Job
Job 调度
必须一起调度的一批 Pod 称为 Job。
PodGroup
有时,这批 Pod 是完全同质的,只需要累积到指定的最小数量即可成功调度。在这种情况下,我们可以通过单独的 PodGroup 描述 minMember,然后通过 Pod Label 关联其 member Pod。以下是一个最小累积数量为 2 的 PodGroup 及其 member Pod。
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: gang-example
namespace: default
spec:
minMember: 2
apiVersion: v1
kind: pod
metadata:
name: pod-example1
namespace: default
labels:
pod-group.scheduling.sigs.k8s.io: gang-example
spec:
schedulerName: koord-scheduler
...
---
apiVersion: v1
kind: pod
metadata:
name: pod-example2
namespace: default
labels:
pod-group.scheduling.sigs.k8s.io: gang-example
spec:
schedulerName: koord-scheduler
...
GangGroup
在其他情况下,必须一起调度的 Pod 可能不是同质的,必须分别完成最小数量的累积。在这种情况下,Koordinator 支持通过 PodGroup Label 关联不同的 PodGroup 以形成 GangGroup。以下是一个包含两个 PodGroup 的 GangGroup:
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: gang-example1
namespace: default
annotations:
gang.scheduling.koordinator.sh/groups: "[\"default/gang-example1\", \"default/gang-example2\"]"
spec:
minMember: 1
---
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: gang-example2
namespace: default
annotations:
gang.scheduling.koordinator.sh/groups: "[\"default/gang-example1\", \"default/gang-example2\"]"
spec:
minMember: 2
Job 级别抢占
当 Pod 由于资源不足而无法调度时,Kube-Scheduler 会尝试驱逐低优先级 Pod 以为其腾出空间。这是传统的 Pod 级别抢占。然而,当 Job 由于资源不足而无法调度时,调度器必须为整个 Job 的调度腾出足够的空间。这种类型的抢占称为 Job 级别抢占。
抢占算法
发起抢占的作业称为 抢占者(preemptor),被抢占的 Pod 称为 受害者(victim)。Job 级别抢占的整体工作流程如下:
- 不可调度的 Pod → 进入 PostFilter 阶段
- 是否是 Job? → 是 → 获取所有成员 Pod
- 检查 Job 抢占资格:
pods.spec.preemptionPolicy≠ Never- 所有成员 Pod 当前提名的节点上没有正在终止的受害者(防止冗余抢占)
- 查找抢占可能有帮助的候选节点
- 执行预演以模拟删除潜在受害者(低优先级 Pod)
- 选择最优节点 + 最小成本受害者集(作业感知成本模型)
- 执行抢占:
- 删除受害者(通过设置 DisruptionTarget 条件并调用删除 API)
- 清除目标节点上其他低优先级提名 Pod 的
status.nominatedNode。 - 为所有成员 Pod 设置
status.nominatedNode。
- 抢占成功 → Pod 进入调度队列,等待受害者终止。
受害者的抢占原因
当受害者被抢占时,Koord-Scheduler 会在 victim.status.conditions 中添加一个条目,以指示哪个作业抢占了它并触发优雅终止。
apiVersion: v1
kind: pod
metadata:
name: victim-1
namespace: default
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2025-09-17T08:41:35Z"
message: 'koord-scheduler: preempting to accommodate higher priority pods, preemptor:
default/hello-job, triggerpod: default/preemptor-pod-2'
reason: PreemptionByScheduler
status: "True"
type: DisruptionTarget
上面显示 default/victim-1 被高优先级作业 hello-job 抢占。可以通过以下命令检索 hello-job 的成员 Pod:
$ kubectl get po -n default -l pod-group.scheduling.sigs.k8s.io=hello-job
