
Background
As an actively developing open source project, Koordinator has undergo multiple version iterations since the release of v0.1.0 in April 2022, continuously bringing innovations and enhancements to the Kubernetes ecosystem. The core objective of the project is to provide comprehensive solutions for orchestrating collocated workloads, scheduling resources, ensuring resource isolation, and tuning performance to help users optimize container performance and improve cluster resource utilization.
In past version iterations, the Koordinator community has continued to grow, receiving active participation and contributions from engineers at well-known companies. These include Alibaba, Ant Technology Group, Intel, Xiaomi, Xiaohongshu, iQIYI, Qihoo 360, Youzan, Quwan, Meiya Pico, PITS, among others. Each version has advanced through the collective efforts of the community, demonstrating the project's capability to address challenges in actual production environments.
Today, we are pleased to announce that Koordinator v1.4.0 is officially released. This version introduces several new features, including Kubernetes and YARN workload co-location, a NUMA topology alignment strategy, CPU normalization, and cold memory reporting. It also enhances features in key areas such as elastic quota management, QoS management for non-containerized applications on hosts, and descheduling protection strategies. These innovations and improvements aim to better support enterprise-level Kubernetes cluster environments, particularly in complex and diverse application scenarios.
The release of version v1.4.0 will bring users support for more types of computing workloads and more flexible resource management mechanisms. We look forward to these improvements helping users to address a broader range of enterprise resource management challenges. In the v1.4.0 release, a total of 11 new developers have joined the development of the Koordinator community. They are @shaloulcy, @baowj-678, @zqzten, @tan90github, @pheianox, @zxh326, @qinfustu, @ikaven1024, @peiqiaoWang, @bogo-y, and @xujihui1985. We thank all community members for their active participation and contributions during this period and for their ongoing commitment to the community.
Interpretation of Version Features
1. Support Kubernetes and YARN workload co-location
Koordinator already supports the co-location of online and offline workloads within the Kubernetes ecosystem. However, outside the Kubernetes ecosystem, a considerable number of big data workloads still run on traditional Hadoop YARN.
In response, the Koordinator community, together with developers from Alibaba Cloud, Xiaohongshu, and Ant Financial, has jointly launched the Hadoop YARN and Kubernetes co-location project, Koordinator YARN Copilot. This initiative enables the running of Hadoop NodeManager within Kubernetes clusters, fully leveraging the technical value of peak-shaving and resource reuse for different types of workloads. Koordinator YARN Copilot has the following features:
- Embracing the open-source ecosystem: Built upon the open-source version of Hadoop YARN without any intrusive modifications to YARN.
- Unified resource priority and QoS policy: YARN NodeManager utilizes Koordinator’s Batch priority resources and adheres to Koordinator's QoS management policies.
- Node-level resource sharing: The co-location resources provided by Koordinator can be used by both Kubernetes pod and YARN tasks. Different types of offline applications can run on the same node.

For the detailed design of Koordinator YARN Copilot and its use in the Xiaohongshu production environment, please refer to Previous Articles and Official Community Documents.
2. Introducing NUMA topology alignment strategy
The workloads running in Kubernetes clusters are increasingly diverse, particularly in fields such as machine learning, where the demand for high-performance computing resources is on the rise. In these fields, a significant amount of CPU resources is required, as well as other high-speed computing resources like GPUs and RDMA. Moreover, to achieve optimal performance, these resources often need to be located on the same NUMA node or even the same PCIe bus.
Kubernetes' kubelet includes a topology manager that manages the NUMA topology of resource allocation. It attempts to align the topologies of multiple resources at the node level during the admission phase. However, because the node component lacks a global view of the scheduler and the timing of node selection for pods, pods may be scheduled on nodes that are unable to meet the topology alignment policy. This can result in pods failing to start due to topology affinity errors.
To solve this problem, Koordinator moves NUMA topology selection and alignment to the central scheduler, optimizing resource NUMA topology at the cluster level. In this release, Koordinator introduces NUMA-aware scheduling of CPU resources (including Batch resources) and NUMA-aware scheduling of GPU devices as alpha features. The entire suite of NUMA-aware scheduling features is rapidly evolving.
