Load Aware Descheduling
The load-aware scheduling supported in the scheduler can select nodes with lower loads to run new Pods during scheduling, but as time, cluster environment changes, and changes in traffic/requests faced by workloads, the utilization of nodes will change dynamically Changes in the cluster will break the original load balance between nodes in the cluster, and even extreme load imbalance may occur, affecting the runtime quality of the workload.
koord-descheduler perceives changes in the load of nodes in the cluster, automatically optimizes nodes that exceed the safety load to prevents extreme load imbalance.
Introduction
The LowNodeLoad plugin in the koord-descheduler is responsible for sensing the load of the node, and reducing the load hotspot by evict/migrate Pod. The LowNodeLoad plugin is different from the Kubernetes native descheduler plugin LowNodeUtilization in that LowNodeLoad decides to deschedule based on the actual utilization of nodes, while LowNodeUtilization decides to deschedule based on the resource allocation.
The LowNodeLoad plugin has two most important parameters:
highThresholdsdefines the target usage threshold of resources. The Pods on nodes exceeding this threshold will be evicted/migrated.lowThresholdsdefines the low usage threshold of resources. The Pods on nodes below this threshold will not be evicted/migrated.
Take the following figure as an example, lowThresholds is 45%, highThresholds is 70%, we can classify nodes into three categories:
- Idle Node. Nodes with resource utilization below lowThresholds(45%);
- Normal Node. For nodes whose resource utilization is higher than lowThresholds but lower than highThresholds(70%), this load water level range is a reasonable range we expect
- Hotspot Node. If the node resource utilization rate is higher than highThresholds, the node will be judged as unsafe and belongs to the hotspot node, and some pods should be expelled to reduce the load level so that it does not exceed 70%.
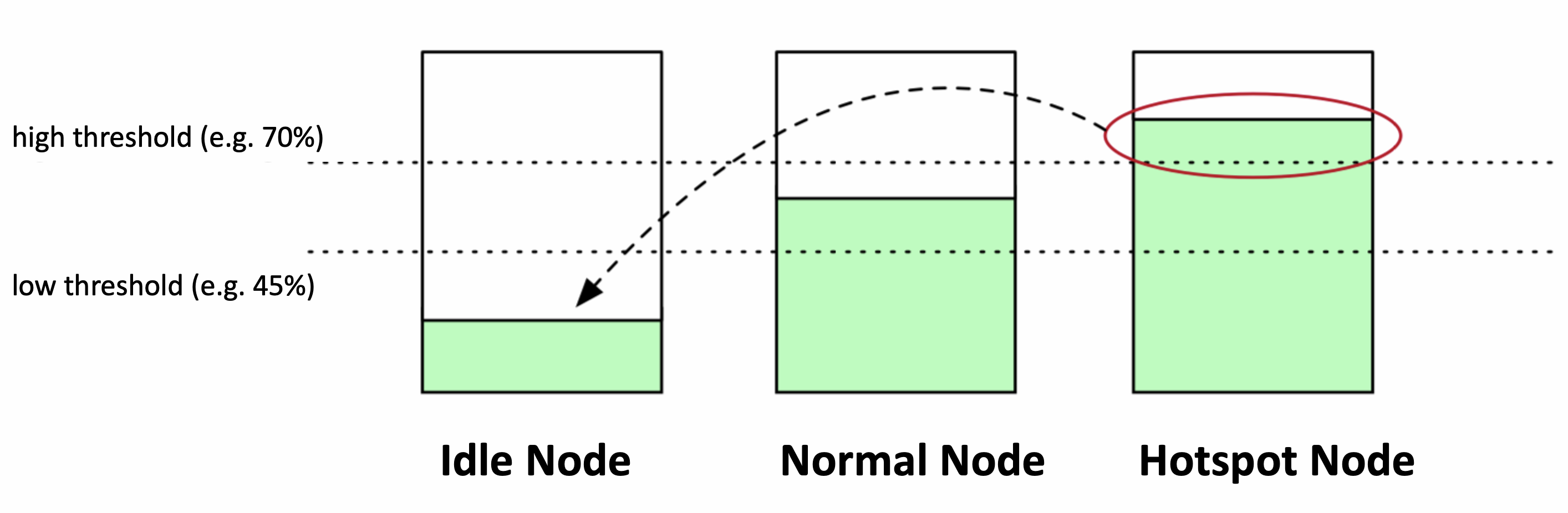
After identifying which nodes are hotspots, descheduler will perform a eviction/migration operation to evict some Pods from hotspot nodes to idle nodes. If the number of Idle Node`````` is 0 or the number of Hotspot Node`````` is 0, the descheduler does nothing.
If the total number of idle nodes in a cluster is not many, descheduling will be terminated. This can be helpful in large clusters where some nodes may be underutilized frequently or for short periods of time. By default, numberOfNodes is set to zero. This capability can be enabled by setting the parameter numberOfNodes.