hello-job-pod-1 0/1 Pending 0 5m
hello-job-pod-2 0/1 Pending 0 5m
抢占者的提名节点
Job 抢占成功后,除了驱逐受害 Pod 外,调度器还必须在其内部缓存中预留回收的资源。在 Kubernetes 中,这是使用 pod.status.nominatedNode 实现的。在 Koordinator 中,koord-scheduler 为抢占作业的所有成员 Pod 设置 .status.nominatedNode 字段以反映此资源预留。
apiVersion: v1
kind: pod
metadata:
name: preemptor-pod-1
namespace: default
labels:
pod-group.scheduling.sigs.k8s.io: hello-job
status:
nominatednodeName: example-node
phase: Pending
---
apiVersion: v1
kind: pod
metadata:
name: preemptor-pod-2
namespace: default
labels:
pod-group.scheduling.sigs.k8s.io: hello-job
status:
nominatednodeName: example-node
phase: Pending
上面显示 hello-job 的两个 Pod 已成功完成抢占,并被提名调度到 example-node。
网络拓扑感知
在大规模 AI 训练场景中,尤其是大语言模型(LLM)训练,高效的 Pod 间通信对训练性能至关重要。模型并行技术,如张量并行(TP)、流水线并行(PP)和数据并行(DP),需要在 GPU 之间进行频繁的高带宽数据交换——通常跨越多个节点。在这些工作负载下,网络拓扑成为关键的性能瓶颈,通信延迟和带宽受物理网络层次结构(如 NVLink、block、spine)的严重影响。
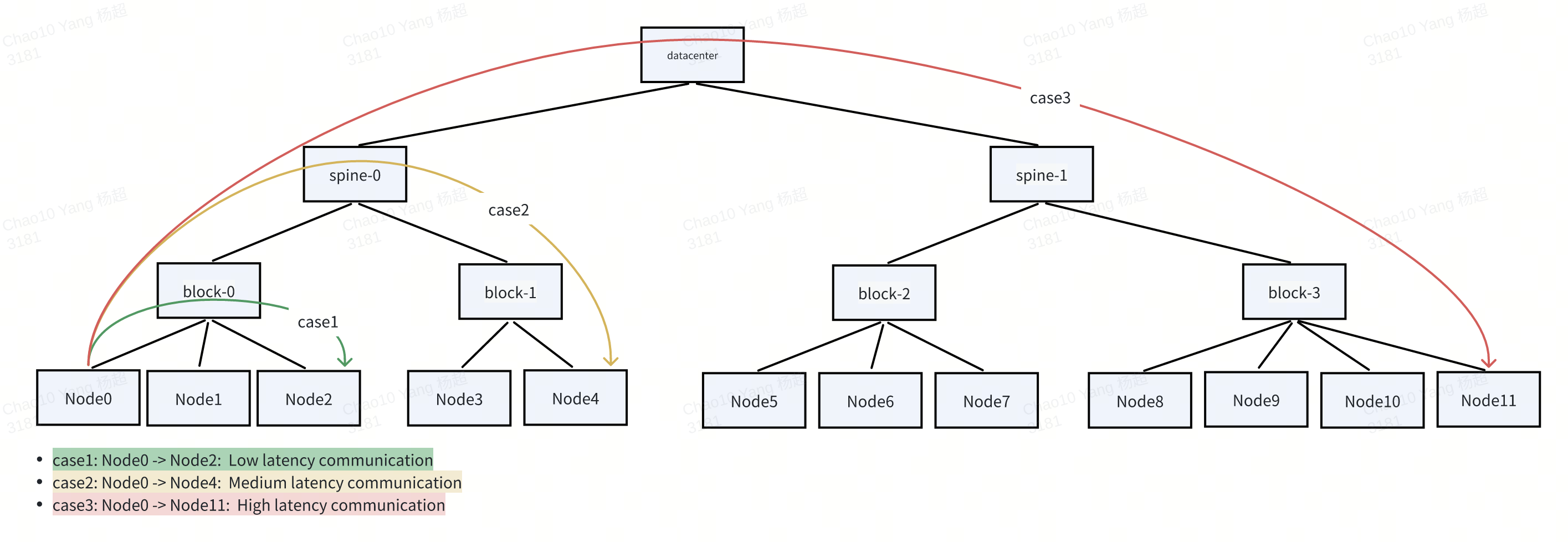
为了优化训练效率,GangGroup 中的 Pod 被要求或优先调度到位于相同或附近高性能网络域的节点上,最小化节点间跳数并最大化吞吐量。例如,在 spine-block 架构中,将所有成员 Pod 调度到同一 block 或 spine 交换机下,与将它们分散在不同 spine 相比,可以显著降低通信延迟。
拓扑感知调度需求
虽然 Kubernetes 的原生调度器通过 PodAffinity 支持基本的拓扑约束,但它以每个 Pod 为基础运行,缺乏 Gang 调度语义,使其对于紧密耦合工作负载的协调放置无效。Koord-Scheduler 抽象了 PodGroup 和 GangGroup 概念,提供全有或全无的语义,实现相互依赖 Pod 的集体调度。此外,为了满足现代 AI 训练的需求,我们将其扩展为网络拓扑感知调度——一种基于网络层次结构智能选择最优节点的能力。
此功能确保:
- 当集群资源充足时,具有网络拓扑调度需求的 Pod 将根据用户指定的策略被调度到性能更好的拓扑域(例如,更低的延迟、更高的带宽)。
- 当集群资源不足时,调度器将基于网络拓扑约束通过 Job 级别抢占为 GangGroup 抢占资源,并在
.status.nominatedNode字段中记录资源提名,以确保一致的放置。
集群网络拓扑
使用 NVIDIA 的 topograph 等工具为节点标记其网络拓扑位置:
apiVersion: v1
kind: Node
metadata:
name: node-0
labels:
network.topology.nvidia.com/accelerator: nvl1
network.topology.nvidia.com/block: s1
network.topology.nvidia.com/spine: s2
network.topology.nvidia.com/datacenter: s3
管理员通过名为 default 的 ClusterNetworkTopology CR 定义拓扑层次结构:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: ClusterNetworkTopology
metadata:
name: default
spec:
networkTopologySpec:
- labelKey:
- network.topology.nvidia.com/spine
topologyLayer: SpineLayer
- labelKey:
- network.topology.nvidia.com/block
parentTopologyLayer: SpineLayer
topologyLayer: BlockLayer
- parentTopologyLayer: BlockLayer
topologyLayer: NodeTopologyLayer
拓扑形成树状结构,其中每一层代表网络中的聚合级别(例如,Node → block → spine)。
ClusterNetworkTopology 的 status.detailStatus 字段由 Koordinator 自动维护,反映集群中的实际网络拓扑结构和节点分布。它呈现从顶层(集群)到各个节点的分层视图。detailStatus 中的每个条目代表特定拓扑层的一个实例,具有关键字段:
topologyInfo: 当前层的类型和名称(例如,SpineLayer,s1)。parentTopologyInfo: 父层的信息。childTopologyNames: 下一较低层中的子域列表。nodeNum: 此拓扑域内的节点数量。
以下是 clusterNetworkTopology.status.detailStatus 的示例:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: ClusterNetworkTopology
metadata:
name: default
spec:
networkTopologySpec:
- labelKey:
- network.topology.nvidia.com/spine
topologyLayer: SpineLayer
- labelKey:
- network.topology.nvidia.com/block
parentTopologyLayer: SpineLayer
topologyLayer: BlockLayer
- parentTopologyLayer: BlockLayer
topologyLayer: NodeTopologyLayer
status:
detailStatus:
- childTopologyLayer: SpineLayer
childTopologyNames:
- s1
- s2
nodeNum: 8
topologyInfo:
topologyLayer: ClusterTopologyLayer
topologyName: ""
- childTopologyLayer: BlockLayer
childTopologyNames:
- b2
- b1
nodeNum: 4
parentTopologyInfo:
topologyLayer: ClusterTopologyLayer
topologyName: ""
topologyInfo:
topologyLayer: SpineLayer
topologyName: s1
- childTopologyLayer: NodeTopologyLayer
nodeNum: 2
parentTopologyInfo:
topologyLayer: SpineLayer
topologyName: s1
topologyInfo:
topologyLayer: BlockLayer
topologyName: b2
- childTopologyLayer: NodeTopologyLayer
nodeNum: 2
parentTopologyInfo:
topologyLayer: SpineLayer
topologyName: s1
topologyInfo:
topologyLayer: BlockLayer
topologyName: b1
- childTopologyLayer: BlockLayer
childTopologyNames:
- b3
- b4
nodeNum: 4
parentTopologyInfo:
topologyLayer: ClusterTopologyLayer
topologyName: ""
topologyInfo:
topologyLayer: SpineLayer
topologyName: s2
- childTopologyLayer: NodeTopologyLayer
nodeNum: 2
parentTopologyInfo:
topologyLayer: SpineLayer
topologyName: s2
topologyInfo:
topologyLayer: BlockLayer
topologyName: b3
- childTopologyLayer: NodeTopologyLayer
nodeNum: 2
parentTopologyInfo:
topologyLayer: SpineLayer
topologyName: s2
topologyInfo:
topologyLayer: BlockLayer
topologyName: b4
基于上述 status,集群具有两层 spine-block 架构:
ClusterTopologyLayer
├── SpineLayer: s1
│ ├── BlockLayer: b1
│ │ └── NodeTopologyLayer: 2 nodes
│ └── BlockLayer: b2
│ └── NodeTopologyLayer: 2 nodes
└── SpineLayer: s2
├── BlockLayer: b3
│ └── NodeTopologyLayer: 2 nodes
└── BlockLayer: b4
└── NodeTopologyLayer: 2 nodes
网络拓扑策略
当用户想要为 GangGroup 配置网络拓扑聚集策略时,可以按如下方式注解其 PodGroup:
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: gang-master
namespace: default
annotations:
gang.scheduling.koordinator.sh/groups: ["default/gang-master", "default/gang-worker"]
gang.scheduling.koordinator.sh/network-topology-spec: |
{
"gatherStrategy": [
{
"layer": "SpineLayer",
"strategy": "PreferGather"
},
{
"layer": "BlockLayer",
"strategy": "PreferGather"
},
{
"layer": "AcceleratorLayer",
"strategy": "PreferGather"
}
]
}
spec:
minMember: 1
---
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: gang-worker
namespace: default
annotations:
gang.scheduling.koordinator.sh/groups: ["default/gang-master", "default/gang-worker"]
gang.scheduling.koordinator.sh/network-topology-spec: |
{
"gatherStrategy": [
{
"layer": "SpineLayer",
"strategy": "PreferGather"
},
{
"layer": "BlockLayer",
"strategy": "PreferGather"
},
{
"layer": "AcceleratorLayer",
"strategy": "PreferGather"
}
]
}
spec:
minMember: 2
上述 PodGroup 表示属于它的 Pod 首先尝试位于加速器互连域中,然后尝试位于 Block 中,最后尝试位于 Spine 网络中。
PodCountMultiple
在一些分布式训练场景中,放置在每个拓扑域内的 Pod 数量必须是特定值 X 的整数倍,其中 X 与域内的通信参数(例如张量并行度)相关。例如,如果 TP=8,则每个 Block 应精确包含 0 或 8 个 Pod——不允许部分组。可以通过聚集策略中的 podCountMultiple 字段进行配置:
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: gang-example
namespace: default
annotations:
gang.scheduling.koordinator.sh/network-topology-spec: |
{
"gatherStrategy": [
{
"layer": "SpineLayer",
"strategy": "PreferGather"
},
{
"layer": "BlockLayer",
"strategy": "PreferGather",
"podCountMultiple": 8
}
]
}
spec:
minMember: 16
在上面的示例中,BlockLayer 的 podCountMultiple: 8 表示分配到每个 Block 的 Pod 数量必须是 8 的整数倍。在计算 offerslots 时,算法会将每个拓扑节点的 offerslots 向下取整为该层指定的 podCountMultiple 值的最近整数倍。
有时,由于对通信带宽的严格需求,用户可能希望将 GangGroup 的所有成员 Pod 放置在同一 Spine 下。在这种情况下,您可以按如下方式修改 PodGroup:
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: gang-master
namespace: default
annotations:
gang.scheduling.koordinator.sh/groups: ["default/gang-master", "default/gang-worker"]
gang.scheduling.koordinator.sh/network-topology-spec: |
{
"gatherStrategy": [
{
"layer": "spineLayer",
"strategy": "MustGather"
}
]
}
spec:
minMember: 1
---
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: gang-worker
namespace: default
annotations:
gang.scheduling.koordinator.sh/groups: ["default/gang-master", "default/gang-worker"]
gang.scheduling.koordinator.sh/network-topology-spec: |
{
"gatherStrategy": [
{
"layer": "spineLayer",
"strategy": "MustGather"
}
]
}
spec:
minMember: 2
网络拓扑 Pod 索引
在分布式训练中,为每个 Pod 分配索引对于在数据并行(DP)作业中建立通信模式至关重要。索引确定 Pod 在集体操作中的逻辑顺序。例如,对于 DP=2 的 GangGroup,成员 Pod 可以注解如下:
apiVersion: v1
kind: Pod
metadata:
name: pod-example1
namespace: default
labels:
pod-group.scheduling.sigs.k8s.io: gang-example
annotations:
gang.scheduling.koordinator.sh/network-topology-index: "1"
spec:
schedulerName: koord-scheduler
...
---
apiVersion: v1
kind: Pod
metadata:
name: pod-example2
namespace: default
labels:
pod-group.scheduling.sigs.k8s.io: gang-example
annotations:
gang.scheduling.koordinator.sh/network-topology-index: "2"
spec:
schedulerName: koord-scheduler
...
拓扑聚集算法
网络拓扑聚集算法是为 M 个 Pod 找到最佳节点,给定属于并行感知 GangGroup 的 M 个成员 Pod、所有可以放置 Pod 的节点、每个节点的网络拓扑位置。整体计算过程可以逐步描述如下:
训练任务的
GangGroup的成员 Pod 通常是同质的。我们从成员 Pod 中随机选择一个作为代表 Pod。从网络拓扑层次结构的底部到顶部,递归计算每个拓扑节点可以提供的成员 Pod 数量作为
offerslots。节点可以容纳的offerslots可以通过迭代调用NodeInfo.AddPod、fwk.RunPreFilterExtensionsAddPod和fwk.RunFilterWithNominatedNode来实现。在所有可以容纳
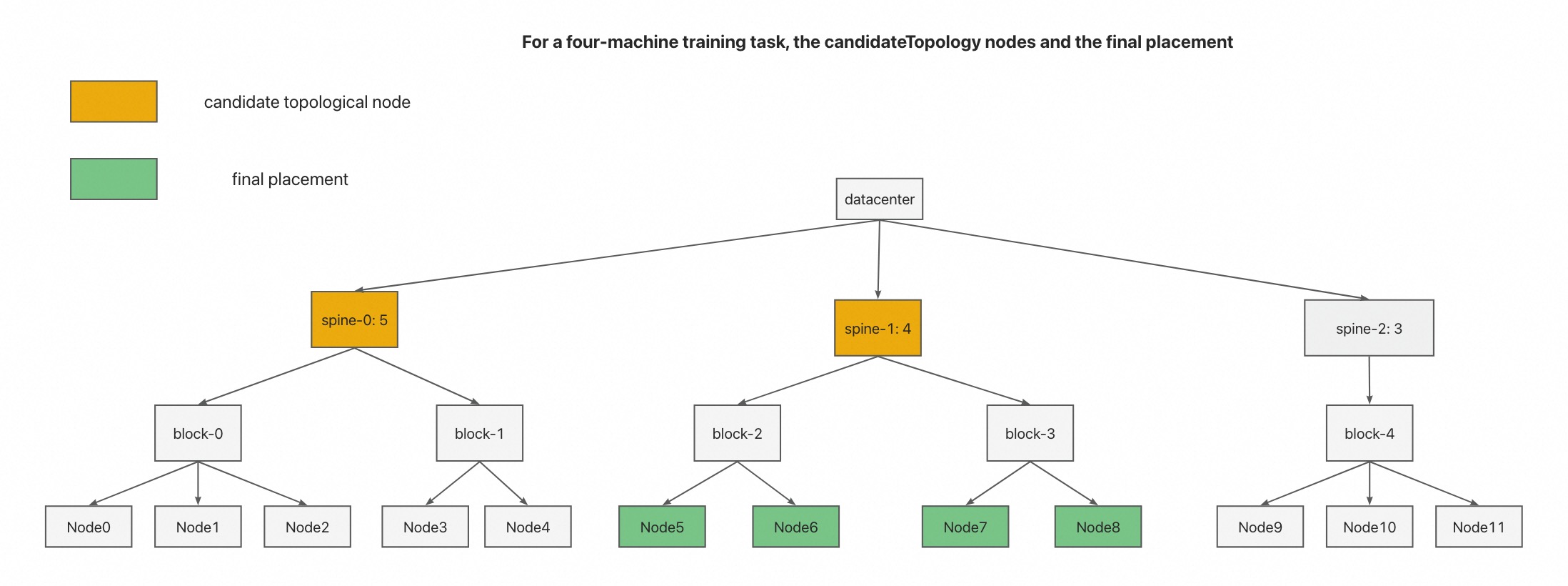
GangGroup所有成员 Pod 的拓扑节点中,选择那些层级最低的作为我们的候选拓扑节点。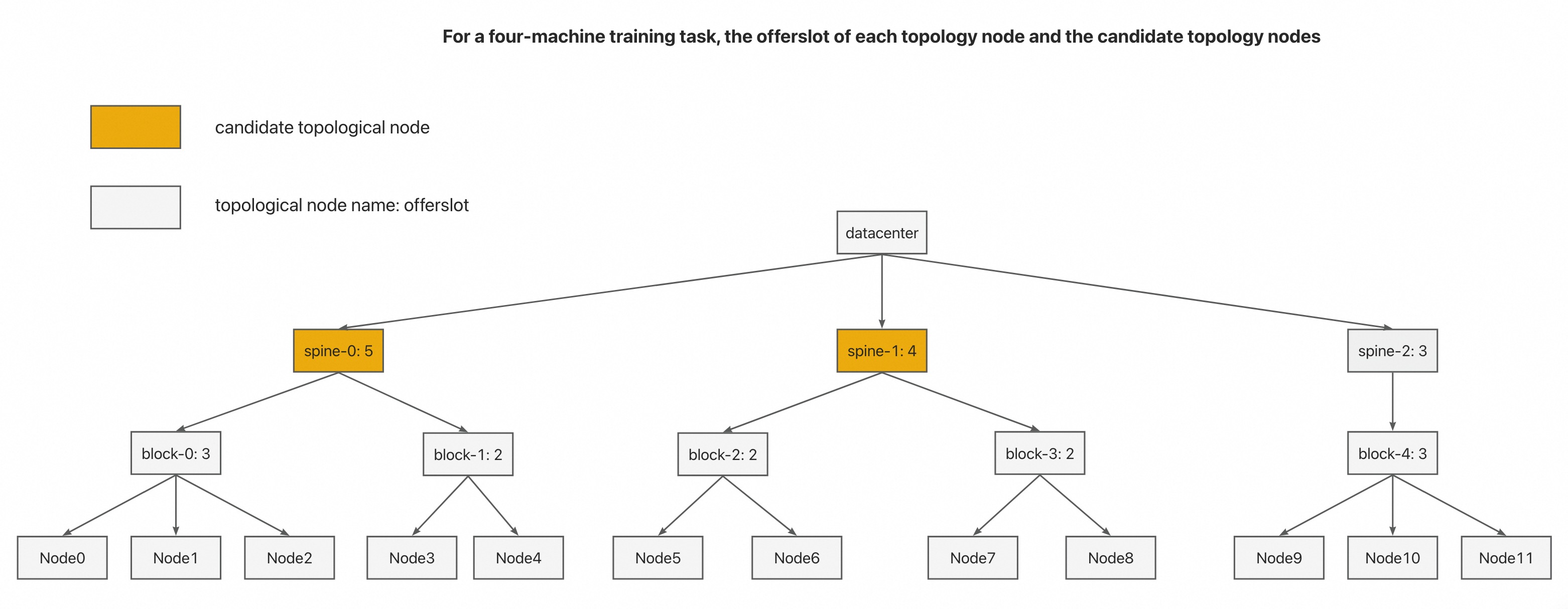
在步骤 3 中选择的候选拓扑节点中,根据
binpack原则,选择 offerslot 最接近作业所需 offerslot 的候选拓扑节点作为我们的最终拓扑节点解决方案。如下图所示,我们选择 Node5-Node8 作为作业的最终调度结果。