负载感知重调度
调度器中支持的负载感知调度能够在调度时选择负载较低的节点运行新的Pod,但随着时间、集群环境变化以及工作负载面对的流量/请求的变化时,节点的利用率会动态的发生变化,集群内节点间原本负载均衡的情况被打破,甚至有可能出现极端负载不均衡的情况,影响到工作负载运行时质量。
koord-descheduler 感知集群内节点负载的变化,自动的优化超过负载水位安全阈值的节点,防止出现极端负载不均衡的情况。
简介
koord-descheduler 组件中 LowNodeLoad 插件负责感知负载水位完成热点打散重调度工作。LowNodeLoad 插件 与 Kubernetes 原生的 descheduler 的插件 LowNodeUtilization 不同的是,LowNodeLoad 是根据节点真实利用率的情况决策重调度,而 LowNodeUtilization 是根据资源分配率决策重调度。
LowNodeLoad插件有两个最重要的参数:
highThresholds表示负载水位的目标安全阈值,超过该阈值的节点上的 Pod 将参与重调度;lowThresholds表示负载水位的空闲安全水位。低于该阈值的节点上的 Pod 不会被重调度。
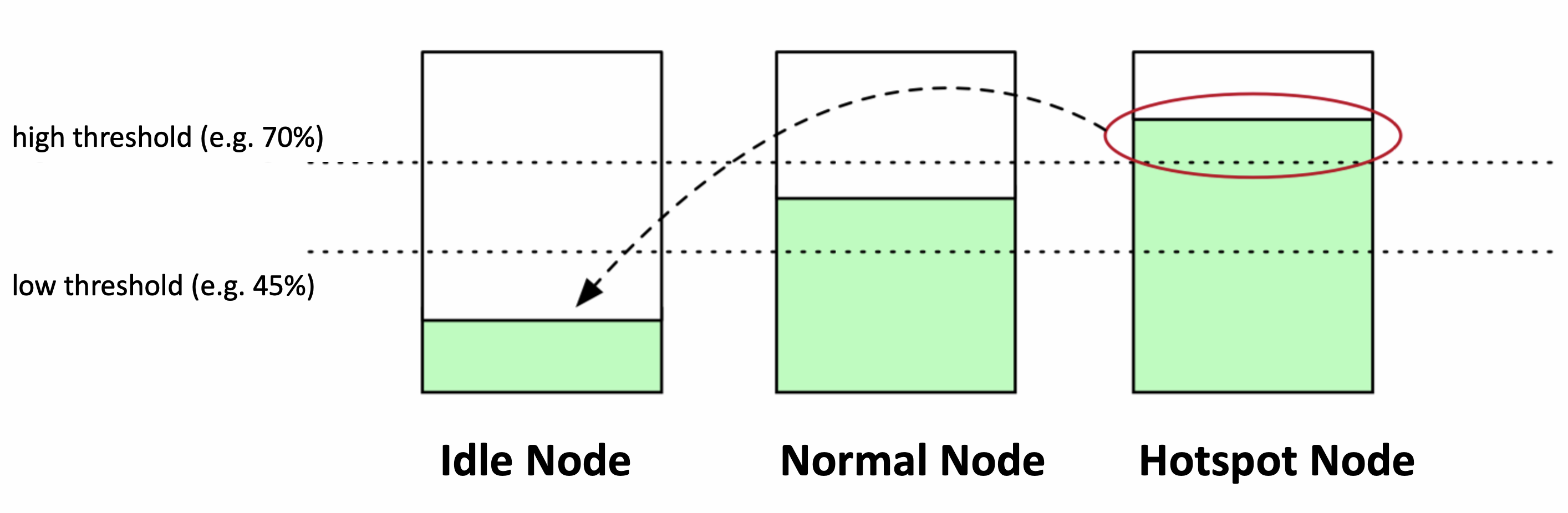
以下图为例,lowThresholds 为45%,highThresholds 为 70%,我们可以把节点归为三类:
- 空闲节点(Idle Node)。资源利用率低于 45% 的节点;
- 正常节点(Normal Node)。资源利用率高于 45% 但低于 70% 的节点,这个负载水位区间是我们期望的合理的区间范围
- 热点节点(Hotspot Node)。如果节点资源利用率高于70%,这个节点就会被判定为不安全了,属于热点节点,应该驱逐一部分 Pod,降低负载水位,使其不超过 70%。
在识别出哪些节点是热点后,koord-descheduler 将会执行迁移驱逐操作,驱逐热点节点中的部分 Pod 到空闲节点上。如果 Idle Node 数量是 0 或者 Hotspot Node 数量是 0,则 descheduler 不会执行任何操作。
如果一个集群中空闲节点的总数并不是很多时会终止重调度。这在大型集群中可能会有所帮助,在大型集群中,一些节点可能会经常或短时间使用不足。默认情况下,numberOfNodes 设置为零。可以通过设置参数 numberOfNodes 来开启该能力。
在迁移前,koord-descheduler 会计算出实际空闲容量,确保要迁移的 Pod 的实际利用率之和不超过集群内空闲总量。这些实际空闲容量来自于空闲节点,一个空闲节点实际空闲容量 = (highThresholds - 节点当前负载) * 节点总容量。假设节点 A 的负载水位是20%,highThresholdss是 70%,节点 A 的 CPU 总量为96C,那么 (70%-20%) * 96 = 48C,这 48C 就是可以承载的空闲容量了。
另外,在迁移热点节点时,会过滤筛选节点上的Pod,目前 koord-descheduler 支持多种筛选参数,可以避免迁移驱逐非常重要的 Pod:
- 按 namespace 过滤。可以配置成只筛选某些 namespace 或者过滤掉某些 namespace
- 按 pod selector 过滤。可以通过 label selector 筛选出 Pod,或者排除掉具备某些 Label 的 Pod
- 配置 nodeFit 检查调度规则是否有备选节点。当开启后,koord-descheduler 根据备选 Pod 对应的 Node Affinity/Node Selector/Toleration ,检查集群内是否有与之匹配的 Node,如果没有的话,该 Pod 将不会去驱逐迁移。如果设置
nodeFit为 false,此时完全由 koord-descheduler 底层的迁移控制器完成容量预留,确保有资源后开始迁移。
当筛选出 Pod 后,从 QoSClass、Priority、实际用量和创建时间等多个维度对这些 Pod 排序。
筛选 Pod 并完成排序后,开始执行迁移操作。迁移前会检查剩余空闲容量是否满足和当前节点的负载水位是否高于目标安全阈值,如果这两个条件中的一个不能满足,将停止重调度。每迁移一个 Pod 时,会预扣剩余空闲容量,同时也会调整当前节点的负载水位,直到剩余容量不足或者水位达到安全阈值。
设置
前置条件
- Kubernetes >= 1.18
- Koordinator >= 1.1.1
安装
请确保 Koordinator 组件已正确安装在你的集群中。 如果没有,请参考安装文档。
配置
负载感知重调度默认是禁用的。可以通过修改配置 ConfigMap koord-descheduler-config 启用该能力。
对于需要深入定制的用户,可以按照需要更改 Helm Chart 中的 ConfigMap koord-descheduler-config 设置参数。修改配置后需要重启 koord-descheduler 才能应用最新的配置。
apiVersion: v1
kind: ConfigMap
metadata:
name: koord-descheduler-config
...
data:
koord-descheduler-config: |
apiVersion: descheduler/v1alpha2
kind: DeschedulerConfiguration
...
# Execute the LowNodeLoad plugin every 60s
deschedulingInterval: 60s
profiles:
- name: koord-descheduler
plugins:
deschedule:
disabled:
- name: "*"
balance:
enabled:
- name: LowNodeLoad # Configure to enable the LowNodeLoad plugin
....
pluginConfig:
- name: LowNodeLoad
args:
apiVersion: descheduler/v1alpha2
kind: LowNodeLoadArgs
evictableNamespaces:
# include and exclude are mutually exclusive, only one of them can be configured.
# include indicates that only the namespace configured below will be processed
# include:
# - test-namespace
# exclude means to only process namespaces other than those configured below
exclude:
- "kube-system"
- "koordinator-system"
# lowThresholds defines the low usage threshold of resources
lowThresholds:
cpu: 20
memory: 30
# highThresholds defines the target usage threshold of resources
highThresholds:
cpu: 50
memory: 60
....
| 字段 | 说明 | 版本 |
|---|---|---|
| paused | Paused 控制 LowNodeLoad 插件是否工作. | >= v1.1.1 |
| dryRun | DryRun 表示只执行重调度逻辑,但不重复啊迁移/驱逐 Pod | >= v1.1.1 |
| numberOfNodes | NumberOfNodes 可以配置为仅当未充分利用的节点数高于配置值时才激活该策略。 这在大型集群中可能会有所帮助,在大型集群中,一些节点可能会经常或短时间使用不足。 默认情况下,NumberOfNodes 设置为零。 | >= v1.1.1 |
| evictableNamespaces | 可以参与重调度的Namespace。可以配置 include和exclude两种,但两种策略只能二选一。include 表示只处理指定的 namespace;exclude 表示只处理指定之外的namespace。 | >= v1.1.1 |
| nodeSelector | 通过 label selector 机制选择目标节点。 | >= v1.1.1 |
| podSelectors | 通过 label selector 选择要处理的Pod。 | >= v1.1.1 |
| nodeFit | 表示是否按照备选要迁移的Pod中指定的 Node Affinity/Node Selector/Resource Requests/TaintToleration 判断是否有空闲节点。没有则不参与调度。默认开启。可以设置为 false 禁用该能力。 | >= v1.1.1 |
| useDeviationThresholds | 如果 useDeviationThresholds 设置为 true,则阈值被视为与平均资源使用率的百分比偏差。lowThresholds 将从所有节点的平均值中减去,highThresholds 将添加到平均值中。高于此窗口的资源消耗被视为过度利用的,即热点节点。 | >= v1.1.1 |
| highThresholds | 表示负载水位的目标安全阈值,超过该阈值的节点上的Pod将参与重调度。 | >= v1.1.1 |
| lowThresholds | 表示负载水位的空闲安全水位。低于该阈值的节点上的Pod不会被重调度。 | >= v1.1.1 |
使用负载感知重调度
本文示例的集群有3台 4核16GiB 节点。
- 使用下面的 YAML 创建两个 stress Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress-demo
namespace: default
labels:
app: stress-demo
spec:
replicas: 2
selector:
matchLabels:
app: stress-demo
template:
metadata:
name: stress-demo
labels:
app: stress-demo
spec:
containers:
- args:
- '--vm'
- '2'
- '--vm-bytes'
- '1600M'
- '-c'
- '2'
- '--vm-hang'
- '2'
command:
- stress
image: polinux/stress
imagePullPolicy: Always
name: stress
resources:
limits:
cpu: '2'
memory: 4Gi
requests:
cpu: '2'
memory: 4Gi
restartPolicy: Always
schedulerName: koord-scheduler # use the koord-scheduler
$ kubectl create -f stress-demo.yaml
deployment.apps/stress-demo created
- 观察 Pod 的状态,直到它们开始运行。
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
stress-demo-7fdd89cc6b-lml7k 1/1 Running 0 21m 10.0.2.83 cn-beijing.10.0.2.54 <none> <none>
stress-demo-7fdd89cc6b-xr5dl 1/1 Running 0 4m40s 10.0.2.77 cn-beijing.10.0.2.53 <none> <none>
这些 Pod 调度到了节点 cn-beijing.10.0.2.53 和 cn-beijing.10.0.2.54.
- 检查每个node节点的负载。
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cn-beijing.10.0.2.53 3825m 98% 4051Mi 31%
cn-beijing.10.0.2.54 2155m 55% 4500Mi 35%
cn-beijing.10.0.2.58 182m 4% 1367Mi 10%
按照输出结果显示, 节点 cn-beijing.10.0.2.53 和 cn-beijing.10.0.2.54 负载比较高, 节点 cn-beijing.10.0.2.58 负载最低。
更新配置
koord-descheduler-config启用插件LowNodeLoad。观察 Pod 变化,等待重调度器执行驱逐迁移操作。
$ kubectl get pod -w
NAME READY STATUS RESTARTS AGE
stress-demo-7fdd89cc6b-lml7k 1/1 Running 0 22m
stress-demo-7fdd89cc6b-xr5dl 1/1 Running 0 5m45s
stress-demo-7fdd89cc6b-xr5dl 1/1 Terminating 0 5m59s
stress-demo-7fdd89cc6b-8k8wq 0/1 Pending 0 0s
stress-demo-7fdd89cc6b-8k8wq 0/1 Pending 0 0s
stress-demo-7fdd89cc6b-8k8wq 0/1 ContainerCreating 0 0s
stress-demo-7fdd89cc6b-8k8wq 0/1 ContainerCreating 0 1s
stress-demo-7fdd89cc6b-8k8wq 1/1 Running 0 3s
- 观察Event,可以看到如下迁移记录
$ kubectl get event |grep stress-demo-7fdd89cc6b-xr5dl
74s Normal Evicting podmigrationjob/e54863dc-b651-47e3-9ffd-08b6b4ff64d5 Pod "default/stress-demo-7fdd89cc6b-xr5dl" evicted from node "cn-beijing.10.0.2.53" by the reason "node is overutilized, cpu usage(56.13%)>threshold(50.00%)"
41s Normal EvictComplete podmigrationjob/e54863dc-b651-47e3-9ffd-08b6b4ff64d5 Pod "default/stress-demo-7fdd89cc6b-xr5dl" has been evicted
7m12s Normal Scheduled pod/stress-demo-7fdd89cc6b-xr5dl Successfully assigned default/stress-demo-7fdd89cc6b-xr5dl to cn-beijing.10.0.2.53
7m12s Normal AllocIPSucceed pod/stress-demo-7fdd89cc6b-xr5dl Alloc IP 10.0.2.77/24
7m12s Normal Pulling pod/stress-demo-7fdd89cc6b-xr5dl Pulling image "polinux/stress"
6m59s Normal Pulled pod/stress-demo-7fdd89cc6b-xr5dl Successfully pulled image "polinux/stress" in 12.685405843s
6m59s Normal Created pod/stress-demo-7fdd89cc6b-xr5dl Created container stress
6m59s Normal Started pod/stress-demo-7fdd89cc6b-xr5dl Started container stress
74s Normal Descheduled pod/stress-demo-7fdd89cc6b-xr5dl Pod evicted from node "cn-beijing.10.0.2.53" by the reason "node is overutilized, cpu usage(56.13%)>threshold(50.00%)"
73s Normal Killing pod/stress-demo-7fdd89cc6b-xr5dl Stopping container stress
7m13s Normal SuccessfulCreate replicaset/stress-demo-7fdd89cc6b Created pod: stress-demo-7fdd89cc6b-xr5dl