Fine-grained device scheduling
Summary
This proposal provides a fine-grained mechanism for managing GPUs and other devices such as RDMA and FPGA, defines a set of APIs to describe device information on nodes, including GPU, RDMA, and FPGA, and a new set of resource names to flexibly support users to apply at a finer granularity GPU resources. This mechanism is the basis for subsequent other GPU scheduling capabilities such as GPU Share, GPU Overcommitment, etc.
Motivation
GPU devices have very strong computing power, but are expensive. How to make better use of GPU equipment, give full play to the value of GPU and reduce costs is a problem that needs to be solved. In the existing GPU allocation mechanism of the K8s community, the GPU is allocated by the kubelet, and it is a complete device allocation. This method is simple and reliable, but similar to the CPU and memory, the GPU will also be wasted. Therefore, some users expect to use only a portion of the GPU's resources and share the rest with other workloads to save costs. Moreover, GPU has particularities. For example, the NVLink and oversold scenarios supported by NVIDIA GPU mentioned below both require a central decision through the scheduler to obtain globally optimal allocation results.
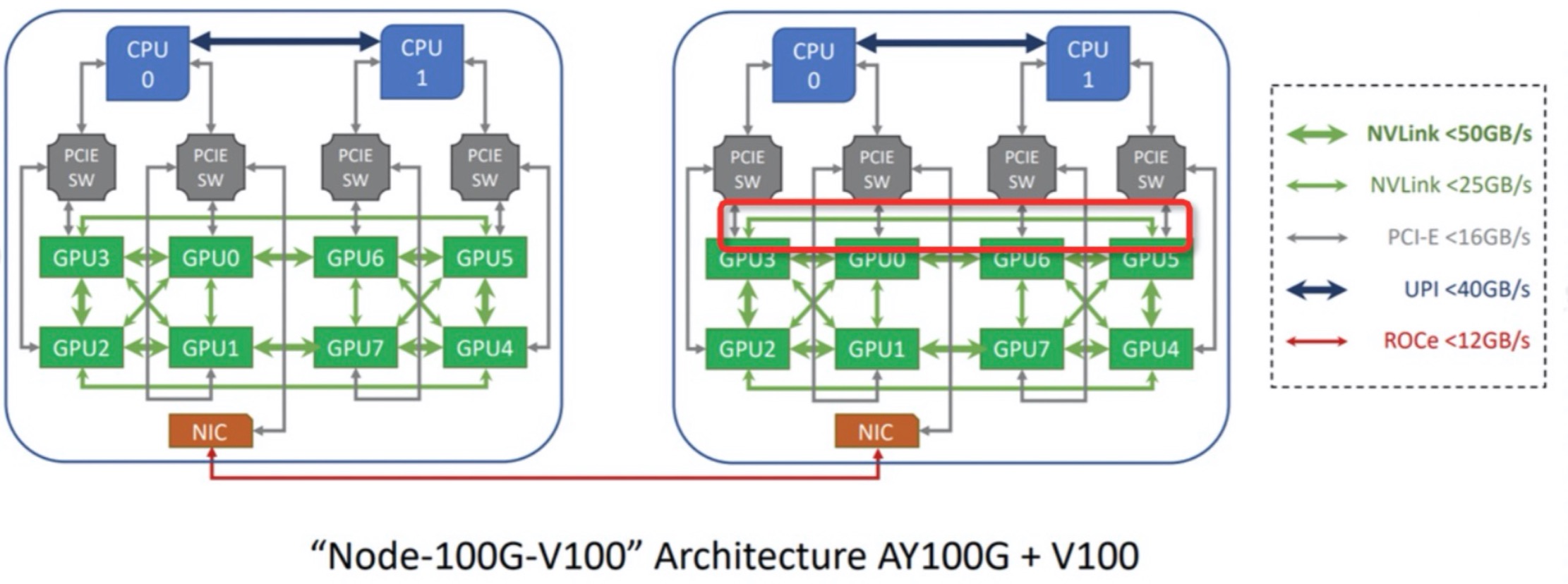
From the picture, we can find that although the node has 8 GPU instances whose model is A100/V100, the data transmission speed between GPU instances is different. When a Pod requires multiple GPU instances, we can assign the Pod the GPU instances with the maximum data transfer speed combined relationship. In addition, when we want the GPU instances among a group of Pods to have the maximum data transfer speed combined relationship, the scheduler should batch allocate the best GPU instances to these Pods and assign them to the same node.
Goals
- Definition Device CRD and the Resource API.
- Provides a reporter component in koordlet to report Device information and resource capacities.
- Provides a scheduler plugin to support users to apply at a finer granularity GPU resources.
- Provider a new runtime hook plugin in koordlet to support update the environments of containers with GPUs that be allocated by scheduler.
Non-goals/Future work
- Define flexible allocation strategies, such as implementing BinPacking or Spread according to GPU resources
Proposal
API
Device resource dimensions
Due to GPU is complicated, we will introduce GPU first. As we all know there is compute and GPU Memory capability for the GPU device. Generally user apply GPU like "I want 1/2/4/8 GPUs", but if node support GPU level isolation mechanism, user may apply GPU like "I want 0.5/0.25 GPU resources". Moreover, user may set different compute capability and GPU memory capability for best resource utilization, so the user want apply GPU like "I want X percent of "compute capability and Y percent of memory capability".
We abstract GPU resources into different dimensions:
kubernetes.io/gpu-corerepresents the computing capacity of the GPU. Similar to K8s MilliCPU, we abstract the total computing power of GPU into one hundred, and users can apply for the corresponding amount of GPU computing power according to their needs.kubernetes.io/gpu-memoryrepresents the memory capacity of the GPU in bytes.kubernetes.io/gpu-memory-ratiorepresents the percentage of the GPU's memory.
Assuming that node A has 4 GPU instances, and the total memory of each instance is 8GB, when device reporter reports GPU capacity information to Node.Status.Allocatable, it no longer reports nvidia.com/gpu=4, but reports the following information:
status:
capacity:
kubernetes.io/gpu-core: 400
kubernetes.io/gpu-memory: "32GB"
kubernetes.io/gpu-memory-ratio: 400
allocatable:
kubernetes.io/gpu-core: 400
kubernetes.io/gpu-memory: "32GB"
kubernetes.io/gpu-memory-ratio: 400
For the convenience of users, an independent resource name kubernetes.io/gpu is defined. For example, when a user wants to use half of the computing resources and memory resources of a GPU instance, the user can directly declare kubernetes.io/gpu: 50, and the scheduler will convert it to kubernetes.io/gpu-core: 50, kubernetes.io/gpu-memory-ratio: 50
For other devices like RDMA and FPGA, the node has 1 RDMA and 1 FGPA, will report the following information:
status:
capacity:
kubernetes.io/rdma: 100
kubernetes.io/fpga: 100
allocatable:
kubernetes.io/rdma: 100
kubernetes.io/fpga: 100
Why do we need kubernetes.io/gpu-memory-ratio and kubernetes.io/gpu-memory ?
When user apply 0.5/0.25 GPU, the user don't know the exact memory total bytes per GPU, only wants to use
half or quarter percentage of memory, so user can request the GPU memory with kubernetes.io/gpu-memory-ratio.
When scheduler assigned Pod on concrete node, scheduler will translate the kubernetes.io/gpu-memory-ratio to kubernetes.io/gpu-memory by the formulas: allocatedMemory = totalMemoryOf(GPU) kubernetes.io/gpu-memory-ratio*, so that the GPU isolation can work.
During the scheduling filter phase, the scheduler will do special processing for kubernetes.io/gpu-memory and kubernetes.io/gpu-memory-ratio. When a Pod specifies kubernetes.io/gpu-memory-ratio, the scheduler checks each GPU instance on each node for unallocated or remaining resources to ensure that the remaining memory on each GPU instance meets the ratio requirement.
If the user knows exactly or can roughly estimate the specific memory consumption of the workload, he can apply for GPU memory through kubernetes.io/gpu-memory. All details can be seen below.
Besides, when dimension's value > 100, means Pod need multi-devices. now only allow the value can be divided by 100.
User apply device resources scenarios
Compatible with nvidia.com/gpu
resources:
requests:
nvidia.com/gpu: "2"
cpu: "4"
memory: "8Gi"
The scheduler translates the nvida.com/gpu: 2 to the following spec:
resources:
requests:
kubernetes.io/gpu-core: "200"
kubernetes.io/gpu-memory-ratio: "200"
kubernetes.io/gpu-memory: "16Gi" # assume 8G memory in bytes per GPU
cpu: "4"
memory: "8Gi"
Apply whole resources of GPU or part resources of GPU
resources:
requests:
kubernetes.io/gpu: "50"
cpu: "4"
memory: "8Gi"
The scheduler translates the kubernetes.io/gpu: "50" to the following spec:
resources:
requests:
kubernetes.io/gpu-core: "50"
kubernetes.io/gpu-memory-ratio: "50"
kubernetes.io/gpu-memory: "4Gi" # assume 8G memory in bytes for the GPU
cpu: "4"
memory: "8Gi"
Apply kubernetes.io/gpu-core and kubernetes.io/gpu-memory-ratio separately
resources:
requests:
kubernetes.io/gpu-core: "50"
kubernetes.io/gpu-memory-ratio: "60"
cpu: "4"
memory: "8Gi"
Apply kubernetes.io/gpu-core and kubernetes.io/gpu-memory separately
resources:
requests:
kubernetes.io/gpu-core: "60"
kubernetes.io/gpu-memory: "4Gi"
cpu: "4"
memory: "8Gi"
Apply RDMA
resources:
requests:
kubernetes.io/rdma: "100"
cpu: "4"
memory: "8Gi"
Implementation Details
Scheduling
- Abstract new data structure to describe resources and healthy status per device on the node.
- Implements the Filter/Reserve/PreBind extenstion points.
- Automatically recognize different kind devices. When a new device added, we don't need modify any code
DeviceAllocation
In the PreBind stage, the scheduler will update the device (including GPU) allocation results, including the device's Minor and resource allocation information, to the Pod in the form of annotations.
/*
{
"gpu": [
{
"minor": 0,
"resouurces": {
"kubernetes.io/gpu-core": 100,
"kubernetes.io/gpu-mem-ratio": 100,
"kubernetes.io/gpu-mem": "16Gi"
}
},
{
"minor": 1,
"resouurces": {
"kubernetes.io/gpu-core": 100,
"kubernetes.io/gpu-mem-ratio": 100,
"kubernetes.io/gpu-mem": "16Gi"
}
}
]
}
*/
type DeviceAllocation struct {
Minor int32
Resources map[string]resource.Quantity
}
type DeviceAllocations map[DeviceType][]*DeviceAllocation
NodeDevicePlugin
var (
_ framework.PreFilterPlugin = &NodeDevicePlugin{}
_ framework.FilterPlugin = &NodeDevicePlugin{}
_ framework.ReservePlugin = &NodeDevicePlugin{}
_ framework.PreBindPlugin = &NodeDevicePlugin{}
)
type NodeDevicePlugin struct {
frameworkHandler framework.Handle
nodeDeviceCache *NodeDeviceCache
}
type NodeDeviceCache struct {
lock sync.Mutex
nodeDevices map[string]*nodeDevice
}
type nodeDevice struct {
lock sync.Mutex
DeviceTotal map[DeviceType]deviceResource
DeviceFree map[DeviceType]deviceResource
DeviceUsed map[DeviceType]deviceResource
AllocateSet map[DeviceType]*corev1.PodList
}
// We use `deviceResource` to present resources per device.
// "0": {kubernetes.io/gpu-core:100, kubernetes.io/gpu-memory-ratio:100, kubernetes.io/gpu-memory: 16GB}
// "1": {kubernetes.io/gpu-core:100, kubernetes.io/gpu-memory-ratio:100, kubernetes.io/gpu-memory: 16GB}
type deviceResources map[int]corev1.ResourceList
We will register node and device event handler to maintain device account.
- In Filter, we will make-up each device request by a node(the gpu-memory example), and try compare each device free resource and Pod device request.
- In Reserve/Unreserve, we will update nodeDeviceCache's used/free resource and allocateSet. Now device selection rule just based on device minor id order.
- In PreBind, we will write DeviceAllocations to Pod's annotation.
- In Init stage, we should list all Node/Device/Pods to recover device accounts.
Device Reporter
Implements a new component called Device Reporter in koordlet to create or update Device CRD instance with the resources information and healthy status per device including GPU, RDMA and FPGA, etc. This version we only support GPU. It will execution nccl commands to get each minor resource just like k8s-gpu-device-plugins. We will apply community health check logic.
Device CRD Scheme definition
type DeviceType string
const (
GPU DeviceType = "gpu"
FPGA DeviceType = "fpga"
RDMA DeviceType = "rdma"
)
type DeviceSpec struct {
Devices []DeviceInfo `json:"devices"`
}
type DeviceInfo struct {
// UUID represents the UUID of device
UUID string `json:"id,omitempty"`
// Minor represents the Minor number of Device, starting from 0
Minor int32 `json:"minor,omitempty"`
// Type represents the type of device
Type DeviceType `json:"deviceType,omitempty"`
// Health indicates whether the device is normal
Health bool `json:"health,omitempty"`
// Resources represents the total capacity of various resources of the device
Resources map[string]resource.Quantity `json:"resource,omitempty"`
}
type DeviceStatus struct {}
type Device struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec DeviceSpec `json:"spec,omitempty"`
Status DeviceStatus `json:"status,omitempty"`
}
type DeviceList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []Device `json:"items"`
}
Compatible
Considering that some users already have many existing GPU Pods in their clusters, it is necessary to ensure that Koordinator GPU Scheduling does not repeatedly allocate the GPU devices held by these GPU Pods. Therefore, koord-scheduler needs to obtain the GPU devices's information held by these existing Pods. These GPU devices are allocated by the kubelet and recorded in the local file /var/lib/kubelet/device-plugins/kubelet_internal_checkpoint, so the device reporter will parse the file to obtain the GPU Device ID assigned to each Pod. When parsing, it needs to exclude the Pod that allocates GPU through koord-scheduler, and finally update it to Device CRD in the form of annotation. The corresponding annotation key is node.koordinator.sh/devices-checkpoints, and the annotation value is defined as follows:
type PodDevicesEntry struct {
PodUID string `json:"podUID,omitempty"`
ContainerName string `json:"containerName,omitempty"`
ResourceName string `json:"resourceName,omitempty"`
DeviceIDs []string `json:"deviceIDs,omitempty"`
AllocResp []byte `json:"allocResp,omitempty"`
}
type PodDevicesEntries []PodDevicesEntry
CRD Example
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Device
metadata:
name: node-1
annotations:
node.koordinator.sh/gpu-checkpoints: |-
[
{
"podUID": "fa8983dc-bb76-4eeb-8dcc-556fbd44d7ce",
"containerName": "cuda-container",
"resourceName": "nvidia.com/gpu",
"deviceIDs": ["GPU-36b27e44-b086-46f7-f2dc-73c36dc65991"]
}
]
spec:
devices:
- health: true
id: GPU-98583a5c-c155-9cf6-f955-03c189d3dbfb
minor: 0
resources:
kubernetes.io/gpu-core: "100"
kubernetes.io/gpu-memory: 15472384Ki
kubernetes.io/gpu-memory-ratio: "100"
type: gpu
- health: true
id: GPU-7f6410b9-bdf7-f9a5-de09-aa5ec31a7124
minor: 1
resources:
kubernetes.io/gpu-core: "100"
kubernetes.io/gpu-memory: 15472384Ki
kubernetes.io/gpu-memory-ratio: "100"
type: gpu
status: {}
koordlet and koord-runtime-proxy
Our target is to work compatible with origin k8s kubelet and k8s device plugins, so:
We still allow kubelet and device plugin to allocate concrete device, which means no matter there's a k8s device plugin or not, our design can work well.
In koord-runtime-proxy, we will use Pod's
DeviceAllocationin annotation to replace the step1's result of container's args and envs.
We should modify protocol between koord-runtime-proxy and koordlet to add container env:
type ContainerResourceHookRequest struct {
....
Env map[string]string
}
type ContainerResourceHookResponse struct {
....
Env map[string]string
}
Then we will add a new gpu-hook in koordlet's runtimehooks, registered to PreCreateContainer stage.
We will generate new GPU env NVIDIA_VISIBLE_DEVICES by Pod GPU allocation result in annotation.
The koord-runtime-proxy can see these Pod's env, we need koord-runtime-proxy to pass these environments to koordlet, and koordlet parse the GPU related env to find the concrete device ids.
Besides, the koordlet should report GPU model to node labels same as device plugin, this is in-case Koordinator working without device-plugin.
Finally, we should modify ContainerResourceExecutor's UpdateRequest function in koord-runtime-proxy, and let new GPU env covering old GPU env.
When we handle hot-update processing, we can handle the existing scheduled Pods without device allocation in Pod's annotation. If GPU allocation info is not in annotation, we will find the GPU allocations from ContainerResourceHookRequest's Env, and we will update all GPU allocations to Device CRD instance.
Compatibility
As we know, the GPU scheduling in kube-scheduler side has no any different with other scalar resources. The concrete device-level assigning is done by kubelet and GPU device plugin, which will generate container's GPU env.
Our design has no conflict with the above process. Our device reporter reports Koordinator GPU resources for kubelet updating node resources. Then we schedule device request in our new plugin with new device resource account. In pre-bind stage, we will update container resources with Koordinator GPU resources, this is for kubelet to check resource limitation. We will also add device allocation information to Pod's annotation. In node side, the k8s device plugin will first patch container env, but we will overwrite these envs in runtimeproxy by allocation result in Pod's annotation.
Upgrade strategy
If using Koordinator GPU Scheduling to schedule GPU Pods in a brand new cluster, simply install Koordinator components.
However, if you want to upgrade to Koordinator GPU Scheduing in an existing cluster, you need to avoid GPU devices being repeatedly allocated because of switching between different scheduling mechanisms. You need to pay attention to the order when upgrading:
- Install the Koordinator components. In particular, make sure that the koordlets are all started successfully.
- Stop the system or platform that creates the new GPU Pod.
- Stop the scheduler currently responsible for the GPU Pod and ensure that there are no pending GPU Pods in the current cluster.
- Wait a few minutes to ensure that each node's koordlet creates and updates the Device CRD.
- Modify all components that create GPU Pods to switch the schedulerName of the Pod to koord-scheduler
- Start trying to create a GPU Pod and verify the koord-scheduler GPU Scheduling scheduling result.
- Restore the system or platform that created the GPU Pod and the old scheduler.
In the future Koordinator will provide a webhook to solve the upgrade existing cluster problem. The webhook will identify the GPU Pod and modify the schedulerName of the newly created GPU Pod to koord-scheduler. At the same time, the webhook will take over the Binding operation of the GPU Pod. If the Binding is not initiated by koord-scheduler, it will be rejected.
Unsolved Problems
Alternatives
- User can choose whether use k8s-device plugin. as mentioned above, we can compatible in both cases.