Koordinator enables users to configure the NUMA topology alignment strategy for multiple resources on a node through the node's labels. The configurable strategies are as follows:
None, the default strategy, does not perform any topological alignment.BestEffortindicates that the node does not strictly allocate resources according to NUMA topology alignment. The scheduler can always allocate such nodes to pods as long as the remaining resources meet the pods' needs.Restrictedmeans that nodes allocate resources in strict accordance with NUMA topology alignment. In other words, the scheduler must select the same one or more NUMA nodes when allocating multiple resources, otherwise, the node should not be considered. For instance, if a pod requests 33 CPU cores and each NUMA node has 32 cores, it can be allocated to use two NUMA nodes. Moreover, if the pod also requests GPUs or RDMA, these must be on the same NUMA node as the CPU.SingleNUMANodeis similar toRestricted, adhering strictly to NUMA topology alignment, but it differs in thatRestrictedpermits the use of multiple NUMA nodes, whereasSingleNUMANoderestricts allocation to a single NUMA node.
For example, to set the SingleNUMANode policy for node-0, you would do the following:
apiVersion: v1
kind: Node
metadata:
labels:
node.koordinator.sh/numa-topology-policy: "SingleNUMANode"
name: node-0
spec:
...
In a production environment, users may have enabled kubelet's topology alignment policy, which will be reflected by the koordlet in the TopologyPolicies field of the NodeResourceTopology CR object. When kubelet's policy conflicts with the policy set by the user on the node, the kubelet policy shall take precedence. The koord-scheduler essentially adopts the same NUMA alignment policy semantics as the kubelet topology manager. The kubelet policies SingleNUMANodePodLevel and SingleNUMANodeContainerLevel are both mapped to SingleNUMANode.
After configuring the NUMA alignment strategy for the node, the scheduler can identify many suitable NUMA node allocation results for each pod. Koordinator currently provides the NodeNUMAResource plugin, which allows for configuring the NUMA node allocation result scoring strategy for CPU and memory resources. This includes LeastAllocated and MostAllocated strategies, with LeastAllocated being the default. Each resource can also be assigned a configurable weight. The scheduler will ultimately select the NUMA node allocation with the highest score. For instance, we can configure the NUMA node allocation result scoring strategy to MostAllocated, as shown in the following example:
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- name: NodeNUMAResource
args:
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: NodeNUMAResourceArgs
scoringStrategy: # Here configure Node level scoring strategy
type: MostAllocated
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: "kubernetes.io/batch-cpu"
weight: 1
- name: "kubernetes.io/batch-memory"
weight: 1
numaScoringStrategy: # Here configure NUMA-Node level scoring strategy
type: MostAllocated
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: "kubernetes.io/batch-cpu"
weight: 1
- name: "kubernetes.io/batch-memory"
weight: 1
3. ElasticQuota evolves again
In order to fully utilize cluster resources and reduce management system costs, users often deploy workloads from multiple tenants in the same cluster. When cluster resources are limited, competition for these resources is inevitable between different tenants. As a result, the workloads of some tenants may always be satisfied, while others may never be executed, leading to demands for fairness. The quota mechanism is a very natural way to ensure fairness among tenants, where each tenant is allocated a specific quota, and they can use resources within that quota. Tasks exceeding the quota will not be scheduled or executed. However, simple quota management cannot fulfill tenants' expectations for elasticity in the cloud. Users hope that in addition to satisfying resource requests within the quota, requests for resources beyond the quota can also be met on demand.
In previous versions, Koordinator leveraged the upstream ElasticQuota protocol, which allowed tenants to set a 'Min' value to express their resource requests that must be satisfied, and a 'Max' value to limit the maximum resources they can use. 'Max' was also used to represent the shared weight of the remaining resources of the cluster when they were insufficient.
In addition to offering a flexible quota mechanism that accommodates tenants' on-demand resource requests, Koordinator enhances ElasticQuota with annotations to organize it into a tree structure, thereby simplifying the expression of hierarchical organizational structures for users.
