Enhanced NodeResourceFit
Introduction
The NodeResourcesFit plugin of native k8s can only adopt a type of strategy for all resources, such as MostRequestedPriority and LeastRequestedPriority. However, in industrial practice, this design does not apply to some scenarios. For example:
- In AI scenarios, pods that apply for GPUs prefer to occupy the entire GPU machine first to prevent GPU fragmentation.
- Pods that apply for CPU and memory are prioritized and dispersed to non-GPU machines to prevent excessive consumption of CPU and memory on GPU machines, resulting in real tasks that require GPUs pending due to insufficient non-GPU resources.
It is therefore hoped that both strategies can be provided to address this business need. Koordinator provides the NodeResourcesFitPlus and ScarceResourceAvoidance plugins to support the requirements of these two scenarios, thereby:
- Different types of resources can be configured with different strategies to prioritize them in the form of weights
- Prevent pods that have not applied for scarce resources from being scheduled to nodes with scarce resources.
Plugin Logic Explanation
NodeResourcesFitPlus
The scheduler args for the NodeResourcesFitPlus plugin can be configured as follows:
resources:
nvidia.com/gpu:
type: MostAllocated
weight: 2
cpu:
type: LeastAllocated
weight: 1
memory:
type: LeastAllocated
weight: 1
The two strategies have the following score calculation methods and effects:
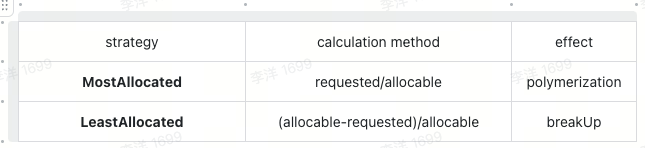
The final node score can be calculated as follows:
finalScoreNode = [(weight1 * resource1) + (weight2 * resource2) + … + (weightN* resourceN)] /(weight1+weight2+ … +weightN)
ScarceResourceAvoidance
The scheduler args for the ScarceResourceAvoidance plugin can be configured as follows:
resources:
- nvidia.com/gpu
- scarceResource1
- scarceResource2
After obtaining scarce resource types from the config, the plugin will score the node and Pod fitness as follows:
- Obtain the set of resource types requested by the pod and the set of resource types that the node can allocate.
- ResourceTypesUnused = ResourceTypesTotal - ResourceTypesRequested
- ScarceResourceTypesUnused = intersection(ResourceTypesUnused, ScarceResourceTypes)
The more unused scarce resource types, the lower the score will be.
Example
SchedulerConfiguration Example
We can configure schedulerConfiguration as follows:
profiles:
- pluginConfig:
- args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: NodeResourcesFitPlusArgs
resources:
nvidia.com/gpu:
type: MostAllocated
weight: 2
cpu:
type: LeastAllocated
weight: 1
memory:
type: LeastAllocated
weight: 1
name: NodeResourcesFitPlus
- args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: ScarceResourceAvoidanceArgs
resources:
- nvidia.com/gpu
name: ScarceResourceAvoidance
plugins:
score:
enabled:
- name: NodeResourcesFitPlus
weight: 2
- name: ScarceResourceAvoidance
weight: 2
disabled:
- name: "*"
schedulerName: koord-scheduler
GPU Applications And Node Score
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-scheduler1
spec:
replicas: 1
selector:
matchLabels:
app: test-scheduler1
template:
metadata:
labels:
app: test-scheduler1
spec:
schedulerName: koord-scheduler
containers:
- image: dockerpull.com/nginx
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
resources:
requests:
cpu: "100"
memory: "100"
nvidia.com/gpu: 2
limits:
cpu: "100"
memory: "100"
nvidia.com/gpu: 2
Node allocation rate information
node1: cpu 58%, memory 21%, nvidia.com/gpu 6 (total 8)
node2: cpu 22%, memory 5%, nvidia.com/gpu 0 (total 8)
Result: Prioritize GPU machines and pool GPU resources
Log view => Top10 scores for pod
| # | Pod | Node | Score | NodeResourcesFitPlus | ScarceResourceAvoidance |
| 0 | test-scheduler1-xxx | node1 | 358 | 158 | 200 |
| 1 | test-scheduler1-xxx | node2 | 296 | 96 | 200 |
CPU Applications And Node Score
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-scheduler1
spec:
replicas: 1
selector:
matchLabels:
app: test-scheduler1
template:
metadata:
labels:
app: test-scheduler1
spec:
schedulerName: koord-scheduler
containers:
- image: dockerpull.com/nginx
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
resources:
requests:
cpu: "100"
memory: "100"
limits:
cpu: "100"
memory: "100"
Node allocation rate information
node1: cpu 22%, memory 10%, nvidia.com/gpu 6 (total 8)
node2: cpu 40%, memory 50%
node3: cpu 30%, memory 20%
Result: Prioritize CPU machines and disperse CPU and MEM resources
Log view => Top10 scores for pod
| # | Pod | Node | Score | NodeResourcesFitPlus | ScarceResourceAvoidance |
| 0 | test-scheduler1-xxx | node1 | 310 | 144 | 166 |
| 1 | test-scheduler1-xxx | node2 | 262 | 62 | 200 |
| 2 | test-scheduler1-xxx | node3 | 326 | 126 | 200 |
Compatible With Native NodeResourceFit
MostAllocated
native configuration:
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: kube-system
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: koord-scheduler
pluginConfig:
- args:
scoringStrategy:
resources:
- name: cpu
weight: 2
- name: memory
weight: 1
type: MostAllocated
name: NodeResourcesFit
plugins:
score:
enabled:
- name: "NodeResourcesFit"
NodeResourcesFitPlus configuration:
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: kube-system
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: koord-scheduler
pluginConfig:
- args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: NodeResourcesFitPlusArgs
resources:
cpu:
type: MostAllocated
weight: 2
memory:
type: MostAllocated
weight: 1
name: NodeResourcesFitPlus
plugins:
score:
enabled:
- name: "NodeResourcesFitPlus"
LeastAllocated
native configuration:
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: kube-system
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: koord-scheduler
pluginConfig:
- args:
scoringStrategy:
resources:
- name: cpu
weight: 2
- name: memory
weight: 1
type: LeastAllocated
name: NodeResourcesFit
plugins:
score:
enabled:
- name: "NodeResourcesFit"
NodeResourcesFitPlus configuration:
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: kube-system
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: koord-scheduler
pluginConfig:
- args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: NodeResourcesFitPlus
resources:
cpu:
type: LeastAllocated
weight: 2
memory:
type: LeastAllocated
weight: 1
name: NodeResourcesFitPlus
plugins:
score:
enabled:
- name: "NodeResourcesFitPlus"