Before migration, descheduler will calculate the actual free capacity to ensure that the sum of the actual utilization of the Pods to be migrated does not exceed the total free capacity in the cluster. These actual free capacities come from idle nodes, and the actual free capacity of an idle node = (highThresholds - current load of the node) * total capacity of the node. Suppose the load level of node A is 20%, the highThresholds is 70%, and the total CPU of node A is 96C, then (70%-20%) * 96 = 48C, and this 48C is the free capacity that can be carried.
In addition, when migrating hotspot nodes, the Pods on the nodes will be filtered. Currently, descheduler supports multiple filtering parameters, which can avoid migration and expulsion of very important Pods:
- Filter by namespace. Can be configured to filter only certain namespaces or filter out certain namespaces
- Filter by pod selector. Pods can be filtered out through the label selector, or Pods with certain Labels can be excluded
- Configure
nodeFitto check whether the scheduling rules have candidate nodes. When enabled, descheduler checks whether there is a matching Node in the cluster according to the Node Affinity/Node Selector/Toleration corresponding to the candidate Pod. If not, the Pod will not be evicted for migration. If you setnodeFitto false, the migration controller in the descheduler will complete the capacity reservation at this time, and start the migration after ensuring that there are resources.
After the Pods are filtered out, these Pods are sorted from multiple dimensions such as QoSClass, Priority, actual usage, and creation time.
After pods have been filtered and sorted, the migration operation begins. Before migration, it will check whether the remaining free capacity is satisfied and whether the load the current node is higher than the target safety threshold. If one of these two conditions cannot be met, descheduling will stop. Every time a Pod is migrated, the remaining free capacity will be withheld, and the load of the current node will be adjusted at the same time until the remaining capacity is insufficient or the load reaches the safety threshold.
Setup
Prerequisite
- Kubernetes >= 1.18
- Koordinator >= 1.1.1
Installation
Please make sure Koordinator components are correctly installed in your cluster. If not, please refer to Installation.
Global Configuration via plugin args
Load-aware descheduling is Disabled by default. You can modify the ConfigMap koord-descheduler-config to enable the plugin.
For users who need deep insight, please configure the rules of load-aware descheduling by modifying the ConfigMap
koord-descheduler-config in the helm chart. New configurations will take effect after the koord-descheduler restarts.
apiVersion: v1
kind: ConfigMap
metadata:
name: koord-descheduler-config
...
data:
koord-descheduler-config: |
apiVersion: descheduler/v1alpha2
kind: DeschedulerConfiguration
...
# Execute the LowNodeLoad plugin every 60s
deschedulingInterval: 60s
profiles:
- name: koord-descheduler
plugins:
deschedule:
disabled:
- name: "*"
balance:
enabled:
- name: LowNodeLoad # Configure to enable the LowNodeLoad plugin
....
pluginConfig:
- name: LowNodeLoad
args:
apiVersion: descheduler/v1alpha2
kind: LowNodeLoadArgs
evictableNamespaces:
# include and exclude are mutually exclusive, only one of them can be configured.
# include indicates that only the namespace configured below will be processed
# include:
# - test-namespace
# exclude means to only process namespaces other than those configured below
exclude:
- "kube-system"
- "koordinator-system"
# lowThresholds defines the low usage threshold of resources
lowThresholds:
cpu: 20
memory: 30
# highThresholds defines the target usage threshold of resources
highThresholds:
cpu: 50
memory: 60
....
| Field | Description | Version |
|---|---|---|
| paused | Paused indicates whether the LowNodeLoad should to work or not. | >= v1.1.1 |
| dryRun | DryRun means only execute the entire deschedule logic but don't migrate Pod | >= v1.1.1 |
| numberOfNodes | NumberOfNodes can be configured to activate the strategy only when the number of under utilized nodes are above the configured value. This could be helpful in large clusters where a few nodes could go under utilized frequently or for a short period of time. By default, NumberOfNodes is set to zero. | >= v1.1.1 |
| evictableNamespaces | Naming this one differently since namespaces are still considered while considering resources used by pods but then filtered out before eviction. | >= v1.1.1 |
| nodeSelector | NodeSelector selects the nodes that matched labelSelector. | >= v1.1.1 |
| podSelectors | PodSelectors selects the pods that matched labelSelector. | >= v1.1.1 |
| nodeFit | NodeFit if enabled, it will check whether the candidate Pods have suitable nodes, including NodeAffinity, TaintTolerance, and whether resources are sufficient. By default, NodeFit is set to true. | >= v1.1.1 |
| useDeviationThresholds | If UseDeviationThresholds is set to true, the thresholds are considered as percentage deviations from mean resource usage. lowThresholds will be deducted from the mean among all nodes and highThresholds will be added to the mean. A resource consumption above (resp. below) this window is considered as overutilization (resp. underutilization). | >= v1.1.1 |
| highThresholds | HighThresholds defines the target usage threshold of resources | >= v1.1.1 |
| lowThresholds | LowThresholds defines the low usage threshold of resources | >= v1.1.1 |
Use Load Aware Descheduling
The example cluster in this article has three 4-core 16GiB nodes.
- Deploy two
stresspod with the YAML file below.
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress-demo
namespace: default
labels:
app: stress-demo
spec:
replicas: 2
selector:
matchLabels:
app: stress-demo
template:
metadata:
name: stress-demo
labels:
app: stress-demo
spec:
containers:
- args:
- '--vm'
- '2'
- '--vm-bytes'
- '1600M'
- '-c'
- '2'
- '--vm-hang'
- '2'
command:
- stress
image: polinux/stress
imagePullPolicy: Always
name: stress
resources:
limits:
cpu: '2'
memory: 4Gi
requests:
cpu: '2'
memory: 4Gi
restartPolicy: Always
schedulerName: koord-scheduler # use the koord-scheduler
$ kubectl create -f stress-demo.yaml
deployment.apps/stress-demo created
- Watch the pod status util they become running.
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
stress-demo-7fdd89cc6b-lml7k 1/1 Running 0 21m 10.0.2.83 cn-beijing.10.0.2.54 <none> <none>
stress-demo-7fdd89cc6b-xr5dl 1/1 Running 0 4m40s 10.0.2.77 cn-beijing.10.0.2.53 <none> <none>
The stress pods are scheduled on cn-beijing.10.0.2.53 and cn-beijing.10.0.2.54.
- Check the load of each node.
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cn-beijing.10.0.2.53 3825m 98% 4051Mi 31%
cn-beijing.10.0.2.54 2155m 55% 4500Mi 35%
cn-beijing.10.0.2.58 182m 4% 1367Mi 10%
In above order, cn-beijing.10.0.2.53 and cn-beijing.10.0.2.54 have the highest load, while cn-beijing.10.0.2.58 has the lowest load.
Update
koord-descheduler-configto enableLowNodeLoadplugin.Observe the Pod changes and wait for the koord-descheduler to execute the eviction/migration operation.
$ kubectl get pod -w
NAME READY STATUS RESTARTS AGE
stress-demo-7fdd89cc6b-lml7k 1/1 Running 0 22m
stress-demo-7fdd89cc6b-xr5dl 1/1 Running 0 5m45s
stress-demo-7fdd89cc6b-xr5dl 1/1 Terminating 0 5m59s
stress-demo-7fdd89cc6b-8k8wq 0/1 Pending 0 0s
stress-demo-7fdd89cc6b-8k8wq 0/1 Pending 0 0s
stress-demo-7fdd89cc6b-8k8wq 0/1 ContainerCreating 0 0s
stress-demo-7fdd89cc6b-8k8wq 0/1 ContainerCreating 0 1s
stress-demo-7fdd89cc6b-8k8wq 1/1 Running 0 3s
- Observe the Event, you can see the following migration records
$ kubectl get event |grep stress-demo-7fdd89cc6b-xr5dl
74s Normal Evicting podmigrationjob/e54863dc-b651-47e3-9ffd-08b6b4ff64d5 Pod "default/stress-demo-7fdd89cc6b-xr5dl" evicted from node "cn-beijing.10.0.2.53" by the reason "node is overutilized, cpu usage(56.13%)>threshold(50.00%)"
41s Normal EvictComplete podmigrationjob/e54863dc-b651-47e3-9ffd-08b6b4ff64d5 Pod "default/stress-demo-7fdd89cc6b-xr5dl" has been evicted
7m12s Normal Scheduled pod/stress-demo-7fdd89cc6b-xr5dl Successfully assigned default/stress-demo-7fdd89cc6b-xr5dl to cn-beijing.10.0.2.53
7m12s Normal AllocIPSucceed pod/stress-demo-7fdd89cc6b-xr5dl Alloc IP 10.0.2.77/24
7m12s Normal Pulling pod/stress-demo-7fdd89cc6b-xr5dl Pulling image "polinux/stress"
6m59s Normal Pulled pod/stress-demo-7fdd89cc6b-xr5dl Successfully pulled image "polinux/stress" in 12.685405843s
6m59s Normal Created pod/stress-demo-7fdd89cc6b-xr5dl Created container stress
6m59s Normal Started pod/stress-demo-7fdd89cc6b-xr5dl Started container stress
74s Normal Descheduled pod/stress-demo-7fdd89cc6b-xr5dl Pod evicted from node "cn-beijing.10.0.2.53" by the reason "node is overutilized, cpu usage(56.13%)>threshold(50.00%)"
73s Normal Killing pod/stress-demo-7fdd89cc6b-xr5dl Stopping container stress
7m13s Normal SuccessfulCreate replicaset/stress-demo-7fdd89cc6b Created pod: stress-demo-7fdd89cc6b-xr5dl