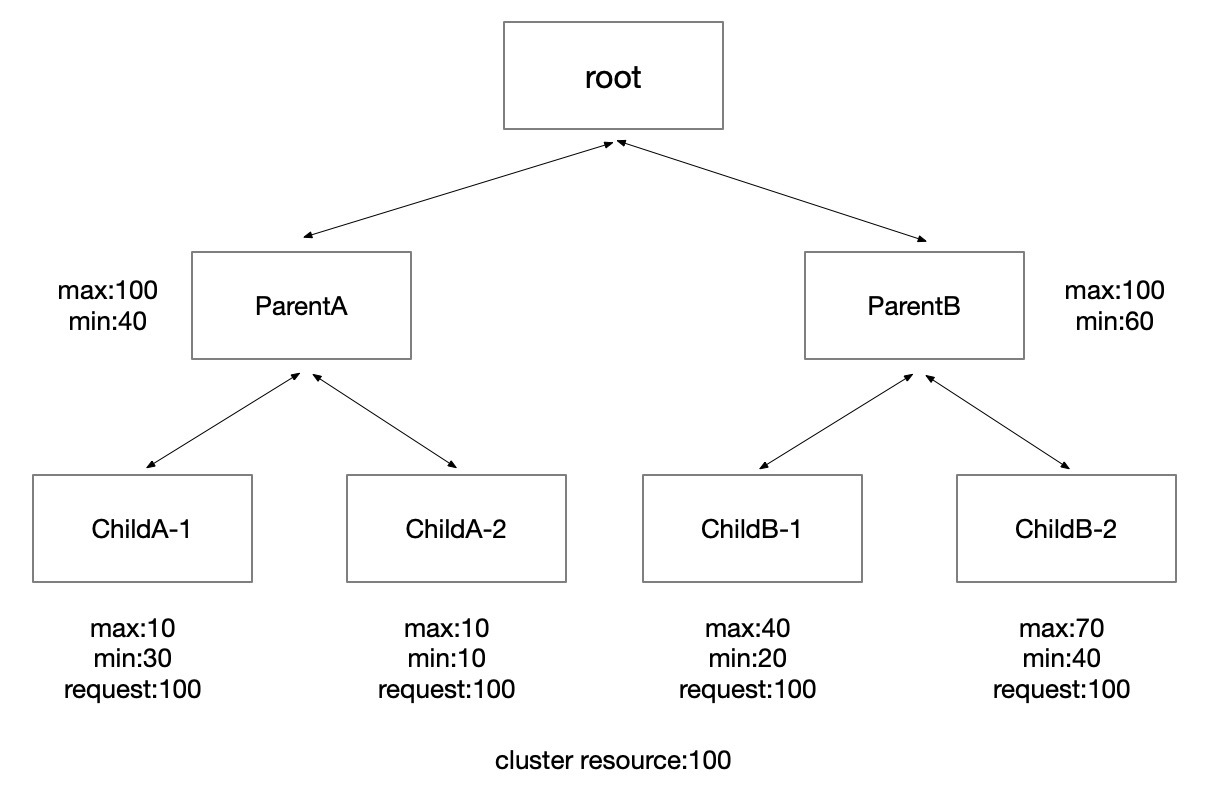
The figure above depicts a common quota tree in a cluster utilizing Koordinator's elastic quota. The root quota serves as the link between the quota system and the actual resources within the cluster. In previous iterations, the root quota existed only within the scheduler's logic. In this release, we have made the root quota accessible to users in the form of a Custom Resource (CR). Users can now view information about the root quota through the ElasticQuota CR named koordinator-root-quota.
3.1 Introducing Multi QuotaTree
In large clusters, there are various types of nodes. For example, VMs provided by cloud vendors will have different architectures. The most common ones are amd64 and arm64. There are also different models with the same architecture. In addition, nodes generally have location attributes such as availability zone. When nodes of different types are managed in the same quota tree, their unique attributes will be lost. When users want to manage the unique attributes of machines in a refined manner, the current ElasticQuota appears not to be accurate enough. In order to meet users' requirements for flexible resource management or resource isolation, Koordinator supports users to divide the resources in the cluster into multiple parts, each part is managed by a quota tree, as shown in the following figure:
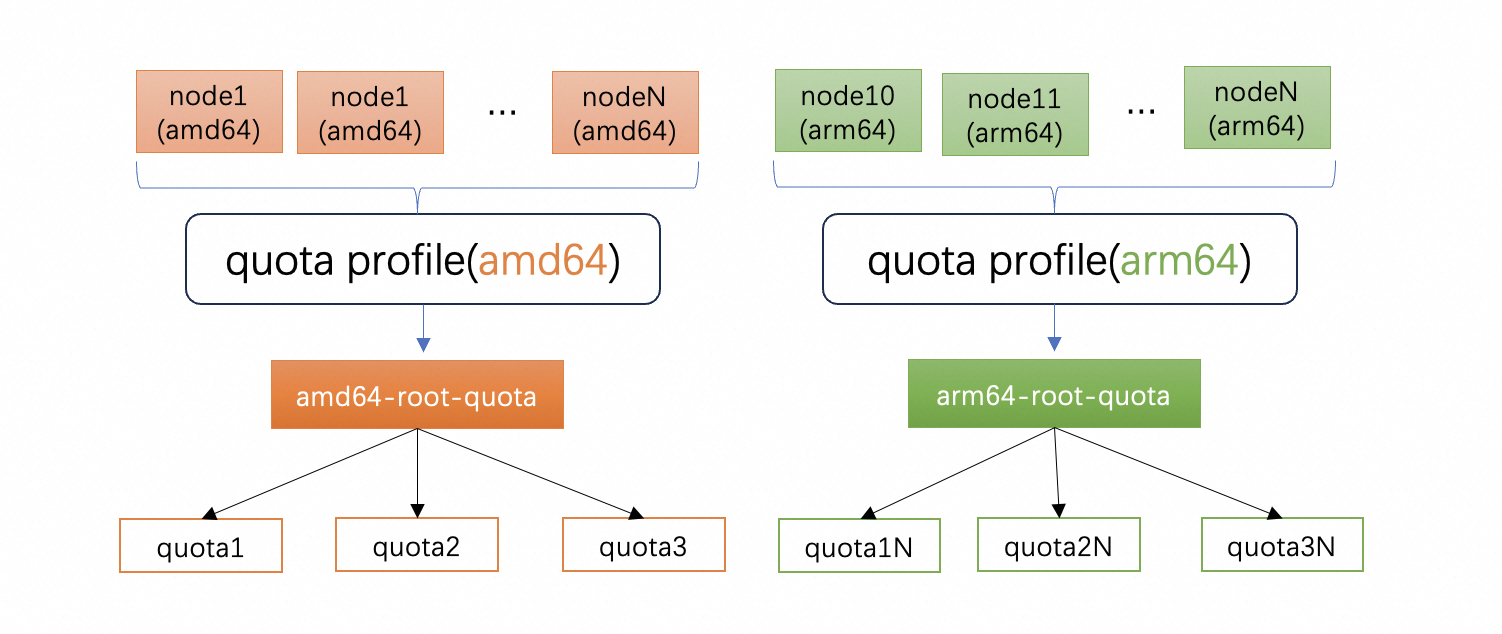
Additionally, to help users simplify management complexity, Koordinator introduced the ElasticQuotaProfile mechanism in version 1.4.0. Users can quickly associate nodes with different quota trees through the nodeSelector, as shown in the following example:
apiVersion: quota.koordinator.sh/v1alpha1
kind: ElasticQuotaProfile
metadata:
labels:
kubernetes.io/arch: amd64
name: amd64-profile
namespace: kube-system
spec:
nodeSelector:
matchLabels:
kubernetes.io/arch: amd64 // amd64 node
quotaName: amd64-root-quota // the name of root quota
---
apiVersion: quota.koordinator.sh/v1alpha1
kind: ElasticQuotaProfile
metadata:
labels:
kubernetes.io/arch: arm64
name: arm64-profile
namespace: kube-system
spec:
nodeSelector:
matchLabels:
kubernetes.io/arch: arm64 // arm64 node
quotaName: arm64-root-quota // the name of root quota
After associating nodes with the quota tree, the user utilizes the ElasticQuota in each quota tree as before. When a user submits a pod to the corresponding quota, they currently still need to configure the pod's NodeAffinity to ensure that the pod runs on the correct node. In the future, we plan to add a feature that will help users automatically manage the mapping relationship from quota to node.
3.2 Support non-preemptible
Koordinator ElasticQuota supports sharing the unused part of 'Min' in ElasticQuota with other ElasticQuotas to improve resource utilization. However, when resources are tight, the pod that borrows the quota will be preempted and evicted through the preemption mechanism to get the resources back.
In actual production environments, if some critical online services borrow this part of the quota from other ElasticQuotas and preemption subsequently occurs, the quality of service may be adversely affected. Such workloads should not be subject to preemption.
To implement this safeguard, Koordinator v1.4.0 introduced a new API. Users can simply annotate a pod with quota.scheduling.koordinator.sh/preemptible: false to indicate that the pod should not be preempted.
When the scheduler detects that a pod is declared non-preemptible, it ensures that the available quota for such a pod does not exceed its 'Min'. Thus, it is important to note that when enabling this feature, the 'Min' of an ElasticQuota should be set judiciously, and the cluster must have appropriate resource guarantees in place. This feature maintains compatibility with the original behavior of Koordinator.
apiVersion: v1
kind: Pod
metadata:
name: pod-example
namespace: default
labels:
quota.scheduling.koordinator.sh/name: "quota-example"
quota.scheduling.koordinator.sh/preemptible: false
spec:
...
3.3 Other improvements
- The koord-scheduler previously supported the use of a single ElasticQuota object across multiple namespaces. However, in some cases, it is desirable for the same object to be shared by only a select few namespaces. To accommodate this need, users can now annotate the ElasticQuota CR with
quota.scheduling.koordinator.sh/namespaces, assigning a JSON string array as the value. - Performance optimization: Previously, whenever an ElasticQuota was modified, the ElasticQuota plugin would rebuild the entire quota tree. This process has been optimized in version 1.4.0.
- Support ignoring overhead: When a pod utilizes secure containers, an overhead declaration is typically added to the pod specification to account for the resource consumption of the secure container itself. However, whether these additional resource costs should be passed on to the end user depends on the resource pricing strategy. If it is expected that users should not be responsible for these costs, the ElasticQuota can be configured to disregard overhead. With version 1.4.0, this can be achieved by enabling the feature gate
ElasticQuotaIgnorePodOverhead.
4. CPU normalization
With the diversification of node hardware in Kubernetes clusters, significant performance differences exist between CPUs of various architectures and generations. Therefore, even if a pod's CPU request is identical, the actual computing power it receives can vary greatly, potentially leading to resource waste or diminished application performance. The objective of CPU normalization is to ensure that each CPU unit in Kubernetes provides consistent computing power across heterogeneous nodes by standardizing the performance of allocatable CPUs.
To address this issue, Koordinator has implemented a CPU normalization mechanism in version 1.4.0. This mechanism adjusts the amount of CPU resources that can be allocated on a node according to the node's resource amplification strategy, ensuring that each allocatable CPU in the cluster delivers a consistent level of computing power. The overall architecture is depicted in the figure below:

CPU normalization consists of two steps
- CPU performance evaluation: To calculate the performance benchmarks of different CPUs, you can refer to the industrial performance evaluation standard, SPEC CPU. This part is not provided by the Koordinator project.
- Configuration of the CPU normalization ratio in Koordinator: The scheduling system schedules resources based on the normalization ratio, which is provided by Koordinator.
Configure the CPU normalization ratio information into slo-controller-config of koord-manager. The configuration example is as follows:
apiVersion: v1
kind: ConfigMap
metadata:
name: slo-controller-config
namespace: koordinator-system
data:
cpu-normalization-config: |
{
"enable": true,
"ratioModel": {
"Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz": {
"baseRatio": 1.29,
"hyperThreadEnabledRatio": 0.82,
"turboEnabledRatio": 1.52,
"hyperThreadTurboEnabledRatio": 1.0
},
"Intel Xeon Platinum 8369B CPU @ 2.90GHz": {
"baseRatio": 1.69,
"hyperThreadEnabledRatio": 1.06,
"turboEnabledRatio": 1.91,
"hyperThreadTurboEnabledRatio": 1.20
}
}
}
# ...
For nodes configured with CPU normalization, Koordinator intercepts updates to Node.Status.Allocatable by kubelet through a webhook to achieve the amplification of CPU resources. This results in the display of the normalized amount of CPU resources available for allocation on the node.
5. Improved descheduling protection strategies
Pod migration is a complex process that involves steps such as auditing, resource allocation, and application startup. It is often intertwined with application upgrades, scaling scenarios, and the resource operations and maintenance performed by cluster administrators. Consequently, if a large number of pods are migrated simultaneously, the system's stability may be compromised. Furthermore, migrating many pods from the same workload at once can also affect the application's stability. Additionally, simultaneous migrations of pods from multiple jobs may lead to a 'thundering herd' effect. Therefore, it is preferable to process the pods in each job sequentially.
To address these issues, Koordinator previously provided the PodMigrationJob function with some protection strategies. In version v1.4.0, Koordinator has enhanced these protection strategies into an arbitration mechanism. When there is a large number of executable PodMigrationJobs, the arbiter decides which ones can proceed by employing sorting and filtering techniques.
The sorting process is as follows:
- The time interval between the start of migration and the current, the smaller the interval, the higher the ranking.
- The pod priority of PodMigrationJob, the lower the priority, the higher the ranking.
- Disperse Jobs by workload, make PodMigrationJobs close in the same job.
- If some pods in the job containing PodMigrationJob's pod is being migrated, the PodMigrationJob's ranking is higher.
The filtering process is as follows:
- Group and filter PodMigrationJobs based on workload, node, namespace, etc.
- Check the number of running podMigrationJobs in each workload, and those that reach a certain threshold will be excluded.
- Check whether the number of unavailable replicas in each workload exceeds the maximum number of unavailable replicas, and those that exceed the number will be excluded.
- Check whether the number of pods being migrated on the node where the target pod is located exceeds the maximum migration amount of a single node, and those that exceed will be excluded.
6. Cold Memory reporting
To improve system performance, the kernel generally tries not to free the page cache requested by an application but allocates as much as possible to the application. Although allocated by the kernel, this memory may no longer be accessed by applications and is referred to as cold memory.
Koordinator introduced the cold memory reporting function in version 1.4, primarily to lay the groundwork for future cold memory recycling capabilities. Cold memory recycling is designed to address two scenarios:
- In standard Kubernetes clusters, when the node memory level is too high, sudden memory requests can lead to direct memory recycling of the system. This can affect the performance of running containers and, in extreme cases, may result in out-of-memory (OOM) events if recycling is not timely. Therefore, maintaining a relatively free pool of node memory resources is crucial for runtime stability.
- In co-location scenarios, high-priority applications' unused requested resources can be recycled by lower-priority applications. Since memory not reclaimed by the operating system is invisible to the Koordinator scheduling system, reclaiming unused memory pages of a container is beneficial for improving resource utilization.
Koordlet has added a cold page collector to its collector plugins for reading the cgroup file memory.idle_stat, which is exported by kidled (Anolis kernel), kstaled (Google), or DAMON (Amazon). This file contains information about cold pages in the page cache and is present at every hierarchy level of memory. Koordlet already supports the kidled cold page collector and provides interfaces for other cold page collectors.
After collecting cold page information, the cold page collector stores the metrics, such as hot page usage and cold page size for nodes, pods, and containers, into metriccache. This data is then reported to the NodeMetric Custom Resource (CR).
Users can enable cold memory recycling and configure cold memory collection strategies through NodeMetric. Currently, three strategies are offered: usageWithHotPageCache, usageWithoutPageCache and usageWithPageCache. For more details, please see the community Design Document。
7. QoS management for non-containerized applications
In the process of enterprise containerization, there may be non-containerized applications running on the host alongside those already running on Kubernetes. In order to be better compatible with enterprises in the containerization process, Koordinator has developed a node resource reservation mechanism. This mechanism can reserve resources and assign specific QoS (Quality of Service) levels to applications that have not yet been containerized. Unlike the resource reservation configuration provided by kubelet, Koordinator's primary goal is to address QoS issues that arise during the runtime of both non-containerized and containerized applications. The overall solution is depicted in the figure below:

Currently, applications need to start processes into the corresponding cgroup according to specifications, and Koordinator does not provide an automatic cgroup relocation tool. For host non-containerized applications, QoS is supported as follows:
LS (Latency Sensitive)
- CPU QoS (Group Identity): The application runs the process in the CPU subsystem of the cgroup according to the specification, and the koordlet sets the Group Identity parameter for it according to the CPU QoS configuration;
- CPUSet Allocation: The application runs the process in the CPU subsystem of the cgroup according to the specification, and the koordlet will set all CPU cores in the CPU share pool for it.
BE (Best-effort)
- CPU QoS (Group Identity): The application runs the process in the CPU subsystem of the cgroup according to the specification, and the koordlet sets the Group Identity parameter for it according to the configuration of CPU QoS.
For detailed design of QoS management of non-containerized applications on the host, please refer to Community Documentation. In the future, we will gradually add support for other QoS strategies for host non-containerized applications.
8. Other features
In addition to the new features and functional enhancements mentioned above, Koordinator has also implemented the following bug fixes and optimizations in version 1.4.0:
- RequiredCPUBindPolicy: Fine-grained CPU orchestration now supports the configuration of the required CPU binding policy, which means that CPUs are allocated strictly in accordance with the specified CPU binding policy; otherwise, scheduling will fail.
- CICD: The Koordinator community provides a set of e2e testing Pipeline in v1.4.0; an ARM64 image is provided.
- Batch resource calculation strategy optimization: There is support for the
maxUsageRequestcalculation strategy, which conservatively reclaims high-priority resources. This update also optimizes the underestimate of Batch allocatable when a large number of pods start and stop on a node in a short period of time and improves considerations for special circumstances such as host non-containerized application, third-party allocatable, and dangling pod usage. - Others: Optimizations include using libpfm4 and perf groups to improve CPI collection, allowing SystemResourceCollector to support customized expiration time configuration, enabling BE pods to calculate CPU satisfaction based on the evictByAllocatable policy, repairing koordlet's CPUSetAllocator filtering logic for pods with LS and None QoS, and enhancing RDT resource control to retrieve the task IDs of sandbox containers.
For a comprehensive list of new features in version 1.4.0, please visit the v1.4.0 Release page.
Future plan
In upcoming versions, Koordinator has planned the following features:
- Core Scheduling: On the runtime side, Koordinator has begun exploring the next generation of CPU QoS capabilities. By leveraging kernel mechanisms such as Linux Core Scheduling, it aims to enhance resource isolation at the physical core level and reduce the security risks associated with co-location. For more details on this work, see Issue #1728.
- Joint Allocation of Devices: In scenarios involving AI large model distributed training, GPUs from different machines often need to communicate through high-performance network cards. Performance is improved when GPUs and high-performance network cards are allocated in close proximity. Koordinator is advancing the joint allocation of multiple heterogeneous resources. Currently, it supports joint allocation in terms of protocol and scheduler logic; the reporting logic for network card resources on the node side is being explored.
For more information, please pay attention to Milestone v1.5.0.
Conclusion
Finally, we are immensely grateful to all the contributors and users of the Koordinator community. Your active participation and valuable advice have enabled Koordinator to continue improving. We eagerly look forward to your ongoing feedback and warmly welcome new contributors to join our ranks.