Background
With the explosive popularity of large models like DeepSeek, the demand for heterogeneous device resource scheduling in AI and high-performance computing fields has grown rapidly, whether it's for GPUs, NPUs, or RDMA devices. Efficiently managing and scheduling these resources has become a core concern in the industry. In response to this demand, Koordinator actively addresses community requests and continues to deepen its capabilities in heterogeneous device scheduling. In the latest v1.6 release, a series of innovative features have been introduced to help customers solve complex heterogeneous resource scheduling challenges.
In v1.6, we have enhanced device topology scheduling capabilities, supporting awareness of more machine types' GPU topologies, significantly accelerating GPU interconnect performance within AI applications. Collaborating with the open-source project HAMi, we have introduced end-to-end GPU & RDMA joint allocation capabilities as well as strong GPU isolation, effectively improving cross-machine interconnect efficiency for typical AI training tasks and increasing deployment density for inference tasks. This ensures better application performance and higher cluster resource utilization. Additionally, enhancements were made to the Kubernetes community’s resource plugins, enabling different resource configurations to apply distinct node scoring strategies. This feature significantly reduces GPU fragmentation when GPU and CPU tasks coexist in a single cluster.
Since its official open-source release in April 2022, Koordinator has iterated through 14 major versions, attracting contributions from outstanding engineers at companies such as Alibaba, Ant Group, Intel, Xiaohongshu, Xiaomi, iQIYI, 360, Youzan, and more. Their rich ideas, code contributions, and real-world application scenarios have greatly propelled the project's development. Notably, in the v1.6.0 release, ten new developers actively contributed to the Koordinator community: @LY-today, @AdrianMachao, @TaoYang526, @dongjiang1989, @chengjoey, @JBinin, @clay-wangzhi, @ferris-cx, @nce3xin, and @lijunxin559. We sincerely thank them for their contributions and all community members for their ongoing dedication and support!
Key Features
1. GPU Topology-Aware Scheduling: Accelerating GPU Interconnects Within AI Applications
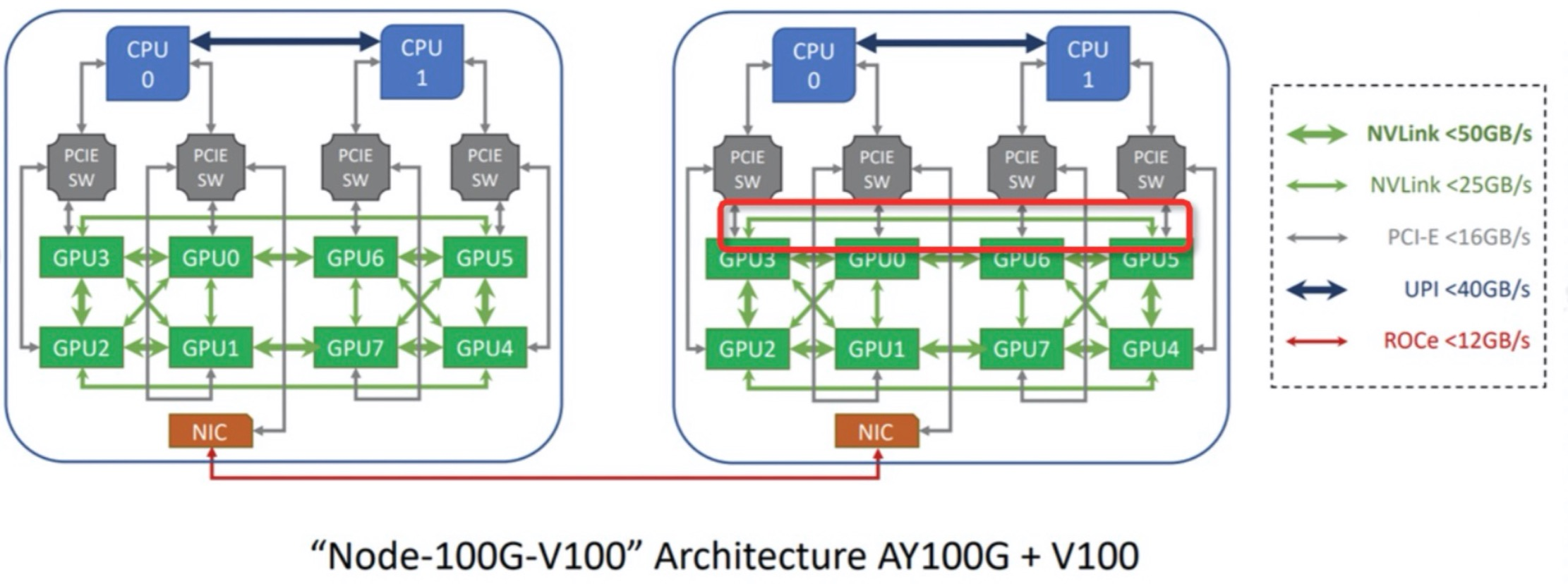
With the rapid development of deep learning and high-performance computing (HPC), GPUs have become a core resource for many compute-intensive workloads. Efficient GPU utilization is crucial for enhancing application performance in Kubernetes clusters. However, GPU performance is not uniform and is influenced by hardware topology and resource allocation. For example:
- In multi-NUMA node systems, physical connections between GPUs, CPUs, and memory can affect data transfer speeds and computational efficiency.
- For NVIDIA cards like L20 and L40S, GPU communication efficiency depends on whether they are connected via the same PCIe or NUMA node.
- For Huawei’s Ascend NPU and virtualized environments using SharedNVSwitch mode with NVIDIA H-series machines, GPU allocation must adhere to predefined Partition rules.
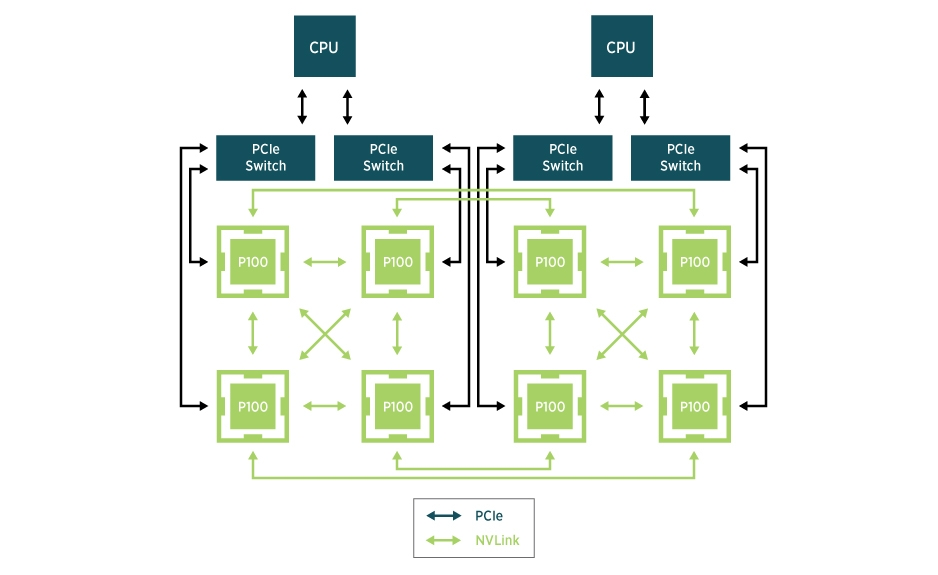
To address these device scenarios, Koordinator provides rich device topology scheduling APIs to meet Pods’ GPU topology requirements. Below are examples of how to use these APIs:
- Allocating GPUs, CPUs, and memory within the same NUMA Node:
apiVersion: v1
kind: Pod
metadata:
annotations:
scheduling.koordinator.sh/numa-topology-spec: '{"numaTopologyPolicy":"Restricted", "singleNUMANodeExclusive":"Preferred"}'
spec:
containers:
- resources:
limits:
koordinator.sh/gpu: 200
cpu: 64
memory: 500Gi
requests:
koordinator.sh/gpu: 200
cpu: 64
memory: 500Gi - Allocating GPUs within the same PCIe:
apiVersion: v1
kind: Pod
metadata:
annotations:
scheduling.koordinator.sh/device-allocate-hint: |-
{
"gpu": {
"requiredTopologyScope": "PCIe"
}
}
spec:
containers:
- resources:
limits:
koordinator.sh/gpu: 200 - Allocating GPUs within the same NUMA Node:
apiVersion: v1
kind: Pod
metadata:
annotations:
scheduling.koordinator.sh/device-allocate-hint: |-
{
"gpu": {
"requiredTopologyScope": "NUMANode"
}
}
spec:
containers:
- resources:
limits:
koordinator.sh/gpu: 400 - Allocating GPUs according to predefined Partitions:
Predefined GPU Partition rules are typically determined by specific GPU models or system configurations and may also depend on the GPU setup on individual nodes. The scheduler cannot discern hardware model specifics or GPU types; instead, it relies on node-level components reporting these predefined rules to custom resource (CR) definitions, as shown below:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Device
metadata:
annotations:
scheduling.koordinator.sh/gpu-partitions: |
{
"1": [
"NVLINK": {
{
# Which GPUs are included
"minors": [
0
],
# GPU Interconnect Type
"gpuLinkType": "NVLink",
# Here we take the bottleneck bandwidth between GPUs in the Ring algorithm. BusBandwidth can be referenced from https://github.com/NVIDIA/nccl-tests/blob/master/doc/PERFORMANCE.md
"ringBusBandwidth": 400Gi
# Indicate the overall allocation quality for the node after the partition has been assigned away.
"allocationScore": "1",
},
...
}
...
],
"2": [
...
],
"4": [
...
],
"8": [
...
]
}
labels:
// Indicates whether the Partition rule must be followed
node.koordinator.sh/gpu-partition-policy: "Honor"
name: node-1
When multiple Partition options are available, Koordinator allows users to decide whether to allocate based on the optimal Partition:
kind: Pod
metadata:
name: hello-gpu
annotations:
scheduling.koordinator.sh/gpu-partition-spec: |
{
# BestEffort|Restricted
"allocatePolicy": "Restricted",
}
spec:
containers:
- name: main
resources:
limits:
koordinator.sh/gpu: 100
If users do not need to allocate based on the optimal Partition, the scheduler will allocate resources in a Binpack manner as much as possible.
For more details on GPU topology-aware scheduling, please refer to the following design documents:
Special thanks to community developer @eahydra for contributing to this feature!
2. End-to-End GDR Support: Enhancing Cross-Machine Task Interconnect Performance
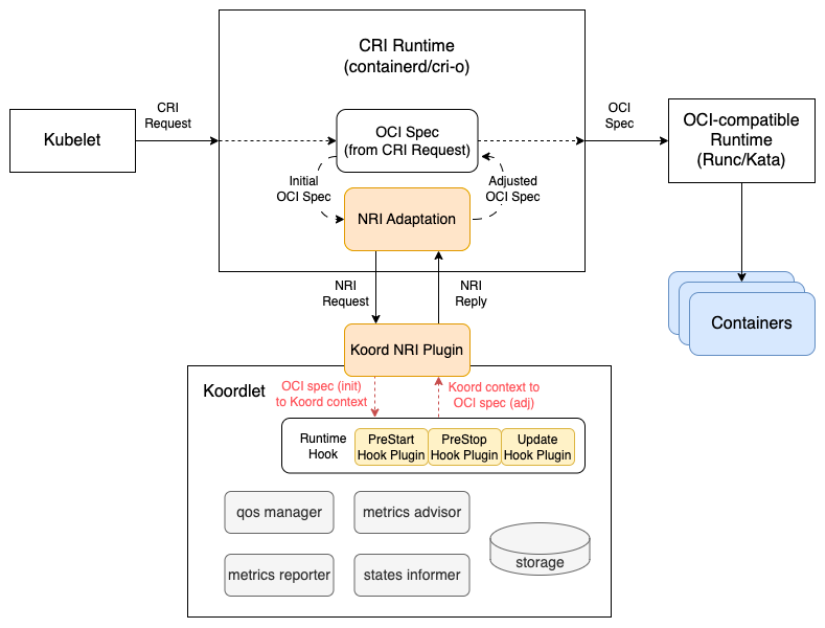
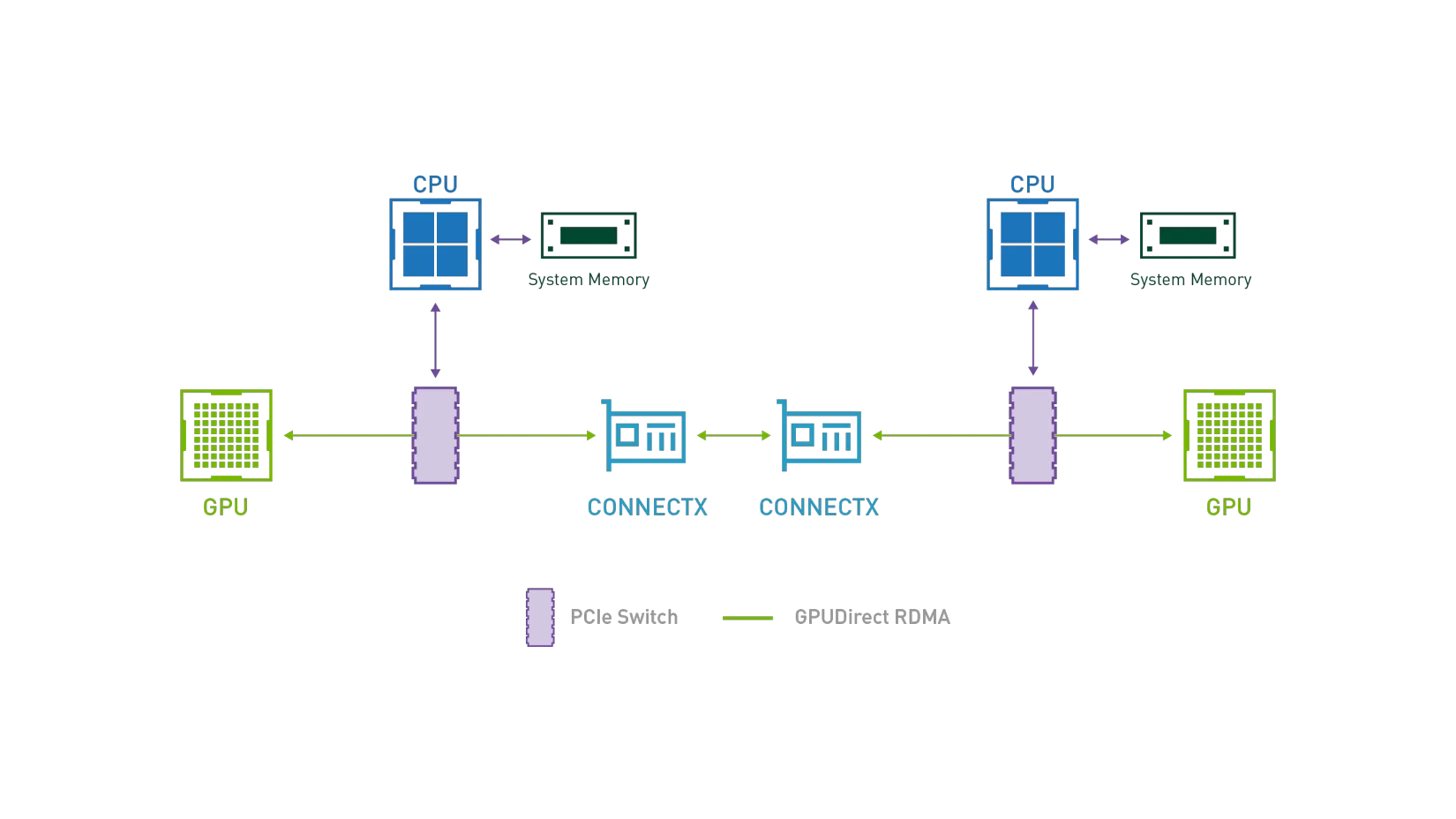 In AI model training scenarios, GPUs frequently require collective communication to synchronize updated weights during training iterations. GDR (GPUDirect RDMA) aims to solve the efficiency problem of exchanging data between multi-machine GPU devices. By using GDR technology, GPUs can exchange data directly without involving CPUs or memory, significantly reducing CPU/Memory overhead while lowering latency. To achieve this goal, Koordinator v1.6.0 introduces GPU/RDMA device joint scheduling capabilities, with the overall architecture outlined below:
In AI model training scenarios, GPUs frequently require collective communication to synchronize updated weights during training iterations. GDR (GPUDirect RDMA) aims to solve the efficiency problem of exchanging data between multi-machine GPU devices. By using GDR technology, GPUs can exchange data directly without involving CPUs or memory, significantly reducing CPU/Memory overhead while lowering latency. To achieve this goal, Koordinator v1.6.0 introduces GPU/RDMA device joint scheduling capabilities, with the overall architecture outlined below:
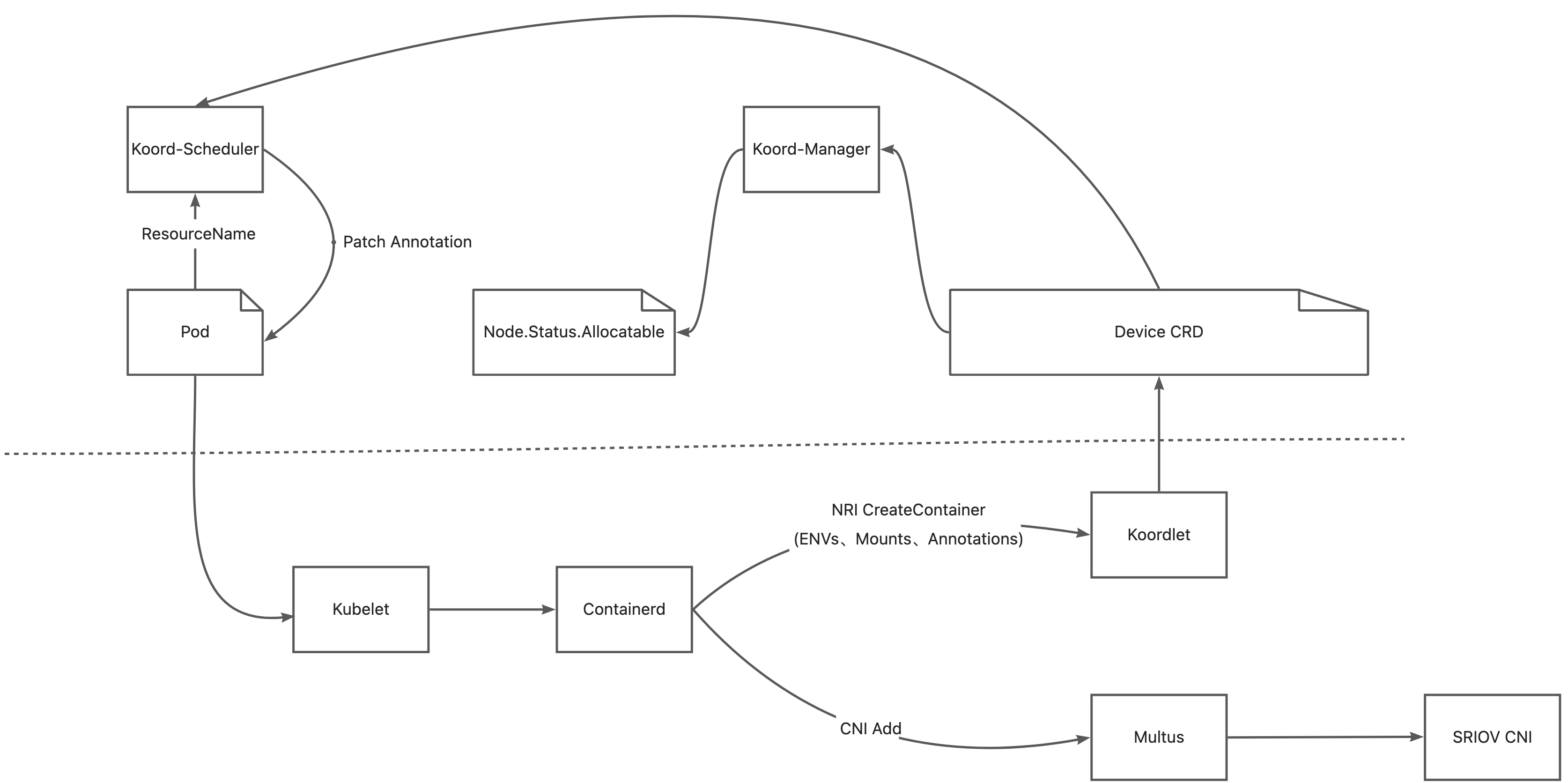
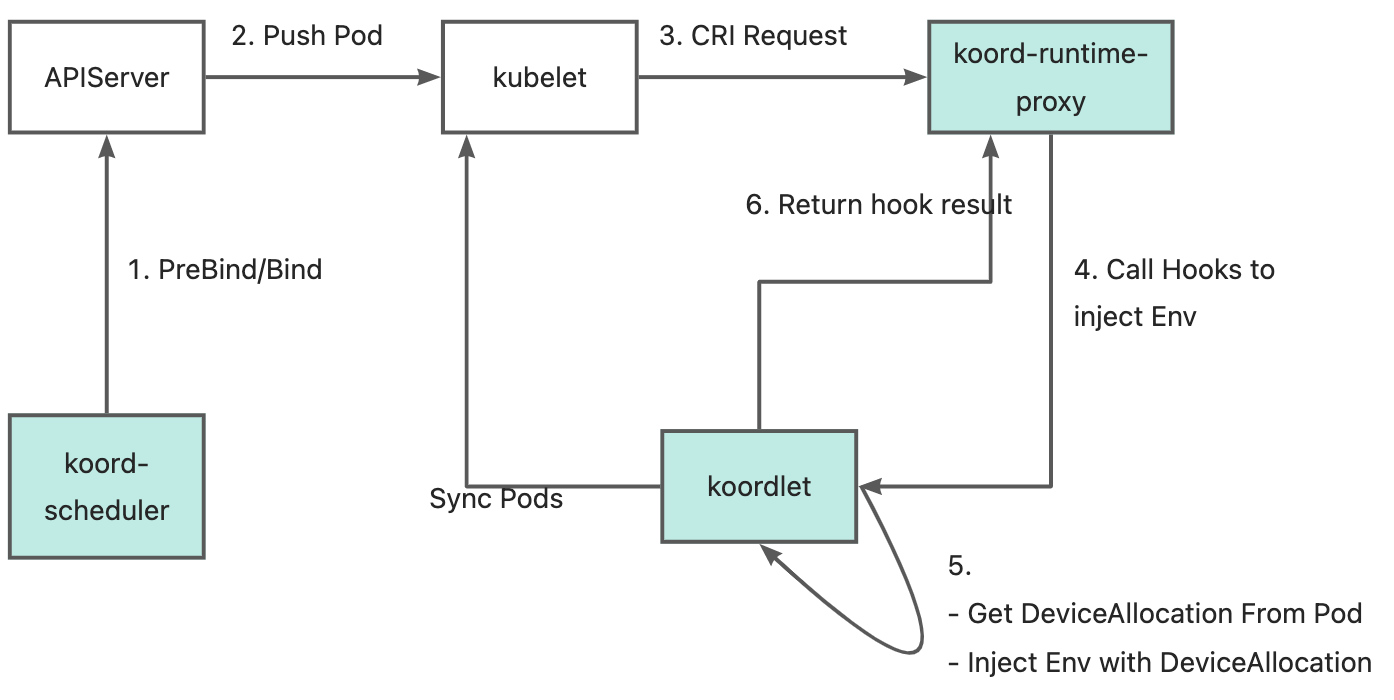
- Koordlet detects GPUs and RDMA devices on nodes and reports relevant information to the Device CR.
- Koord-Manager synchronizes resources from the Device CR to node.status.allocatable.
- Koord-Scheduler allocates GPUs and RDMA based on device topology and annotates allocation results onto Pods.
- Multus-CNI accesses Koordlet PodResources Proxy to obtain RDMA devices allocated to Pods and attaches corresponding NICs to the Pods' network namespaces.
- Koordlet provides an NRI plugin to mount devices into containers.
Due to the involvement of numerous components and complex environments, Koordinator v1.6.0 provides best practices showcasing step-by-step deployments of Koordinator, Multus-CNI, and SRIOV-CNI. After deploying the necessary components, users can simply adopt the following Pod configuration to request joint GPU and RDMA allocations from the scheduler:
apiVersion: v1
kind: Pod
metadata:
name: pod-vf01
namespace: kubeflow
annotations:
scheduling.koordinator.sh/device-joint-allocate: |-
{
"deviceTypes": ["gpu","rdma"]
}
scheduling.koordinator.sh/device-allocate-hint: |-
{
"rdma": {
"vfSelector": {} //apply VF
}
}
spec:
schedulerName: koord-scheduler
containers:
- name: container-vf
resources:
requests:
koordinator.sh/gpu: 100
koordinator.sh/rdma: 100
limits:
koordinator.sh/gpu: 100
koordinator.sh/rdma: 100
For further end-to-end testing of GDR tasks using Koordinator, you can refer to the sample steps in the best practices. Special thanks to community developer @ferris-cx for contributing to this feature!
3. Strong GPU Sharing Isolation: Improving Resource Utilization for AI Inference Tasks
In AI applications, GPUs are indispensable core devices for large model training and inference, providing powerful computational capabilities for compute-intensive tasks. However, this powerful computing capability often comes with high costs. In production environments, we frequently encounter situations where small models or lightweight inference tasks only require a fraction of GPU resources (e.g., 20% of compute power or GPU memory), yet a high-performance GPU card must be exclusively occupied to run these tasks. This resource usage method not only wastes valuable GPU computing power but also significantly increases enterprise costs.
This situation is particularly common in the following scenarios:
- Online Inference Services: Many online inference tasks have low computational demands but require high latency responsiveness, often needing deployment on high-performance GPUs to meet real-time requirements.
- Development and Testing Environments: Developers debugging models usually only need a small amount of GPU resources, but traditional scheduling methods lead to low resource utilization.
- Multi-Tenant Shared Clusters: In multi-user or multi-team shared GPU clusters, each task monopolizing a GPU leads to uneven resource distribution, making it difficult to fully utilize hardware capabilities.
To address this issue, Koordinator, combined with HAMi, provides GPU sharing and isolation capabilities, allowing multiple Pods to share a single GPU card. This approach not only significantly improves GPU resource utilization but also reduces enterprise costs while meeting flexible resource demands for different tasks. For example, under Koordinator’s GPU sharing mode, users can precisely allocate GPU cores or memory ratios, ensuring each task receives the required resources while avoiding interference.
