Enhanced NodeResourceFit Plugin
Summary
The NodeResourcesFit plug-in of native k8s can only adopt a type of strategy for all resources, such as MostRequestedPriority and LeastRequestedPriority. However, in industrial practice, this design does not apply to some scenarios. For example: In AI scenarios, businesses that apply for GPUs prefer to occupy the entire GPU machine first to prevent GPU fragmentation; businesses that apply for CPU & MEM are prioritized and dispersed to non-GPU machines to prevent excessive consumption of CPU & MEM on GPU machines, resulting in real tasks of applying for GPUs. Pending due to insufficient non-GPU resources . Therefore, two plugins are extended to solve this common problem.
Motivation
- GPU tasks take priority over the entire GPU
- CPU&MEM tasks are distributed to the CPU machine first
Design Consideration
The solution is more versatile, not limited to AI clusters or CPU clusters, and not limited to common CPU resources or extended GPU resources.
Different resource policies can be configured for different cluster types and prioritized in the form of weights.
Easy to expand
Goals
Different types of resources can be configured with different strategies to prioritize them in the form of weights
Prevent pods that have not applied for scarce resources from being scheduled to nodes with scarce resources.
Non-Goals
- None.
Proposal
Extend two plug-ins to meet the above needs
- NodeResourcesFitPlus
- ScarceResourceAvoidance
User Story
Story1
- Users hope that different resource strategies can be adopted for different resource types. For example, in AI scenarios, they hope that pods that apply for GPU resources will occupy as many machines as possible, while pods that only apply for CPU resources will be evenly distributed to different machines.
Story2
- Users hope that pods that have not applied for GPU resources should try not to schedule them on machines with GPU resources to prevent pending pods that really need GPU resources from being released due to insufficient CPU on the GPU machine.
Design Details
NodeResourcesFitPlus
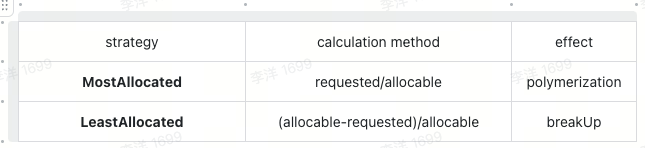
config:
resources:
nvidia.com/gpu:
type: MostAllocated
weight: 2
cpu:
type: LeastAllocated
weight: 1
memory:
type: LeastAllocated
weight: 1
config description:
node score:
finalScoreNode = [(weight1 * resource1) + (weight2 * resource2) + … + (weightN* resourceN)] /(weight1+weight2+ … +weightN)
ScarceResourceAvoidance
config:
resources:
- nvidia.com/gpu
config description:
- Obtain the resource type requested by the pod and the list of resource types that the node can allocate
- Node redundant resource type = node total resource type - pod application resource type
- The number of core resource types in the node redundant resource type = the intersection of the node redundant resource type and the core resource type list
- The more core resource types there are in the redundant resource types of node, the lower the score will be.
node score:
finalScoreNode = (allocatablesResourcesNum - requestsResourcesNum) * framework.MaxNodeScore / allocatablesResourcesNum
Alternatives
NodeAffinity VS ScarceResourceAvoidance
The node affinity strategy requires labeling the nodes in advance and adding affinity configuration when the load is released. In a real cluster with complex resource types, such maintenance costs are high and can easily cause chaos, so it must be minimized. Design principles, using the ScarceResourceAvoidance strategy will get twice the result with half the effort in this scenario.
Multiple Scheduler Configuration Profiles VS NodeResourcesFitPlus
Maintenance and usage costs are still a consideration. Adhering to the minimal design principle and converging into a unified strategy can avoid the stability impact caused by cross-over disorder. Adopting the NodeResourcesFitPlus strategy will get twice the result with half the effort in this scenario.