Batch 混部调度快速入门指南
本指南帮助社区新人快速理解和部署 Koordinator 的 Batch 混部调度能力。我们将以深入浅出的方式介绍核心概念、部署过程和重要注意事项。
什么是 Batch 混部?
Batch 混部是一种将批处理工作负载(如数据分析、机器学习训练、离线任务)与延迟敏感型应用(如 Web 服务、微服务)运行在同一 Kubernetes 集群的技术。通过利用在线服务的空闲资源,可以在保证服务质量的同时显著提高集群资源利用率。
为什么需要 Batch 混部?
在典型的 Kubernetes 集群中:
- 在线服务 基于峰值流量请求资源(CPU、内存),但实际使用率通常远低于此
- 空闲资源 已经分配但大部分时间未被使用
- 集群利用率 通常很低(20-40%)
Koordinator 可以帮助你:
- 回收 在线服务的空闲资源
- 运行 Batch 作业 使用这些回收的资源
- 提高利用率 至 50-80%,同时保证服务质量
核心概念
1. QoS 分类
Koordinator 为不同类型的工作负载定义了五种 QoS(服务质量)等级:
| QoS 等级 | 使用场景 | 资源保证 | 典型工作负载 |
|---|---|---|---|
| SYSTEM | 系统服务 | 有限但保证 | DaemonSets、系统进程 |
| LSE | 独占延迟敏感 | 预留、隔离 | 中间件(较少使用) |
| LSR | 预留延迟敏感 | CPU 核心预留 | 核心在线服务 |
| LS | 共享延迟敏感 | 共享,支持突发 | 典型微服务 |
| BE | 尽力而为 | 无保证,可被限流/驱逐 | 批处理作业 ⭐ |
对于具备批处理特征的工作负载,你主要使用 BE (Best Effort) QoS 等级。
2. 优先级类别
Koordinator 在 Kubernetes PriorityClass 基础上扩展了四个优先级:
| PriorityClass | 优先级范围 | 描述 | 用于 Batch? |
|---|---|---|---|
koord-prod | [9000, 9999] | 生产级,保证配额 | ❌ 否 |
koord-mid | [7000, 7999] | 中等优先级,保证配额 | ❌ 否 |
koord-batch | [5000, 5999] | 批处理负载,允许借用 | ✅ 是 |
koord-free | [3000, 3999] | 免费资源,无保证 | ✅ 可选 |
对于大多数批处理工作负载,使用 koord-batch 优先级类别。
3. 资源模型
Koordinator 的混部模型工作原理如下:
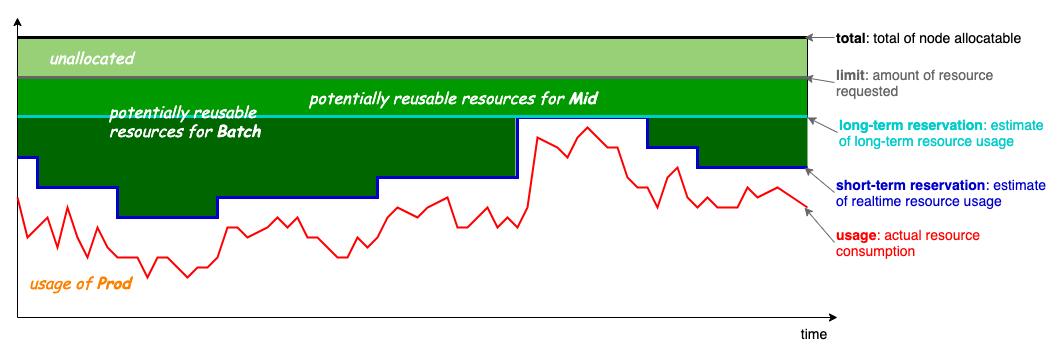
- Limit: 高优先级 Pod (LS/LSR)请求的资源
- Usage: 实际使用的资源(随时间变化)
- 可回收资源: Usage 和 Limit 之间的资源 - 可供 BE Pod 使用
- BE Pods: 使用可回收资源运行
关键点: 批处理作业(BE)使用原本会被浪费的空闲资源,不会影响在线服务性能。
4. 资源类型
Koordinator 为批处理工作负载引入了特殊的资源类型:
| 资源类型 | 描述 | 在 Pod 规格中使用 |
|---|---|---|
kubernetes.io/batch-cpu | Batch 工作负载的 CPU | ✅ 必需 |
kubernetes.io/batch-memory | Batch 工作负载的内存 | ✅ 必需 |
这些资源从集群的可回收资源池中分配。
前置条件
开始之前,请确保你有:
- Kubernetes 集群(版本 >= 1.18)
- kubectl 已配置可访问你的集群
- Helm(版本 >= 3.5) - 安装 Helm
- (推荐)Linux 内核版本 >= 4.19 以获得最佳性能
安装部署
步骤 1: 安装 Koordinator
添加 Koordinator Helm 仓库:
helm repo add koordinator-sh https://koordinator-sh.github.io/charts/
helm repo update
安装 Koordinator(最新稳定版本):
helm install koordinator koordinator-sh/koordinator --version 1.6.0
验证安装:
kubectl get pod -n koordinator-system
预期输出(所有 Pod 都应该是 Running 状态):
NAME READY STATUS RESTARTS AGE
koord-descheduler-xxx 1/1 Running 0 2m
koord-manager-xxx 1/1 Running 0 2m
koord-manager-xxx 1/1 Running 0 2m
koord-scheduler-xxx 1/1 Running 0 2m
koord-scheduler-xxx 1/1 Running 0 2m
koordlet-xxx 1/1 Running 0 2m
koordlet-xxx 1/1 Running 0 2m
步骤 2: 验证优先级类别
检查 Koordinator PriorityClass 是否已创建:
kubectl get priorityclass | grep koord
预期输出:
koord-batch 5000 false 10m
koord-free 3000 false 10m
koord-mid 7000 false 10m
koord-prod 9000 false 10m
运行你的第一个 Batch 工作负载
方法 1: 使用 ClusterColocationProfile (推荐)
ClusterColocationProfile 可以根据标签自动向 Pod 注入混部配置。这是 Batch 工作负载最简单的方式。
步骤 1: 创建命名空间
kubectl create namespace batch-demo
kubectl label namespace batch-demo koordinator.sh/enable-colocation=true
步骤 2: 创建 ClusterColocationProfile
创建 batch-colocation-profile.yaml:
apiVersion: config.koordinator.sh/v1alpha1
kind: ClusterColocationProfile
metadata:
name: batch-workload-profile
spec:
# 匹配带标签的命名空间
namespaceSelector:
matchLabels:
koordinator.sh/enable-colocation: "true"
# 匹配带标签的 Pod
selector:
matchLabels:
app-type: batch
# 为 Batch 工作负载设置 QoS 为 BE
qosClass: BE
# 设置优先级类别
priorityClassName: koord-batch
# 使用 Koordinator 调度器
schedulerName: koord-scheduler
# 添加标签用于跟踪
labels:
koordinator.sh/mutated: "true"
应用配置:
kubectl apply -f batch-colocation-profile.yaml
步骤 3: 创建批处理作业
创建 batch-job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: data-processing-job
namespace: batch-demo
spec:
completions: 1
template:
metadata:
labels:
app-type: batch # 这个标签会触发 Profile
spec:
containers:
- name: worker
image: python:3.9
command:
- python
- -c
- |
import time
import random
print("开始数据处理...")
for i in range(60):
# 模拟数据处理
time.sleep(1)
print(f"处理批次 {i+1}/60...")
print("作业完成!")
resources:
requests:
cpu: "2" # 将被转换为 batch-cpu
memory: "4Gi" # 将被转换为 batch-memory
limits:
cpu: "2"
memory: "4Gi"
restartPolicy: Never
应用作业:
kubectl apply -f batch-job.yaml
步骤 4: 验证配置
检查 Pod 是否已正确配置:
kubectl get pod -n batch-demo -l app-type=batch -o yaml
你应该看到自动注入的混部配置:
metadata:
labels:
koordinator.sh/qosClass: BE # ✅ QoS 已注入
koordinator.sh/mutated: "true" # ✅ Profile 已应用
spec:
priorityClassName: koord-batch # ✅ 优先级已设置
schedulerName: koord-scheduler # ✅ 使用 Koordinator 调度器
containers:
- name: worker
resources:
limits:
kubernetes.io/batch-cpu: "2000" # ✅ 转换为 Batch 资源
kubernetes.io/batch-memory: "4Gi"
requests:
kubernetes.io/batch-cpu: "2000"
kubernetes.io/batch-memory: "4Gi"
方法 2: 手动配置
如果你不想使用 ClusterColocationProfile,可以显式配置:
创建 manual-batch-job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: manual-batch-job
namespace: batch-demo
spec:
completions: 1
template:
metadata:
labels:
koordinator.sh/qosClass: BE # 显式设置 QoS
spec:
priorityClassName: koord-batch # 显式设置优先级
schedulerName: koord-scheduler # 使用 Koordinator 调度器
containers:
- name: worker
image: python:3.9
command: ["python", "-c", "print('你好,来自批处理作业'); import time; time.sleep(30)"]
resources:
requests:
kubernetes.io/batch-cpu: "1000" # 使用 Batch 资源
kubernetes.io/batch-memory: "2Gi"
limits:
kubernetes.io/batch-cpu: "1000"
kubernetes.io/batch-memory: "2Gi"
restartPolicy: Never
应用作业:
kubectl apply -f manual-batch-job.yaml
监控和验证
检查节点资源
查看节点资源分配:
kubectl get node -o yaml | grep -A 10 "allocatable:"
你应该看到可用的 Batch 资源:
allocatable:
cpu: "8"
memory: "16Gi"
kubernetes.io/batch-cpu: "15000" # 批处理 CPU 可用
kubernetes.io/batch-memory: "20Gi" # 批处理内存可用
监控资源使用
检查实际资源使用情况:
kubectl top nodes
kubectl top pods -n batch-demo
检查节点指标
Koordinator 创建 NodeMetric 资源,包含详细指标:
kubectl get nodemetric -o yaml
这显示了实时资源使用情况,帮助 Koordinator 做出调度决策。
重要注意事项
1. 资源限制
应该这样做:
- ✅ 始终为批处理工作负载设置
requests和limits - ✅ 使用真实的资源估算
- ✅ 设置
requests == limits以获得可预测的行为
不要这样做:
- ❌ 不要过度请求你不需要的资源
- ❌ 不要省略资源规格
2. QoS 保证
理解 BE QoS 的行为:
- CPU: BE Pod 获得剩余的 CPU 周期;当 LS Pod 需要资源时可能被限流
- Memory: 如果发生内存压力,BE Pod 可能被驱逐
- Priority: BE Pod 在高优先级 Pod 之后调度
3. 工作负载适用性
适合批处理混部的场景:
- ✅ 数据处理作业
- ✅ 机器学习训练
- ✅ 批量分析
- ✅ 视频转码
- ✅ 日志处理
- ✅ ETL 作业
不适合的场景:
- ❌ 延迟敏感服务
- ❌ 实时处理
- ❌ 需要保证完成时间的作业
- ❌ 有严格 SLA 的有状态服务
4. 故障处理
批处理作业可能会:
- 被限流: 当高优先级 Pod 需要 CPU 时
- 被驱逐: 在内存压力期间
设计你的批处理工作负载以处理:
- 检查点: 定期保存进度
- 重试逻辑: 使用 Job 的
backoffLimit和restartPolicy - 幂等性: 确保作业可以安全重启
带重试的示例:
apiVersion: batch/v1
kind: Job
metadata:
name: resilient-batch-job
namespace: batch-demo
spec:
backoffLimit: 3 # 最多重试 3 次
completions: 1
template:
metadata:
labels:
app-type: batch
spec:
restartPolicy: OnFailure # 失败时重试
containers:
- name: worker
image: your-batch-image
# ... 其他配置
5. 调度器配置
对于批处理工作负载,请确保使用 Koordinator 调度器:
spec:
schedulerName: koord-scheduler # Batch 资源调度所必需
如果不设置这个,Pod 将使用默认的 Kubernetes 调度器,无法享受混部功能的好处。
6. 命名空间隔离(可选)
为了更好地组织,可以为批处理工作负载专门划分命名空间:
# 创建批处理命名空间
kubectl create namespace batch-workloads
# 标记为混部
kubectl label namespace batch-workloads koordinator.sh/enable-colocation=true
# 为此命名空间创建 Profile
kubectl apply -f batch-colocation-profile.yaml
常见模式
模式 1: 数据处理流水线
apiVersion: batch/v1
kind: Job
metadata:
name: data-pipeline
namespace: batch-demo
spec:
completions: 5 # 处理 5 个批次
parallelism: 2 # 同时运行 2 个
template:
metadata:
labels:
app-type: batch
spec:
containers:
- name: processor
image: data-processor:latest
resources:
requests:
cpu: "4"
memory: "8Gi"
limits:
cpu: "4"
memory: "8Gi"
restartPolicy: OnFailure
模式 2: 定时批处理的 CronJob
apiVersion: batch/v1
kind: CronJob
metadata:
name: nightly-report
namespace: batch-demo
spec:
schedule: "0 2 * * *" # 每天凌晨 2 点运行
jobTemplate:
spec:
template:
metadata:
labels:
app-type: batch
spec:
containers:
- name: report-generator
image: report-gen:latest
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "2"
memory: "4Gi"
restartPolicy: OnFailure
故障排查
问题 1: Pod 一直处于 Pending 状态
症状: 批处理 Pod 保持 Pending 状态
检查:
kubectl describe pod <pod-name> -n batch-demo
常见原因:
- 可用 Batch 资源不足
- 节点选择器约束
- 资源请求过高
解决方案: 检查节点可分配资源,如需要降低请求量。
问题 2: Pod 频繁被驱逐
症状: 批处理 Pod 经常被驱逐
检查:
kubectl get events -n batch-demo --sort-by='.lastTimestamp'
常见原因:
- 节点内存压力
- 高优先级 Pod 需要资源
- 资源超卖过于激进
解决方案:
- 减少内存请求
- 使用检查点处理驱逐
- 调整 Koordinator 资源预留设置(高级)
问题 3: Batch 资源不可用
症状: 节点上没有 kubernetes.io/batch-cpu 资源
检查:
kubectl get nodemetric -o yaml
kubectl get pod -n koordinator-system
解决方案:
- 确保 Koordlet 在所有节点上运行
- 检查 Koordlet 日志:
kubectl logs -n koordinator-system koordlet-xxx - 验证节点有可分配资源
下一步
成功运行批处理工作负载后,你可以探索:
高级调度:
资源管理:
- CPU QoS - 微调 CPU 保证
- Memory QoS - 控制内存行为
- 资源预留 - 为特定工作负载预留资源
监控:
其他批处理框架:
总结
在本指南中,你学习了:
- ✅ 核心概念: QoS 分类、优先级、资源模型
- ✅ 如何安装 Koordinator
- ✅ 运行批处理工作负载的两种方法(ClusterColocationProfile 和手动)
- ✅ 生产使用的重要注意事项
- ✅ 常见模式和故障排查
关键要点:
- 对批处理工作负载使用 BE QoS 和 koord-batch 优先级
- 利用 ClusterColocationProfile 简化配置
- 设计时考虑驱逐和限流,使用重试和检查点
- 监控资源使用并根据需要调整
从简单的批处理作业开始,随着对 Koordinator 行为的熟悉,逐步增加复杂性!