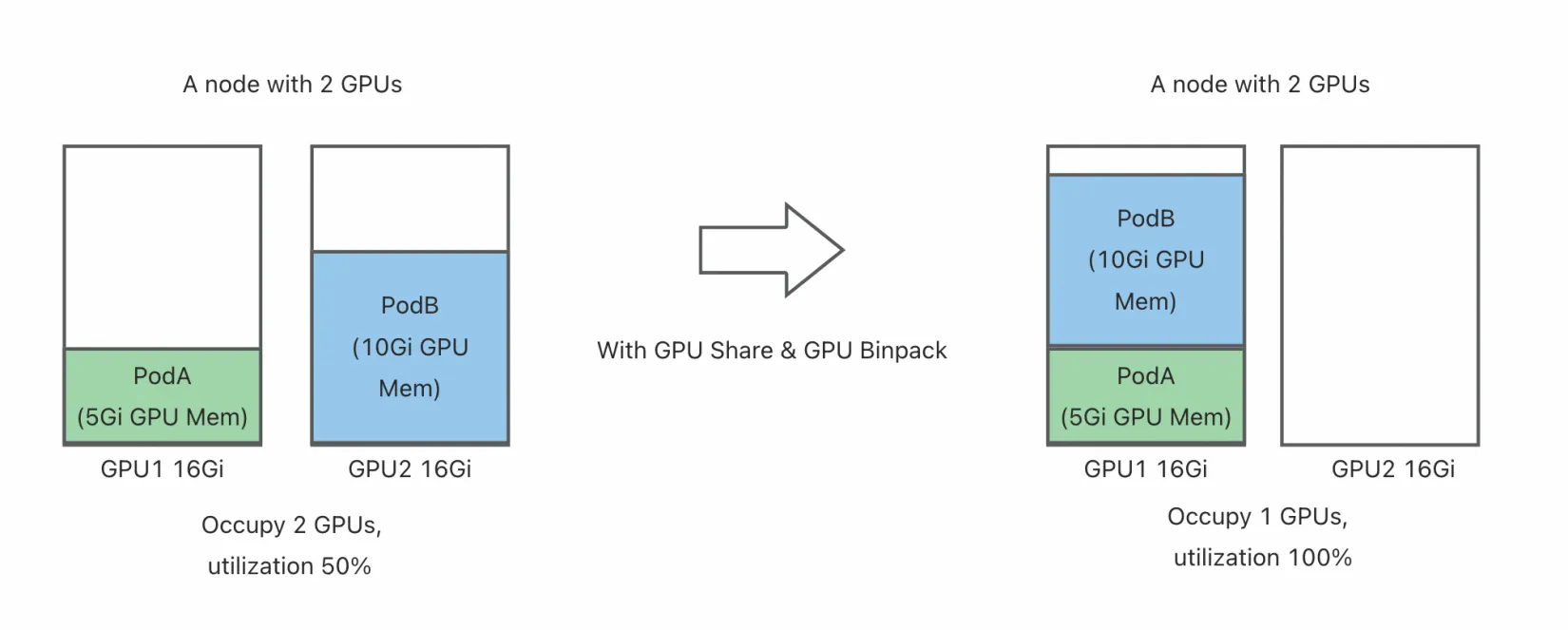
HAMi is a CNCF Sandbox project aimed at providing a device management middleware for Kubernetes. HAMi-Core, its core module, hijacks API calls between CUDA-Runtime (libcudart.so) and CUDA-Driver (libcuda.so) to provide GPU sharing and isolation capabilities. In v1.6.0, Koordinator leverages HAMi-Core’s GPU isolation features to offer an end-to-end GPU sharing solution.
You can deploy DaemonSet directly on corresponding nodes to install HAMi-core using the YAML file below:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: hami-core-distribute
namespace: default
spec:
selector:
matchLabels:
koord-app: hami-core-distribute
template:
metadata:
labels:
koord-app: hami-core-distribute
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-type
operator: In
values:
- "gpu"
containers:
- command:
- /bin/sh
- -c
- |
cp -f /k8s-vgpu/lib/nvidia/libvgpu.so /usl/local/vgpu && sleep 3600000
image: docker.m.daocloud.io/projecthami/hami:v2.4.0
imagePullPolicy: Always
name: name
resources:
limits:
cpu: 200m
memory: 256Mi
requests:
cpu: "0"
memory: "0"
volumeMounts:
- mountPath: /usl/local/vgpu
name: vgpu-hook
- mountPath: /tmp/vgpulock
name: vgpu-lock
tolerations:
- operator: Exists
volumes:
- hostPath:
path: /usl/local/vgpu
type: DirectoryOrCreate
name: vgpu-hook
# https://github.com/Project-HAMi/HAMi/issues/696
- hostPath:
path: /tmp/vgpulock
type: DirectoryOrCreate
name: vgpu-lock
Koordinator scheduler's GPU Binpack capability is enabled by default. After installing Koordinator and HAMi-Core, users can apply for shared GPU cards and enable HAMi-Core isolation as follows:
apiVersion: v1
kind: Pod
metadata:
name: pod-example
namespace: default
labels:
koordinator.sh/gpu-isolation-provider: hami-core
spec:
schedulerName: koord-scheduler
containers:
- command:
- sleep
- 365d
image: busybox
imagePullPolicy: IfNotPresent
name: curlimage
resources:
limits:
cpu: 40m
memory: 40Mi
koordinator.sh/gpu-shared: 1
koordinator.sh/gpu-core: 50
koordinator.sh/gpu-memory-ratio: 50
requests:
cpu: 40m
memory: 40Mi
koordinator.sh/gpu-shared: 1
koordinator.sh/gpu-core: 50
koordinator.sh/gpu-memory-ratio: 50
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
restartPolicy: Always
For guidance on enabling HAMi GPU sharing isolation capabilities in Koordinator, please refer to:
Special thanks to HAMi community maintainer @wawa0210 for supporting this feature!
4. Differentiated GPU Scheduling Policies: Effectively Reducing GPU Fragmentation
In modern Kubernetes clusters, various types of resources (such as CPU, memory, and GPU) are typically managed on a unified platform. However, the usage patterns and demands for different resources often vary significantly, leading to differing needs for stacking (Packing) and spreading (Spreading) strategies. For example:
- GPU Resources: In AI model training or inference tasks, to maximize GPU utilization and reduce fragmentation, users generally prefer to schedule GPU tasks onto nodes that already have GPUs allocated ("stacking" strategy). This prevents resource waste caused by overly dispersed GPU distributions.
- CPU and Memory Resources: In contrast, CPU and memory resource demands are more diverse. For some online services or batch processing tasks, users tend to distribute tasks across multiple nodes ("spreading" strategy) to avoid hotspots on individual nodes, thereby improving overall cluster stability and performance.
Additionally, in mixed workload scenarios, different tasks’ resource demands can influence each other. For instance:
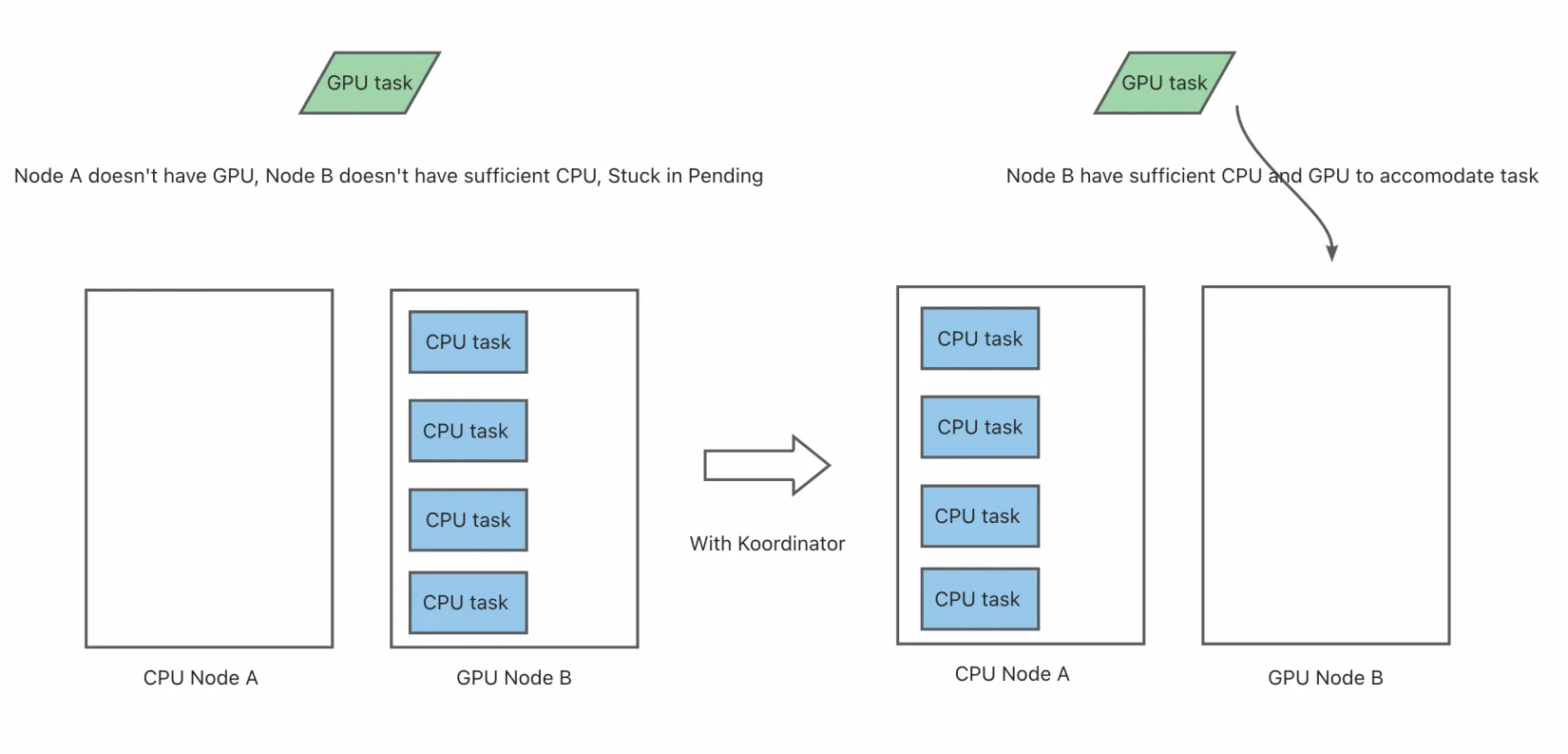
- In a cluster running both GPU training tasks and regular CPU-intensive tasks, if CPU-intensive tasks are scheduled onto GPU nodes and consume significant CPU and memory resources, subsequent GPU tasks may fail to start due to insufficient non-GPU resources, remaining in a Pending state.
- In multi-tenant environments, some users may only request CPU and memory resources, while others need GPU resources. If the scheduler cannot distinguish these needs, it may lead to resource contention and unfair resource allocation.
 The native Kubernetes NodeResourcesFit plugin currently supports configuring the same scoring strategy for different resources, as shown below:
The native Kubernetes NodeResourcesFit plugin currently supports configuring the same scoring strategy for different resources, as shown below:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- name: NodeResourcesFit
args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: NodeResourcesFitArgs
scoringStrategy:
type: LeastAllocated
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: nvidia.com/gpu
weight: 1
However, in practical production settings, this design may not always be suitable. For example, in AI scenarios, GPU-requesting jobs prefer to occupy entire GPU machines to prevent GPU fragmentation, whereas CPU&MEM jobs prefer spreading to reduce CPU hotspots. In v1.6.0, Koordinator introduces the NodeResourceFitPlus plugin to support differentiated scoring strategies for different resources. Users can configure it upon installing Koordinator scheduler as follows:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: NodeResourcesFitPlusArgs
resources:
nvidia.com/gpu:
type: MostAllocated
weight: 2
cpu:
type: LeastAllocated
weight: 1
memory:
type: LeastAllocated
weight: 1
name: NodeResourcesFitPlus
plugins:
score:
enabled:
- name: NodeResourcesFitPlus
weight: 2
schedulerName: koord-scheduler
Moreover, CPU&MEM jobs would prefer to spread to non-GPU machines to prevent excessive consumption of CPU&MEM on GPU machines, which could cause true GPU tasks to remain Pending due to insufficient non-GPU resources. In v1.6.0, Koordinator introduces the ScarceResourceAvoidance plugin to support this requirement. Users can configure the scheduler as follows, indicating that nvidia.com/gpu is a scarce resource, and when Pods do not request this scarce resource, they should avoid being scheduled onto nodes possessing it.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: ScarceResourceAvoidanceArgs
resources:
- nvidia.com/gpu
name: ScarceResourceAvoidance
plugins:
score:
enabled:
- name: NodeResourcesFitPlus
weight: 2
- name: ScarceResourceAvoidance
weight: 2
disabled:
- name: "*"
schedulerName: koord-scheduler
For detailed designs and user guides on GPU resource differentiated scheduling policies, please refer to:
Special thanks to community developer @LY-today for contributing to this feature.
5. Fine-Grained Resource Reservation: Meeting Efficient Operation Needs for AI Tasks
Efficient utilization of heterogeneous resources often relies on precise alignment with closely coupled CPU and NUMA resources. For example:
- GPU-Accelerated Tasks: In multi-NUMA node servers, if the physical connection between GPU and CPU or memory spans NUMA boundaries, it may increase data transmission latency, significantly reducing task performance. Therefore, such tasks typically require GPU, CPU, and memory to be allocated on the same NUMA node.
- AI Inference Services: Online inference tasks are highly sensitive to latency and need to ensure GPU and CPU resource allocations are as close as possible to minimize cross-NUMA node communication overhead.
- Scientific Computing Tasks: Some high-performance computing tasks (e.g., molecular dynamics simulations or weather forecasting) require high-bandwidth, low-latency memory access, necessitating strict alignment of CPU cores and local memory.
These requirements extend beyond task scheduling to resource reservation scenarios. In production environments, resource reservation is an important mechanism for locking resources in advance for critical tasks, ensuring smooth operation at a future point in time. However, simple resource reservation mechanisms often fail to meet fine-grained orchestration needs in heterogeneous resource scenarios. For example:
- Certain tasks may need to reserve specific NUMA node CPU and GPU resources to guarantee optimal performance upon task startup.
- In multi-tenant clusters, different users may need to reserve different combinations of resources (e.g., GPU + CPU + memory) and expect these resources to be strictly aligned.
- When reserved resources are not fully utilized, how to flexibly allocate remaining resources to other tasks without affecting reserved task resource guarantees is another important challenge.
To address these complex scenarios, Koordinator comprehensively enhances resource reservation functionality in v1.6, providing more refined and flexible resource orchestration capabilities. Specific improvements include:
- Supporting fine-grained CPU and GPU resource reservations and preemption.
- Supporting exact matching of reserved resource quantities for Pods.
- Reservation affinity supports specifying reservation names and taint tolerance attributes.
- Resource reservation supports limiting the number of Pods.
- Supporting preempting lower-priority Pods with reserved resources.
Changes to plugin extension interfaces:
- The reservation validation interface ReservationFilterPlugin is moved from the PreScore phase to the Filter phase to ensure more accurate filtering results.
- The reservation ledger return interface ReservationRestorePlugin deprecates unnecessary methods to improve scheduling efficiency.
Below are examples of new functionalities:
- Exact-Match Reservation. Specify Pods to exactly match reserved resource quantities, which can narrow down the matching relationship between a group of Pods and a group of reservations, making reservation allocation more controllable.
apiVersion: v1
kind: Pod
metadata:
annotations:
# Specify the resource categories for which the Pod exactly matches reserved resources; Pods can only match Reservation objects whose reserved resource quantities and Pod specifications are completely equal in these resource categories; e.g., specify "cpu", "memory", "nvidia.com/gpu"
scheduling.koordinator.sh/exact-match-reservation: '{"resourceNames":{"cpu","memory","nvidia.com/gpu"}}'
- Ignore Resource Reservations (reservation-ignored). Specify Pods to ignore resource reservations, allowing Pods to fill idle resources on nodes with reservations but unallocated, complementing preemption to reduce resource fragmentation.
apiVersion: v1
kind: Pod
metadata:
labels:
# Specify that the Pod’s scheduling can ignore resource reservations
scheduling.koordinator.sh/reservation-ignored: "true"
- Specify Reservation Name Affinity (ReservationAffinity)
apiVersion: v1
kind: Pod
metadata:
annotations:
# Specify the name of the resource reservation matched by the Pod
scheduling.koordinator.sh/reservation-affinity: '{"name":"test-reservation"}'
- Specify Taints and Tolerations for Resource Reservations
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Reservation
metadata:
name: test-reservation
spec:
# Specify Taints for the Reservation; its reserved resources can only be allocated to Pods tolerating this taint
taints:
- effect: NoSchedule
key: test-taint-key
value: test-taint-value
# ...
---
apiVersion: v1
kind: Pod
metadata:
annotations:
# Specify the Pod’s toleration for resource reservation taints
scheduling.koordinator.sh/reservation-affinity: '{"tolerations":[{"key":"test-taint-key","operator":"Equal","value":"test-taint-value","effect":"NoSchedule"}]}'
- Enable Reservation Preemption
Note: Currently, high-priority Pods preempting low-priority Reservations is not supported.
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- pluginConfigs:
- name: Reservation
args:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: ReservationArgs
enablePreemption: true
# ...
plugins:
postFilter:
# Disable DefaultPreemption plugin’s preemption in scheduler configuration, enable Reservation plugin’s preemption
- disabled:
- name: DefaultPreemption
# ...
- enabled:
- name: Reservation
Special thanks to community developer @saintube for contributing to this feature!
6. Co-location: Mid-tier Supports Idle Resource Reallocation, Enhances Pod-Level QoS Configuration
In modern data centers, co-location technology has become an important means to improve resource utilization. By mixing latency-sensitive tasks (e.g., online services) with resource-intensive tasks (e.g., offline batch processing) on the same cluster, enterprises can significantly reduce hardware costs and improve resource efficiency. However, as the resource water level in co-located clusters continues to rise, ensuring resource isolation between different types of tasks becomes a key challenge.
In co-location scenarios, the core objectives of resource isolation capabilities are:
- Guaranteeing High-Priority Task Performance: For example, online services require stable CPU, memory, and I/O resources to meet low-latency requirements.
- Fully Utilizing Idle Resources: Offline tasks should utilize as much unused resource from high-priority tasks as possible without interfering with them.
- Dynamically Adjusting Resource Allocation: Real-time adjustment of resource allocation strategies based on node load changes to avoid resource contention or waste.
To achieve these goals, Koordinator continuously builds and refines resource isolation capabilities. In v1.6, we focused on optimizing resource oversubscription and co-location QoS with a series of functional optimizations and bug fixes, specifically including:
- Optimizing calculation logic for Mid resource oversubscription and node profiling features, supporting oversubscription of unallocated node resources to avoid double oversubscription of node resources.
- Optimizing metric degradation logic for load-aware scheduling. Supporting Pod-level configuration for CPU QoS and Resctrl QoS.
- Supplementing Prometheus metrics for out-of-band load management to enhance observability.
- Bugfixes for Blkio QoS, resource amplification, and other features.
Mid resource oversubscription was introduced starting from Koordinator v1.3, providing dynamic resource oversubscription capabilities based on Node Profiling. However, to ensure the stability of oversubscribed resources, Mid resources are entirely sourced from Prod pods already allocated on nodes, meaning no Mid resources exist on empty nodes initially, posing inconveniences for some workloads using Mid resources. The Koordinator community received feedback and contributions from some enterprise users.
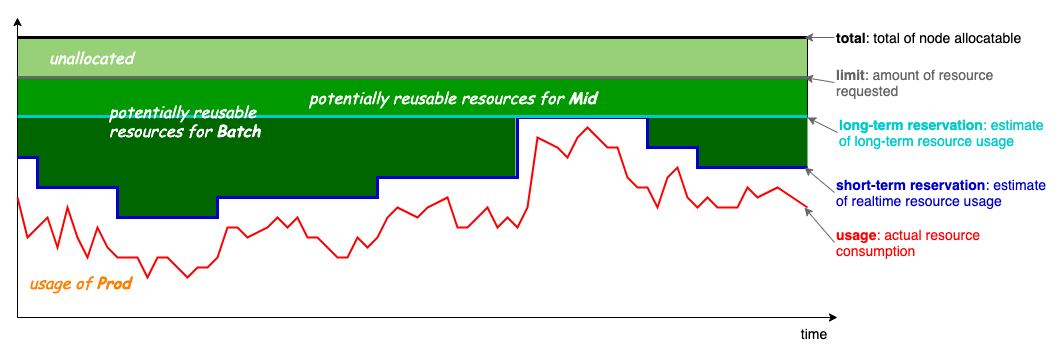 In v1.6, Koordinator updated the oversubscription formula as follows:
In v1.6, Koordinator updated the oversubscription formula as follows:
MidAllocatable := min(ProdReclaimable, NodeAllocatable * thresholdRatio) + ProdUnallocated * unallocatedRatio
ProdReclaimable := min(max(0, ProdAllocated - ProdPeak * (1 + safeMargin)), NodeUnused)
There are two changes in the calculation logic:
- Supporting static proportional oversubscription of unallocated resources to improve cold start issues.
- Disallowing oversubscription of actually used node resources to avoid overestimated predictions caused by secondary oversubscription scenarios; for example, some users leverage Koordinator’s node resource amplification capabilities to schedule more Prod pods, causing ProdAllocated > NodeAllocatable, leading to MidAllocatable predictions deviating from actual node loads.
Additionally, in terms of co-location QoS, Koordinator v1.6 enhances Pod-level QoS policy configuration capabilities, applicable to scenarios such as adding blacklisted interfering Pods on co-located nodes and gray-scale adjustments to co-location QoS usage:
- Resctrl feature, supporting LLC and memory bandwidth isolation capabilities at the Pod level.
- CPU QoS feature, supporting CPU QoS configuration at the Pod level.
The Resctrl feature can be enabled at the Pod level as follows:
- Enable the Resctrl feature in Koordlet’s feature-gate.
- Configure LLC and memory bandwidth (MB) restriction policies via Pod Annotation protocol node.koordinator.sh/resctrl. For example,
apiVersion: v1
kind: Pod
metadata:
annotations:
node.koordinator.sh/resctrl: '{"llc": {"schemata": {"range": [0, 30]}}, "mb": {"schemata": {"percent": 20}}}'
Pod-level CPU QoS configuration can be enabled as follows:
- Enable CPU QoS, please refer to: https://koordinator.sh/docs/user-manuals/cpu-qos/
- Configure Pod CPU QoS policies via Pod Annotation protocol koordinator.sh/cpuQOS. For example,
apiVersion: v1
kind: Pod
metadata:
annotations:
koordinator.sh/cpuQOS: '{"groupIdentity": 1}'
Special thanks to @kangclzjc, @j4ckstraw, @lijunxin559, @tan90github, @yangfeiyu20102011 and other community developers for their contributions to co-location related features!
7. Scheduling, Rescheduling: Continuously Improved Operational Efficiency
With the continuous development of cloud-native technologies, more and more enterprises are migrating core businesses to Kubernetes platforms, resulting in explosive growth in cluster scale and task numbers. This trend brings significant technical challenges, especially in terms of scheduling performance and rescheduling strategies:
- Scheduling Performance Requirements: As cluster sizes expand, the number of tasks schedulers need to handle surges dramatically, placing higher demands on scheduler performance and scalability. For instance, in large-scale clusters, how to quickly complete Pod scheduling decisions and reduce scheduling latency becomes a key issue.
- Rescheduling Strategy Requirements: In multi-tenant environments, intensified resource competition may cause frequent rescheduling, leading to workloads repeatedly migrating between nodes, thereby increasing system burden and affecting cluster stability. Additionally, how to reasonably allocate resources to avoid hotspot issues while ensuring stable operation of production tasks has become a critical consideration in designing rescheduling strategies.
To address these challenges, Koordinator comprehensively optimized the scheduler and rescheduler in v1.6.0, aiming to improve scheduling performance and enhance the stability and rationality of rescheduling strategies. Below are our optimizations for scheduler performance in the current version:
- Moving MinMember checks for PodGroups to PreEnqueue to reduce unnecessary scheduling cycles.
- Delaying resource returns for Reservations to the AfterPreFilter stage, performing resource returns only on nodes allowed by PreFilterResult to reduce algorithm complexity.
- Optimizing CycleState distributions for plugins like NodeNUMAResource, DeviceShare, and Reservation to reduce memory overhead.
- Adding delay metrics for additional extension points introduced by Koordinator, such as BeforePreFilter and AfterPreFilter.
As cluster scales continue to grow, the stability and rationality of the rescheduling process become focal concerns. Frequent evictions may cause workloads to repeatedly migrate between nodes, increasing system burden and posing stability risks. To this end, we conducted several optimizations for the rescheduler in v1.6.0:
- LowNodeLoad Plugin Optimization:
- The LowNodeLoad plugin now supports configuring ProdHighThresholds and ProdLowThresholds, combining Koordinator priorities (Priority) to manage workload resource utilization differently, reducing hotspot issues caused by production applications and achieving finer-grained load balancing;
- Optimized sorting logic for candidate eviction Pods, selecting the most suitable Pods for eviction through segmented function scoring algorithms to ensure reasonable resource allocation and avoid stability issues caused by evicting the most resource-utilized Pods;
- Optimized pre-eviction checks for Pods; LowNodeLoad checks whether target nodes might become new hotspot nodes before evicting Pods, effectively preventing repeated rescheduling occurrences.
- MigrationController Enhancement:
- MigrationController possesses ObjectLimiter capabilities, controlling workload eviction frequency over a certain period. It now supports namespace-level eviction throttling, providing more granular control over evictions within namespaces; simultaneously moving ObjectLimiter from Arbitrator to inside MigrationController, fixing potential throttling failures in concurrent scenarios;
- Added EvictAllBarePods configuration item, allowing users to enable eviction of Pods without OwnerRef, thus increasing rescheduling flexibility;
- Added MaxMigratingGlobally configuration item, enabling MigrationController to independently control the maximum number of Pod evictions, thereby reducing stability risks;
- Optimized GetMaxUnavailable method calculation logic, adjusting downward-rounded calculations of workload maximum unavailable replicas to 1 when it rounds down to 0, avoiding loss of accuracy and consistency in user-controlled replica unavailability expectations.
- Added global rescheduling parameter MaxNoOfPodsToEvictTotal, ensuring the rescheduler’s global maximum number of Pod evictions, reducing cluster burden and enhancing stability;
Special thanks to community developers @AdrianMachao, @songtao98, @LY-today, @zwForrest, @JBinin, @googs1025, @bogo-y for their contributions to scheduling and rescheduling optimizations!
Future Plans
The Koordinator community will continue focusing on strengthening GPU resource management and scheduling functions, providing rescheduling plugins to further resolve GPU fragmentation issues caused by imbalanced resource allocation, and plans to introduce more new features and functionalities in the next version to support more complex workload scenarios; meanwhile, in resource reservation and co-location, we will further optimize to support finer-grained scenarios.
Currently planned Proposals in the community are as follows:
- Fine-Grained Device Scheduling Support for Ascend NPU
- Providing Rescheduling Plugins to Solve Imbalanced Resource Issues
- Reservation Support for Binding Allocated Pods
Key usage issues to be addressed include:
Long-term planned Proposals include:
We encourage user feedback on usage experiences and welcome more developers to participate in the Koordinator project, jointly driving its development!
 Vote address:
Vote address: