背景
AI 与批量计算负载持续推动着 Kubernetes 调度系统的演进。随着集群规模和工作负载多样性的不断增长,用户对更丰富的排队语义、更精确的资源预留、更深入的可观测性以及跨异构硬件的统一管理提出了更高要求。
自 2022 年 4 月开源以来,Koordinator 已累计发布 16 个大版本,为工作负载编排、混部、精细化调度、隔离与性能优化提供端到端的解决方案。我们由衷感谢来自阿里巴巴、蚂蚁科技、Intel、小红书、小米、爱奇艺、360、有赞、PITS Global Data Recovery Services、趣丸、meiyapico、得物、亚信科技、曹操出行、爱豆豆、NVIDIA、蔚来、Mammotion、中瑞集团、鹤山德豪 等众多企业工程师的持续贡献。
今天,我们很高兴地宣布 Koordinator v1.8.0 正式发布。本版本引入了 Koord-Queue——专为 Koordinator 生态打造的 Kubernetes 作业排队系统;增强了 资源预留(Reservation) 的 预占(Pre-Allocation) 能力,支持集群级模式与多个预占 Pod;新增 Scheduling Hint 内部协议,实现调度组件之间的协同决策;将异构设备支持扩展至 MetaX GPU/sGPU 和 华为 Ascend 300I Duo;提供开箱即用的 koord-scheduler / koord-descheduler Grafana 仪表盘;并将平台基线升级至 Kubernetes 1.35。
核心亮点功能
1. Koord-Queue:面向 Kubernetes 的原生作业级排队系统
多租户 AI/ML 与批量计算集群需要在 Pod 级调度之上,额外提供作业级别的排队、准入控制与资源公平性。Koordinator v1.8.0 为此引入了全新的组件 Koord-Queue。
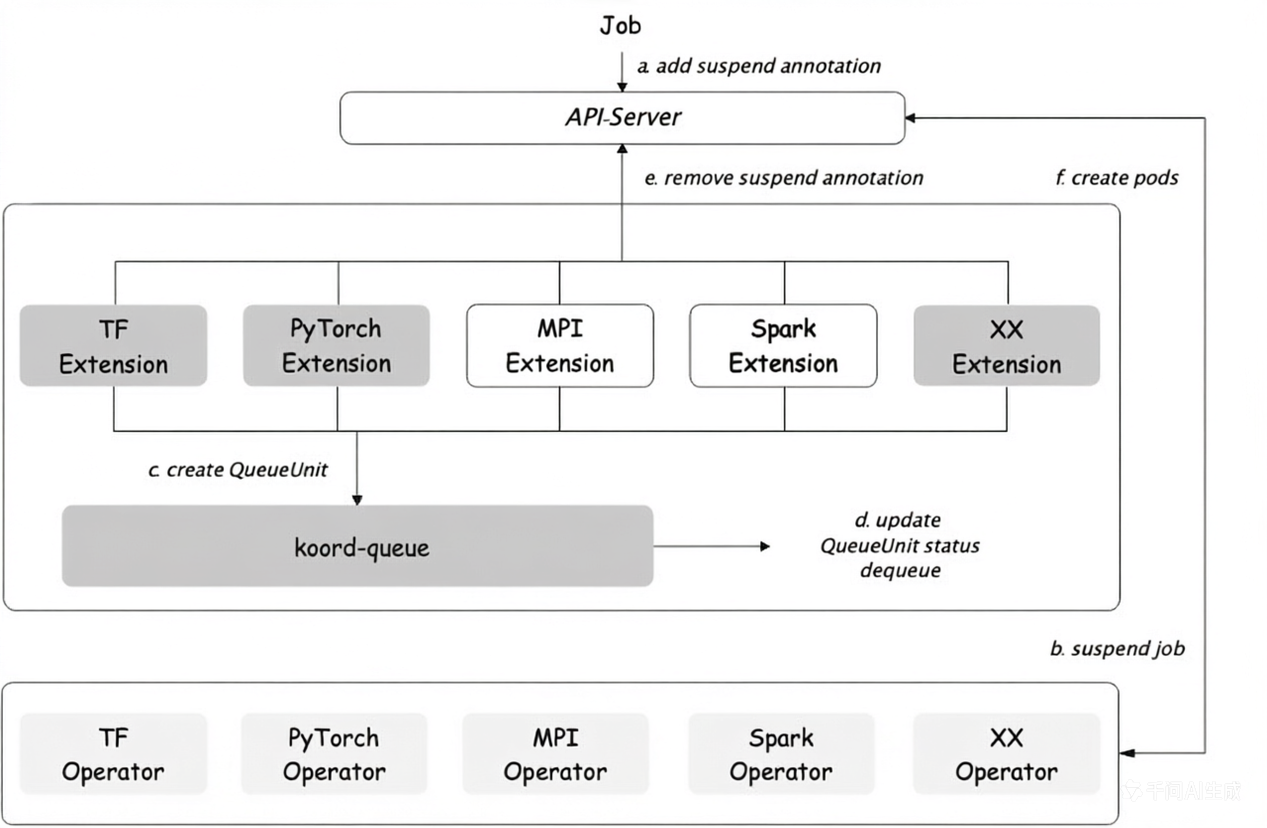
Koord-Queue 主要能力:
- 作业级排队:以
QueueUnit为单位管理整个作业(TFJob、PyTorchJob、MPIJob、Spark、Argo Workflow、Ray、原生 Kubernetes Job 等),而非单个 Pod。 - 深度集成 ElasticQuota:与 Koordinator 的
ElasticQuotaCRD(scheduling.sigs.k8s.io/v1alpha1)深度集成,支持弹性借用、min/max 保障与多级公平共享。 - 可插拔排队策略:每个队列可配置
Priority(按优先级 + 创建时间排序)或Block(严格阻塞)策略。 - 预调度准入:通过
MultiQueueSort、QueueSort、QueueUnitMapping、Filter、Reserve等插件扩展点,在 Pod 调度器之前对作业进行筛选,显著降低调度器压力。 - 准入检查框架 (进行中):API 兼容 Kueue 的
AdmissionCheck,可支持配额校验、容量检查、外部审批等自定义准入逻辑。
集成 ElasticQuota 的 Queue 示例:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Queue
metadata:
name: team-a-queue
namespace: koord-queue
spec:
queuePolicy: Priority
priority: 100
Koord-Queue 通过独立的 Helm Chart 部署:
helm install koord-queue koordinator-sh/koord-queue --version 1.8.0 \
--namespace koord-queue
更多详情请参考 Koord-Queue 设计文档 与 队列管理用户手册。
2. 资源预留:支持集群级与多 Pod 的预占能力
v1.8.0 对 Reservation CRD 进行了扩展,新增 预占(Pre-Allocation) 能力。即使当前节点资源暂不可分配,用户也可以为未来的资源需求进行预占,在推理编排、滚动升级、优先级容量规划等场景下尤为实用。
