource details, topology information, and health status of all heterogeneous devices on that node. An example object is as follows:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Device
metadata:
name: worker01
labels:
node.koordinator.sh/gpu-model: NVIDIA-H20
node.koordinator.sh/gpu-vendor: nvidia
...
spec:
devices:
- conditions:
- lastTransitionTime: "2025-10-07T07:15:15Z"
message: device is healthy
reason: DeviceHealthy
status: "True"
type: Healthy
health: true
id: GPU-a43e0de9-28a0-1e87-32f8-f5c4994b3e69
minor: 0
resources:
koordinator.sh/gpu-core: "100"
koordinator.sh/gpu-memory: 97871Mi
koordinator.sh/gpu-memory-ratio: "100"
topology:
busID: 0000:0e:00.0
nodeID: 0
pcieID: pci0000:0b
socketID: -1
type: gpu
- conditions:
- lastTransitionTime: "2025-10-07T07:15:15Z"
message: device is healthy
reason: DeviceHealthy
status: "True"
type: Healthy
health: true
id: GPU-05308270-c34c-8a61-e8b2-aeefbc23a3ba
minor: 1
resources:
koordinator.sh/gpu-core: "100"
koordinator.sh/gpu-memory: 97871Mi
koordinator.sh/gpu-memory-ratio: "100"
topology:
busID: "0000:44:00.0"
nodeID: 0
pcieID: pci0000:3a
socketID: -1
type: gpu
- health: true
id: 0000:0f:00.0
minor: 0
resources:
koordinator.sh/rdma: "100"
topology:
busID: 0000:0f:00.0
nodeID: 0
pcieID: pci0000:0b
socketID: -1
type: rdma
vfGroups:
- vfs:
- busID: 0000:0f:00.1
minor: -1
- busID: 0000:0f:00.2
minor: -1
- busID: 0000:0f:00.3
minor: -1
- busID: 0000:0f:00.4
minor: -1
- busID: 0000:0f:00.5
minor: -1
- busID: 0000:0f:00.6
minor: -1
- busID: 0000:0f:00.7
minor: -1
- busID: 0000:0f:01.0
minor: -1
- health: true
id: 0000:3d:00.0
minor: 1
resources:
koordinator.sh/rdma: "100"
topology:
busID: 0000:3d:00.0
nodeID: 0
pcieID: pci0000:3a
socketID: -1
type: rdma
vfGroups:
- vfs:
- busID: 0000:3d:00.1
minor: -1
- busID: 0000:3d:00.2
minor: -1
- busID: 0000:3d:00.3
minor: -1
- busID: 0000:3d:00.4
minor: -1
- busID: 0000:3d:00.5
minor: -1
- busID: 0000:3d:00.6
minor: -1
- busID: 0000:3d:00.7
minor: -1
- busID: 0000:3d:01.0
minor: -1
...
This object is reported by koordlet. When koord-scheduler schedules Pods that request heterogeneous device resources, it uses this object to make various complex scheduling decisions, such as partial device resource allocation (vGPU), virtual device allocation (RDMA VF), topology-aware scheduling, and device fault isolation. Through Device, Koordinator achieves globally optimized scheduling for heterogeneous devices, overcoming the functional limitations of the traditional K8s device plugin approach where device allocation is handled by kubelet.
Device Scheduling Architecture
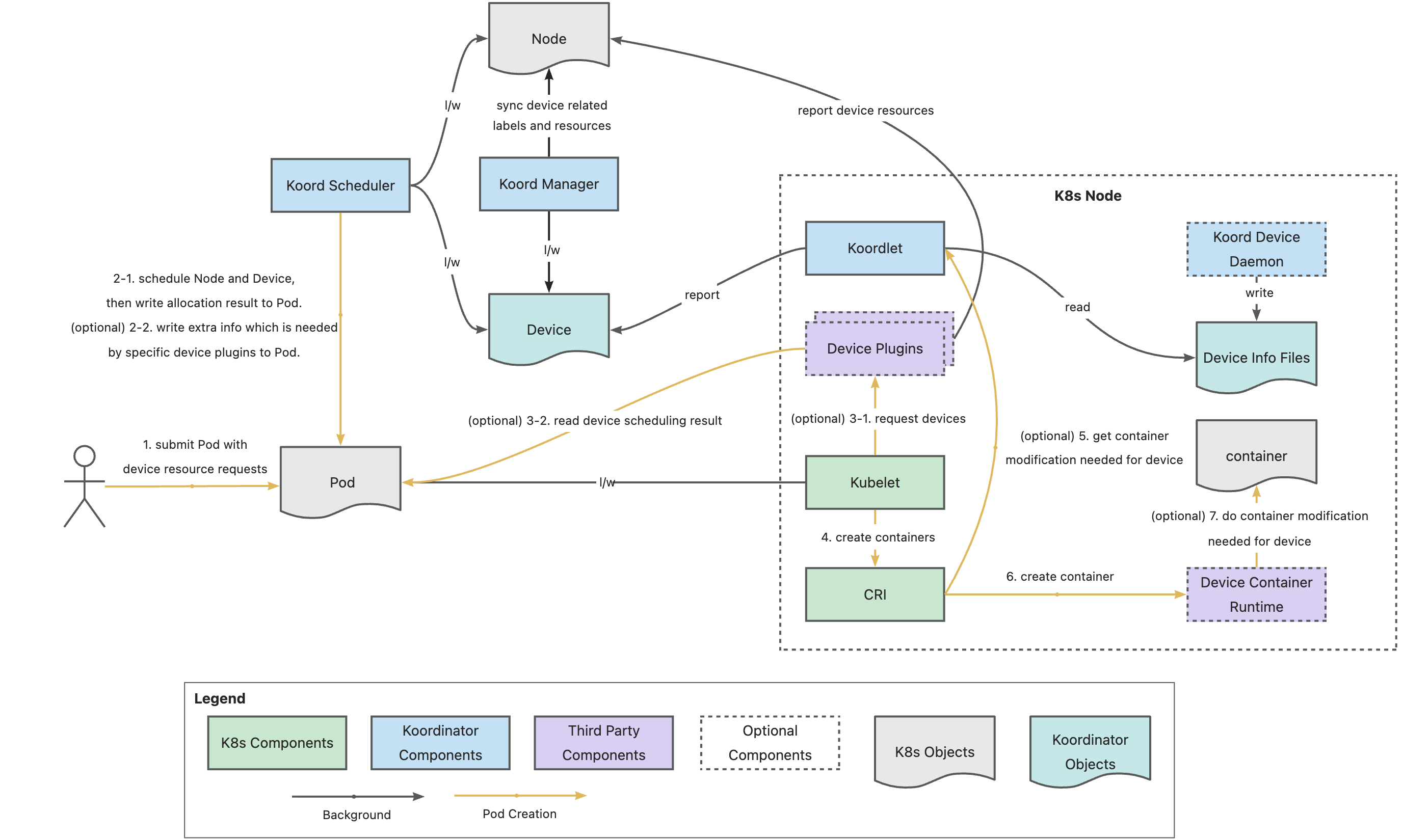
The figure above shows the component architecture and workflow of Koordinator device scheduling. The entire device scheduling process can be divided into three stages:
Device reporting: Mainly handled by koordlet and its accompanying koord-device-daemon. koord-manager also participates in this process. Currently, koordlet has built-in capabilities to collect and report information for NVIDIA GPUs and generic RDMA devices. For other vendors’ heterogeneous GPUs (such as Huawei Ascend NPU, etc.), it reads Device Info files written by external components to collect and report device information, enabling flexible adaptation to various heterogeneous GPU devices. The extension mechanism will be further described below.
Device scheduling: Fully handled by the centralized koord-scheduler. It considers both Node and Device information, and makes globally optimal scheduling decisions based on Pod device resource requests. It supports advanced capabilities such as partial device resource allocation (vGPU), virtual device allocation (RDMA VF), topology-aware scheduling, and device fault isolation. Since Device provides a good abstraction for heterogeneous devices, the core device scheduling logic of koord-scheduler is vendor-agnostic and highly general. The scheduling results are eventually written into Pod annotations for node-side components to read. In addition, koord-scheduler provides an adapter mechanism for third-party vendor device plugins to seamlessly integrate with the existing device plugin ecosystem. This extension mechanism will be further described below.
Device allocation: Mainly handled by koordlet. It currently has built-in allocation capabilities for NVIDIA GPUs and generic RDMA devices. It reads koord-scheduler’s device scheduling results from the Pod and injects the required device files and environment variables into the target container via the NRI mechanism. For NVIDIA GPUs, it integrates HAMi to provide virtual GPU allocation. For other third-party vendor heterogeneous GPUs, through the koord-scheduler device plugin adapter mechanism mentioned above, device allocation can directly use the vendor-provided device plugin and corresponding container runtime (if any).
Heterogeneous Device Adaptation Extension Mechanism
Koordinator device scheduling provides an extension mechanism to minimize the onboarding cost of new devices. Below we take integrating a new vendor’s GPU as an example to introduce this mechanism:
First, we need koordlet to recognize and report this type of GPU. This can be achieved by writing a Device Info file on the node that contains information about all such GPUs on the node. This file includes the vendor, model, resources, topology, and health status of the GPUs. These details can be obtained in any way (e.g., via the GPU’s CLI tools), as long as they are written according to the Device Info file format. koordlet will automatically detect the file and report it as a Device object. Koordinator currently provides a built-in koord-device-daemon component that can generate Device Info files for some third-party vendor GPUs. This component will continue to onboard new third-party GPUs, and contributions from the community are welcomed.
Since the core scheduling logic is generic, in most cases, whether using full GPUs or partial vGPUs, we do not need to modify koord-scheduler’s core scheduling logic.
Finally, we need to integrate the node-side device allocation for this GPU. Since the vast majority of device vendors now provide K8s device plugins, we can directly use the vendor’s official device plugin on the node side. The only required work is to add adapter code for this GPU device plugin in koord-scheduler’s device plugin adaptation extension. Its role is to convert koord-scheduler’s device scheduling result into the format recognized by the GPU’s device plugin and write it into the Pod. Likewise, koord-scheduler already has built-in adaptation logic for some third-party GPUs and will continue to onboard new ones, with community contributions welcomed. Note, however, that if a third-party vendor’s device plugin does not support scheduler-side device allocation, this integration approach cannot be used.
Devices with End-to-End Support
- GPU
- NVIDIA GPU
- Huawei Ascend NPU
- Cambricon MLU
- RDMA
- Generic, vendor-agnostic