主要增强点:
Cluster预占模式:通过preAllocationPolicy.mode: Cluster。在默认的Default模式下,调度器通过 Reservation Spec 中的 Owner Matcher 识别可被预占的 Pod;而在Cluster模式下,调度器改为通过集群级的 Label/Annotation 选择器识别候选 Pod,打上pod.koordinator.sh/is-pre-allocatable: "true"标签的 Pod 即可被预占。该模式在多租户集群中尤其有用,预占候选 Pod 可能属于不同 Owner 并需要统一管理。- 支持多个预占 Pod:通过
preAllocationPolicy.enableMultiple: true开启。关闭时,一个 Reservation 仅允许被单个 Pod 预占;开启后,多个 Pod 可共同满足 Reservation 的资源请求——在资源碎片导致单个 Pod 无法消耗全部预留资源的场景下尤为实用。 - 预占优先级:通过
pod.koordinator.sh/pre-allocatable-priority注解(数字字符串,值越大优先级越高)精细控制哪些候选 Pod 会优先被预占。 - 与 NodeNUMAResource、DeviceShare 集成:预占过程对 CPU、NUMA、GPU 等资源的处理与常规调度保持一致。
启用 Cluster 模式与多 Pod 预占的示例片段:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Reservation
metadata:
name: pre-alloc-cluster
spec:
preAllocation: true
preAllocationPolicy:
mode: Cluster
enableMultiple: true
更多信息请参考 资源预留。
3. Scheduling Hint:调度组件之间的协同决策
Koordinator v1.8.0 引入了 Scheduling Hint 内部协议,允许调度相关组件(例如 Koord-Queue、网络拓扑感知的预调度器)在不越权的前提下向 koord-scheduler 传递建议,辅助其做出更高效的调度决策。
首个支持的字段是 preferredNodeNames,调度器会优先尝试这些候选节点,失败后再回退到常规调度流程:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-hint
annotations:
internal.scheduling.koordinator.sh/scheduling-hint: '{"preferredNodeNames": ["node-1", "node-2"]}'
spec:
schedulerName: koord-scheduler
containers:
- name: app
image: nginx
与 status.nominatedNodeName 相比,Scheduling Hint:
- 接受节点列表,天然提供回退选项。
- 在 Assume 阶段不占用节点资源,不会影响其他 Pod 的调度。
- 当偏好节点不可用时,会平滑回退到常规调度。
更多信息请参考 Scheduling Hint。
4. 扩展异构设备支持:MetaX GPU/sGPU 与华为 Ascend 300I Duo
在 v1.7.0 支持华为昇腾 NPU 与寒武纪 MLU 的基础上,Koordinator v1.8.0 进一步扩展了统一的设备调度框架:
- MetaX GPU/sGPU 支持:通过
koord-device-daemon与精细化设备调度能力,MetaX 整卡与 sGPU 虚拟切片均以DeviceCR 的形式上报,并使用标准的koordinator.sh/gpu-*资源,使分区感知、拓扑感知、GPU 共享等策略在多厂商间保持一致。 - 华为 Ascend 300I Duo:在设备调度的 DP 适配器中新增 Ascend 300I Duo 适配,与已有的 910B 系列形成互补,为推理场景提供优化的调度能力。
- NVIDIA GPU 健康状态上报:为上层系统提供更丰富的节点级 GPU 健康信号。
下面是一个申请 MetaX 虚拟 GPU(sGPU)的 Pod 示例,其中指定了算力百分比、显存大小与 QoS 策略:
apiVersion: v1
kind: Pod
metadata:
labels:
app: demo-sleep
name: test-metax-sgpu
namespace: default
annotations:
metax-tech.com/sgpu-qos-policy: "fixed-share" # fixed-share/best-effort/burst-share
spec:
containers:
- command:
- sleep
- infinity
image: ubuntu:22.04
imagePullPolicy: IfNotPresent
name: demo-sleep
resources:
limits:
cpu: "32"
memory: 64Gi
koordinator.sh/gpu.shared: "1"
koordinator.sh/gpu-memory: "1Gi"
koordinator.sh/gpu-core: "10"
metax-tech.com/sgpu: "1"
requests:
cpu: "32"
memory: 64Gi
koordinator.sh/gpu.shared: "1"
koordinator.sh/gpu-memory: "1Gi"
koordinator.sh/gpu-core: "10"
metax-tech.com/sgpu: "1"
更多信息请参考 设备调度 — Metax GPU 和 精细化设备调度。
5. 基于自定义优先级的重调度
v1.8.0 在 koord-descheduler 中新增了 CustomPriority 均衡插件,支持按用户自定义的节点优先级顺序重调度 Pod。用户可以根据业务语义将节点划分为不同的优先级层级 —— 例如按量付费 vs. 包年包月、共享池 vs. 专用池、或 Spot vs. On-Demand 实例。当低优先级层级有足够容量容纳运行在高优先级层级上的 Pod 时,重调度器会主动驱逐这些 Pod,使其能够被重新调度到成本更低(或更易回收)的节点池。
典型应用场景:
- 成本优化:将按量付费节点上的负载迁移到包年包月节点。
- 资源整合:逐步将负载从一类节点迁移到另一类节点,以便源节点可以安全缩容、维护或归还。
- 分层节点池:在多个节点池之间强制保持严格顺序,让负载随时间“下沉”到低优先级层级。
插件在每个重调度周期中执行以下步骤:
- 根据
evictionOrder中定义的顺序将集群中的所有节点分组,每个节点仅分配到第一个匹配的优先级层级。 - 从最高优先级层级(列表中的第一项)开始,将其作为源池,其余所有较低优先级层级共同构成目标池候选。
- 对于源节点上的每个 Pod,应用 namespace /
podSelector/ Evictor 过滤器,并按 CPU 与内存 request 升序对待驱逐的候选 Pod 进行排序。 - 根据
mode执行驱逐策略:BestEffort(默认 —— 只要单个目标节点能够容纳即可逐个驱逐 Pod)或DrainNode(仅当源节点上所有候选 Pod 都能装入目标池时才驱逐,可选择通过autoCordon自动封锁该节点)。 - 实际的 Pod 驱逐由
Evictor异步执行,遵守所有限流与安全机制。
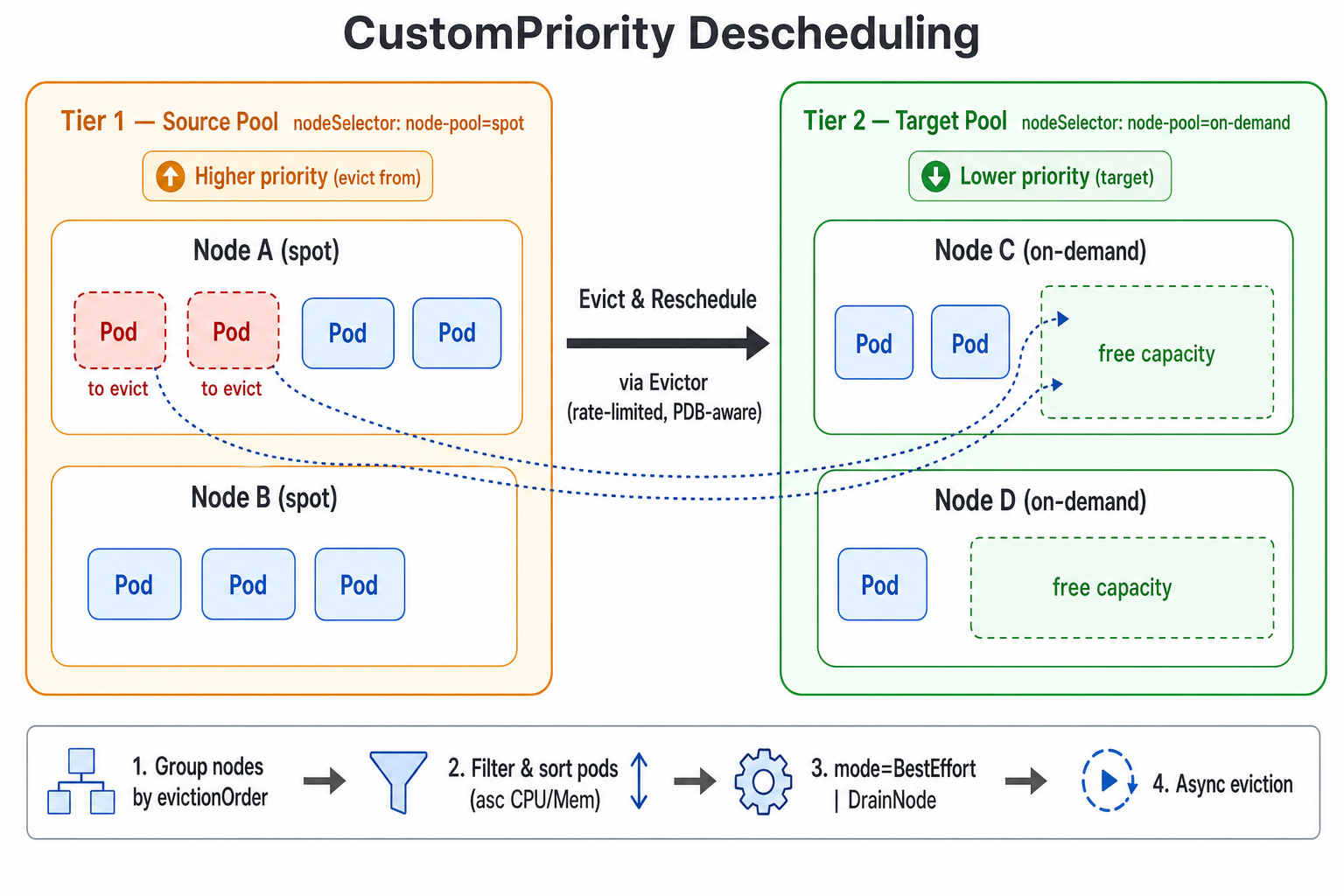
更多信息请参考 基于自定义优先级的重调度。
6. 可观测性:调度器与重调度器 Grafana 仪表盘
v1.8.0 提供了一组精心编排的 Grafana 仪表盘,覆盖 koord-scheduler 与 koord-descheduler 的调度吞吐、队列延迟、插件耗时、抢占行为、重调度驱逐等指标。结合 Helm Chart 中新增的 PodMonitor 参数,用户可以通过一行 Helm 参数开启生产级可观测能力:
helm install koordinator koordinator-sh/koordinator --version 1.8.0 \
--set scheduler.monitorEnabled=true \
--set descheduler.monitorEnabled=true
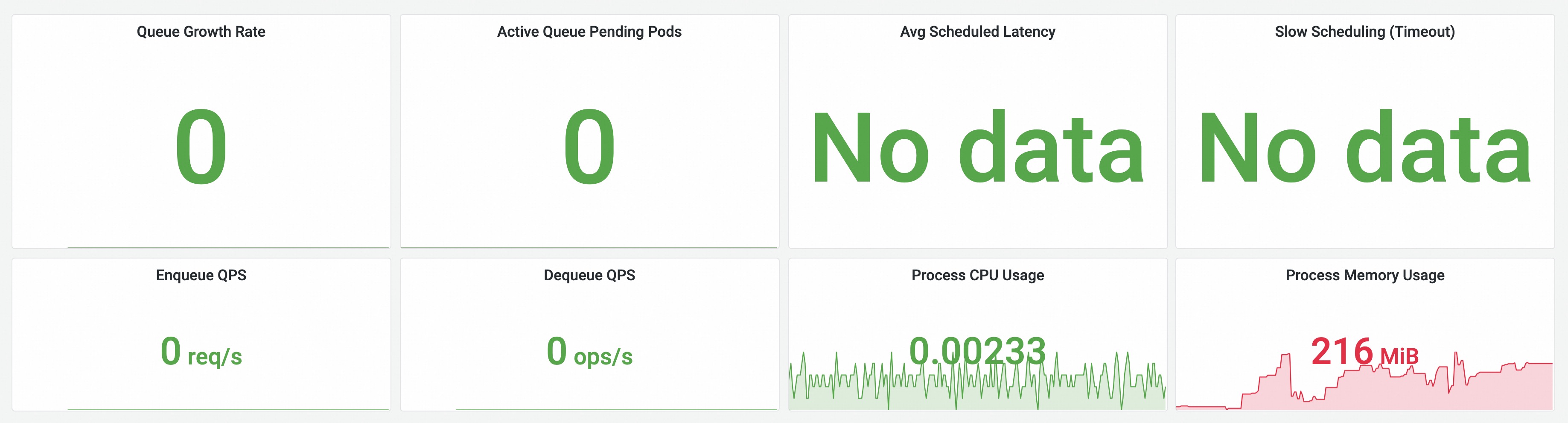
仪表盘示例:
Scheduler Basic Summary —— 展示队列增长速率、待调度 Pod 数、调度延迟、入/出队 QPS 以及调度器进程资源占用,快速综览 koord-scheduler 的健康度与吞吐情况。
Descheduler Eviction Overview —— 包含累计与实时驱逐次数、成功/失败率以及当前驱逐速率,快速展示 koord-descheduler 的运行状态。

7. 平台与兼容性
v1.8.0 在平台层面带来了一系列改进:
- 升级至 Kubernetes 1.35.2:包括 controller-gen 升级到
v0.20.0、以及从k8s.io/utils/pointer迁移到k8s.io/utils/ptr。v1.8 正式支持 Kubernetes 1.24、1.28、1.35。对于 1.22 和 1.20 集群仅部分支持:部分 Koordinator 组件已切换到更新的 Kubernetes API,这些 API 在旧版本集群中不存在,因此相关组件将无法在 1.22/1.20 上使用;核心的混部、QoS 与调度能力仍可正常工作。详情请参考 Kubernetes 兼容性。 - 多调度器 / 多 Profile 加固:对 Reservation、Coscheduling、PreBind、PreBindReservation、ForgetPod 与 FrameworkExtender 等流程进行了大量梳理,使 koord-scheduler 能稳定地与其他调度器共存,或作为备用调度器部署。
- 原生资源使用 Protobuf:
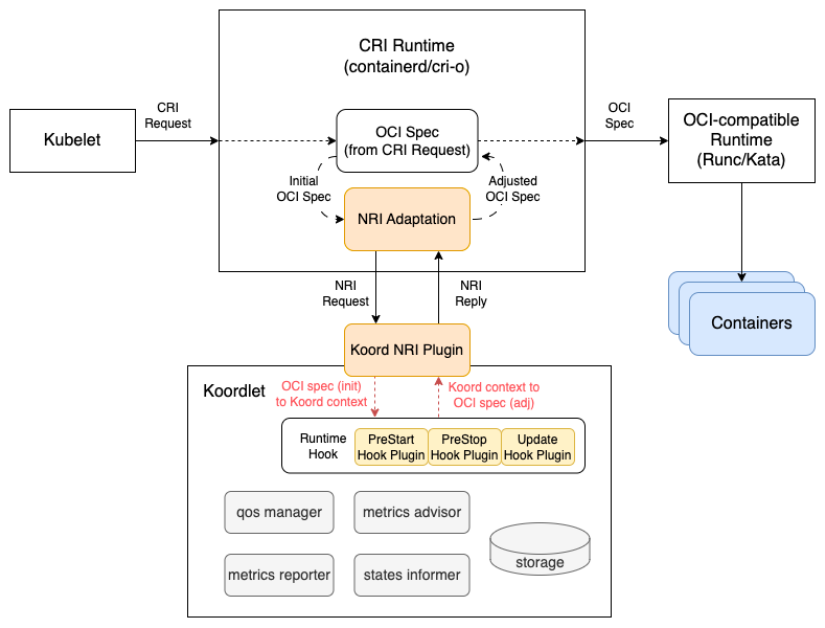
kubeclients在处理核心资源时使用 Protobuf,降低 API Server 的 CPU 开销。 - NRI 升级至 0.11.0,并对 koordlet 的 NRI Server 进行重构。
- Koordlet 改进:Mid 资源支持静态预留模式、支持按 Allocatable 触发驱逐、修复存在 BE Pod 时 BE CPU Suppress 调整
cfs_quota失败的问题、修复容器级cfs_quota解绑问题、新增 cpuset 共享池 CPU 指标、在 GPU 丢失时正确处理 GPU 初始化失败。 - Descheduler 改进:支持跳过 Eviction Gates、修复 AnomalyCondition 检查 Bug、NodePool 继承顶层默认配置、
LowNodeLoad基于 Raw Allocatable 计算阈值(新增的CustomPriority插件详见上文第 5 节)。
贡献者
Koordinator 是一个开源社区。感谢长期参与的维护者与首次贡献的新朋友。我们欢迎更多开发者加入 Koordinator 社区。
New Contributors
- @IULeen made their first contribution in #2595
- @lujinda made their first contribution in #2679
- @hunshcn made their first contribution in #2707
- @summingyu made their first contribution in #2711
- @ikukaku made their first contribution in #2684
- @AutuSnow made their first contribution in #2767
- @PixelPixel00 made their first contribution in #2802
- @106umao made their first contribution in #2819
- @manukasvi made their first contribution in #2815
- @aviralgarg05 made their first contribution in #2838
未来规划
Koordinator 的版本规划主要通过 GitHub Milestone 跟踪。以下事项分别来自即将发布的 v1.8.1 补丁版本以及更长远的 aspirational-26 规划。
近期(v1.8.1)
- 调度器 — 推理编排:基于 Grove 集成的推理编排增强 (#2821)。
- 调度器 — 资源预留:支持按 Spec 更新 Reservation 的规模 (#2859)。
- 调度器 — 诊断与审计:Diagnosis API (#2607);可自定义的抢占诊断 (#2632);调度诊断工具链 (#2669);基于队列优化调度审计 (#2676);优化
failedDetail/alreadyWaitForBound并为解释信息添加 TTL (#2792);工作负载审计器 (#2872);针对 Job/Pod 调度失败给出调度建议 (#2873)。 - 调度器 — 平台化:重构
ForceSyncFromInformer以与原生 kube-scheduler 行为对齐 (#2875);在-logtostderr=true时正确尊重-stderrthreshold(#2874)。 - 重调度器:用于资源不均衡检测与平衡重调度的 Lambda-G 评分函数 (#2837)。
- Koordlet:为 cpuset 共享池的 CPU 信息添加指标 (#2800);修复 CgroupV2 节点上 CPUBurst 触发 cfsScaleDown 的问题 (#2801);内存 NUMA 拓扑对齐 (#2826)。
长远(aspirational-26,计划于 2026 年底前完成)
- 对齐 Kubernetes 1.35 的调度能力 (#2851 — Umbrella):SchedulerQueueingHints (#2852)、非阻塞 API 调用 (#2853)、Opportunistic Batching (#2854)、Gang 调度增强 (#2856)、异步抢占 (#2857)、面向 Expectation 的 NominatedNodeName (#2858)。
- 动态资源分配(DRA):在 koord-scheduler、koord-manager、koord-device-daemon 和 koordlet 中端到端支持 DRA (#2855)。
- 多调度器架构:支持单调度器内多 Profile 之间的状态共享 (#2749);提供多主节点调度器部署文档 (#2758)。
- 排队与作业调度:JobNomination 机制 (#2803);基于 Koordinator Reservation 优化 Kueue AdmissionCheck (#2754);koord-queue 中面向 DAG 型工作流(如 Argo)的资源预估策略 (#2786)。
- 重调度与资源平衡:针对单节点上不同资源类型不均衡的重调度 (#2332);缩容 binpack 策略 (#2790)。
- QoS 与 Koordlet:基于 PSI 的 QoS Reconciler (#2463);Pod 级 CPU Burst 策略以支持更精细的控制 (#2557);内存 NUMA 拓扑对齐提案 (#2590);确保 Pod 所依赖的 NRI Hook 符合预期 (#2579);支持驱逐 YARN 容器 (#2464)。
- 调度诊断:持续增强调度器在 Pod 调度异常时的排查能力 (#2348)。
我们欢迎用户反馈使用体验,也欢迎更多开发者参与到 Koordinator 项目中,共同推动其发展!
致谢
自开源以来,Koordinator 已发布 16+ 个版本,累计 120+ 位贡献者。社区持续壮大,感谢所有社区成员的积极参与和宝贵反馈,也感谢 CNCF 及相关社区成员对项目的支持。
欢迎更多开发者和终端用户 加入我们!无论您是云原生领域的新手还是专家,我们都期待您的声音!
完整变更日志请参考 v1.8.0 Release。
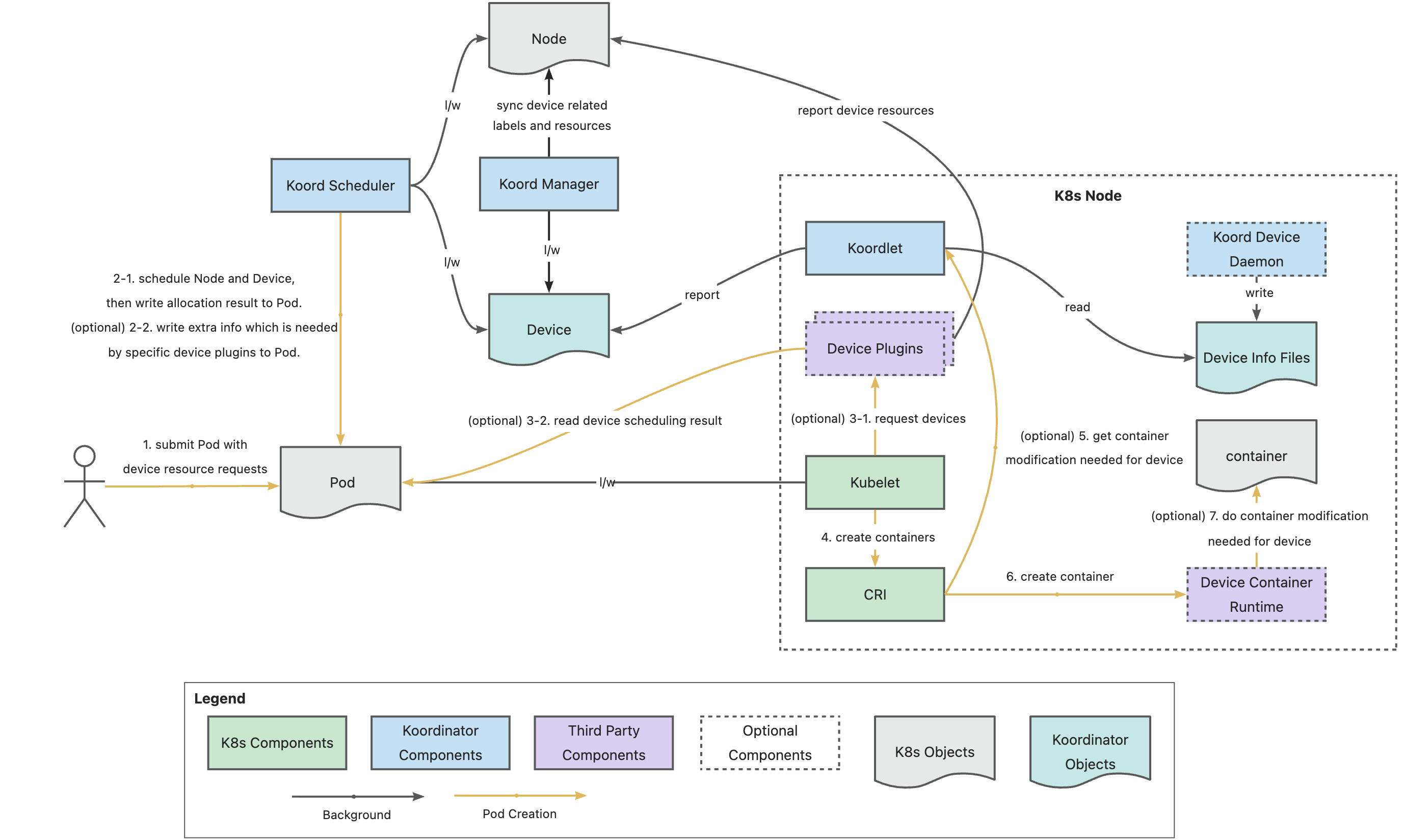
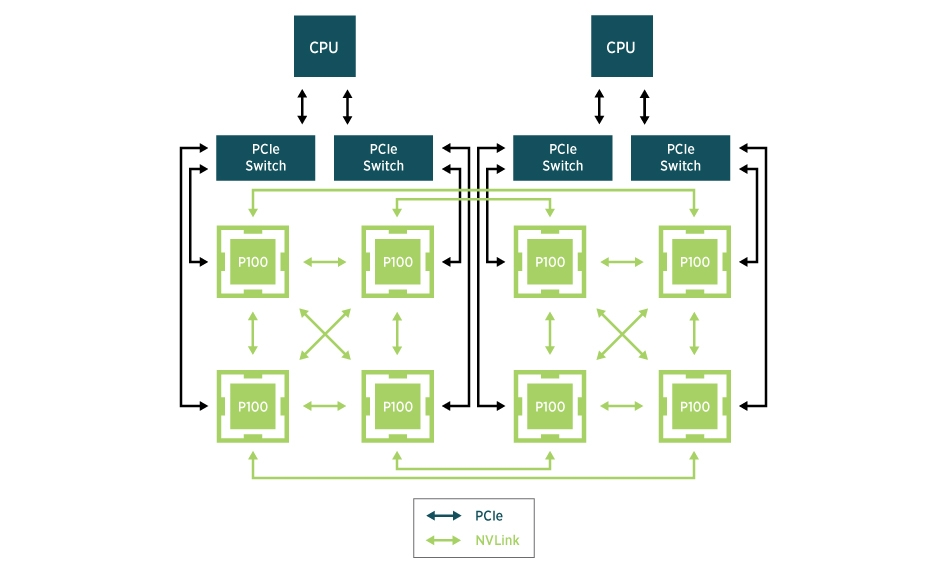
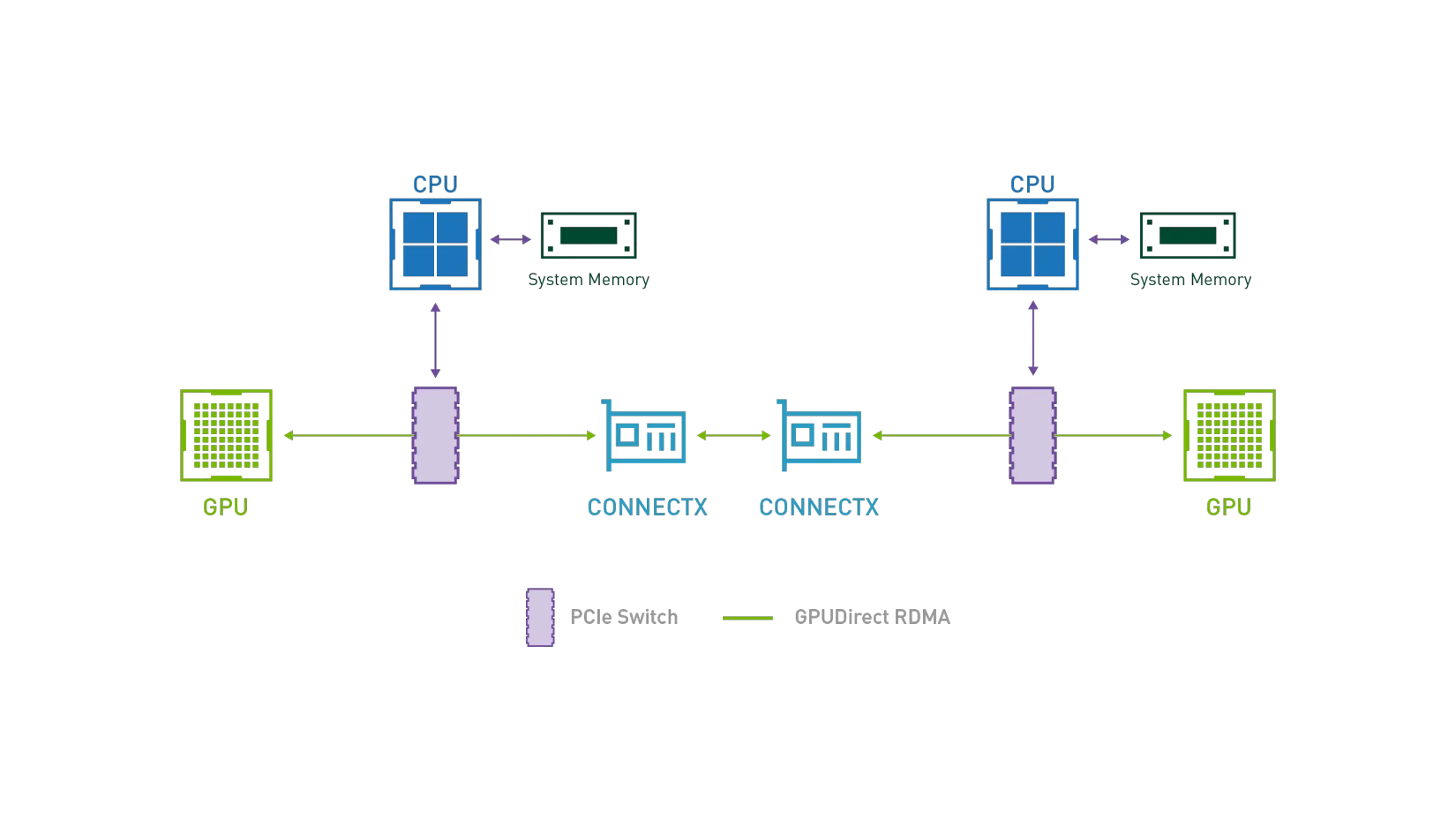 在 AI 模型训练场景中,GPU 之间需要进行频繁的集合通信,以同步训练过程迭代更新的权重。GDR 全称叫做 GPUDirect RDMA,其目的是解决多机 GPU 设备之间交换数据的效率问题。通过 GDR 技术多机之间 GPU 交换数据可以不经过 CPU 和内存,大幅节省 CPU/Memory 开销同时降低延时。为了实现这一目标,Koordinator v1.6.0 版本中设计实现了 GPU/RDMA 设备联合调度特性,整体架构如下:
在 AI 模型训练场景中,GPU 之间需要进行频繁的集合通信,以同步训练过程迭代更新的权重。GDR 全称叫做 GPUDirect RDMA,其目的是解决多机 GPU 设备之间交换数据的效率问题。通过 GDR 技术多机之间 GPU 交换数据可以不经过 CPU 和内存,大幅节省 CPU/Memory 开销同时降低延时。为了实现这一目标,Koordinator v1.6.0 版本中设计实现了 GPU/RDMA 设备联合调度特性,整体架构如下: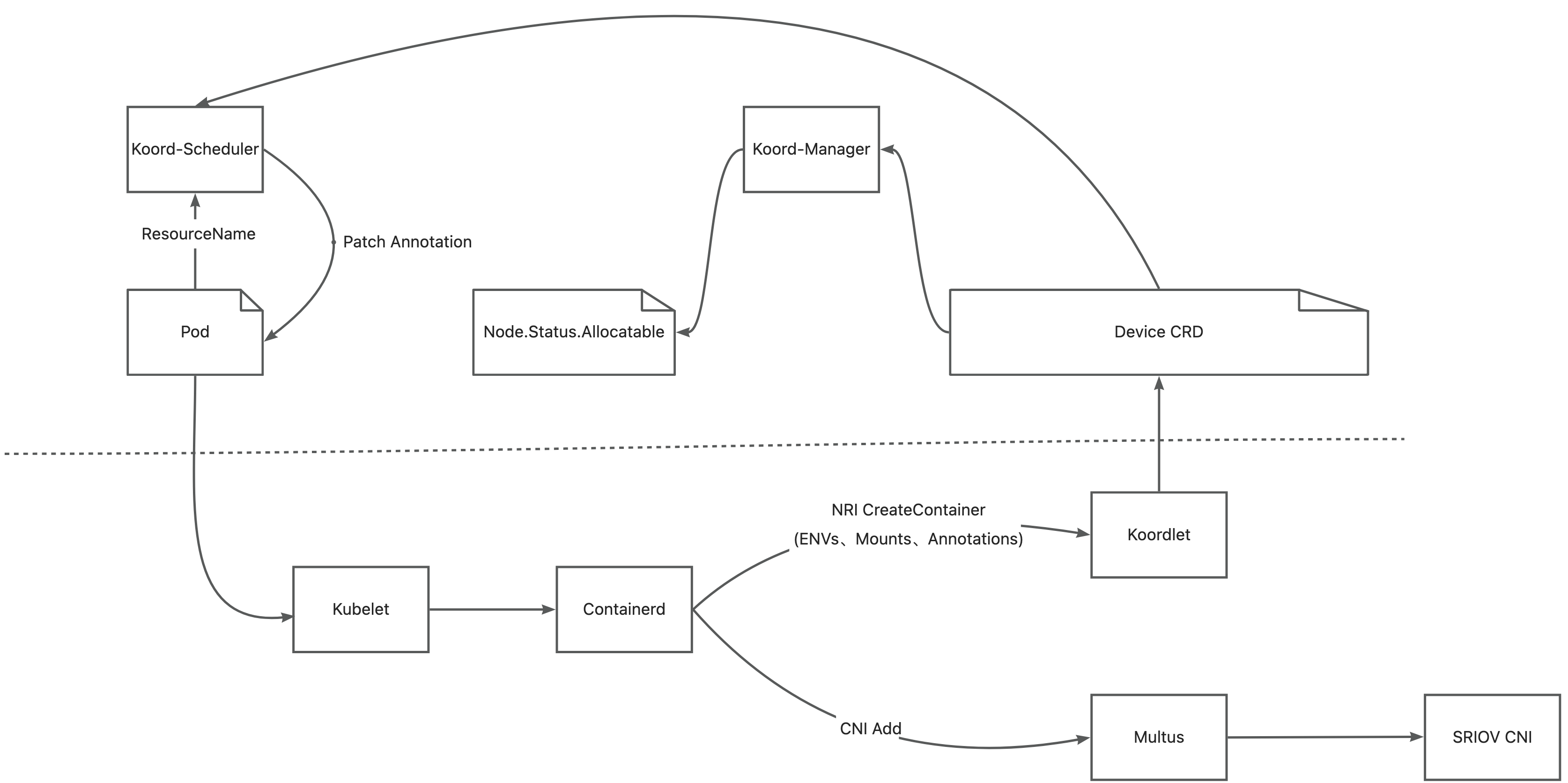
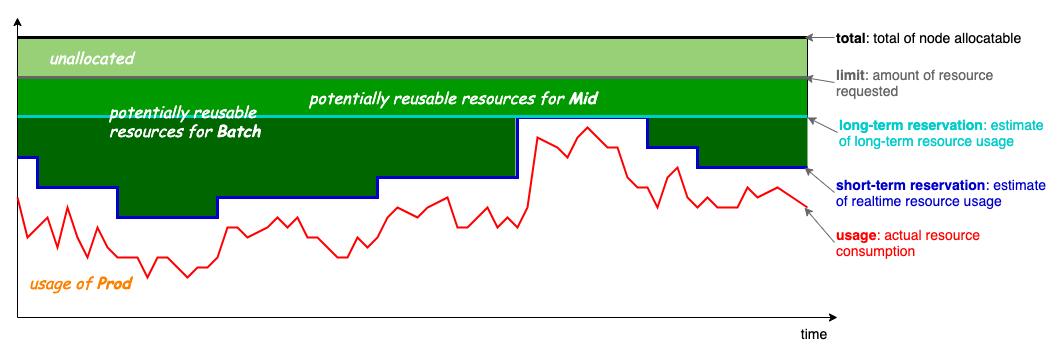 在 v1.6 版本中,Koordinator 更新了超卖计算公式,如下:
在 v1.6 版本中,Koordinator 更新了超卖计算公式,如下: 投票地址:
投票地址: