Multi Hierarchy Elastic Quota Management
Summary
When several users or teams share a cluster, fairness of resource allocation is very important. This proposal provides multi-hierarchy elastic quota management mechanism for the scheduler.
- It supports configuring quota groups in a tree structure, which is similar to the organizational structure of most companies.
- It supports the borrowing / returning of resources between different quota groups, for better resource utilization efficiency. The busy quota groups can automatically temporarily borrow the resources from the idle quota groups, which can improve the utilization of the cluster. At the same time, when the idle quota group turn into the busy quota group, it can also automatically take back the "lent-to" resources.
- It considers the resource fairness between different quota groups. When the busy quota groups borrow the resources from the idle quota groups, the resources can be allocated to the busy quota groups under some fair rules.
Motivation
Compared with competitors
Resource Quotas
Resource Quotas provides the ability to restrain the upper limit of resource usage in one quota group. The quota group resource usage aggregated based on the pod resource configurations. Suppose there are still free resources in the cluster, but the resource usage of this quota group is close to the limit. The quota group cannot flexibly borrow the idle resources from the cluster. The only possible way is to manually adjust the limit of the quota group, but it is difficult to determine the timing and value of the adjustment when there are lots of quota groups.
Elastic Quota
Elastic Quota proposed concepts of "max" and "min". "Max" is the upper bound of the resource consumption of the consumers. "Min" is the minimum resources that are guaranteed to ensure the functionality/performance of the consumers. This mechanism allows the workloads from one quota group to "borrow" unused reserved "min" resources from other quota groups. The unused "min" of one quota group can be used by other quota groups, under the condition that there is a mechanism to guarantee the "victim" quota group can consume its "min" resource whenever it needs.
If multiple quota groups need borrow unused reserved "min" resources from other quota groups at the same time, the implementation strategy is FIFO, which means that one quota group may occupy all "borrowed-from "resources, while other quota groups cannot borrow any resources at all from the cluster.
Neither of the above support multi hierarchy quota management.
Goals
Define API to announce multi hierarchy quota configuration.
Provides a scheduler plugin to achieve multi hierarchy quota management ability.
Non-goals/Future work
Users have two ways to manage GPU quotas. One is to only declare the number of GPU cards in the quota group, but do not care about the specific card type assigned. The other is to specify the quotas required by different card types. For example, suppose user A\B both has 10 GPU quota, and cluster has two GPU types A100\V100. quotaA only declare 10 GPU quota, so in the scheduling process, as long as the total number of GPU cards allocated to A is 10, no matter what the allocation ratio of a100\v100 is, it will meet the expectation. QuotaB also declare 10 GPU quota, but has more details with V100 is 5 and A100 is 5, so the maximum allocation of V100 is 5 and A100 is 5 in the scheduling will meet the expectation.
We know that the GPU card type reflected by the label or annotation on the node, not in the resource dimension, so we can't simply configure nvidia.com/gpu-v100, nvidia.com/gpu-a100 directly into the quota group's resource dimension.
What's more complicated is that in a cluster, there will be multiple quota groups like A\B at the same time, These two modes will conflict. Suppose that the cluster resource has 20 cards, including 10 cards for A100 and 10 cards for V100. If the scheduler first assigns 10 cards to quota groupA with all V100, then quota group B's V100 resource has no way to be guaranteed, which obviously does not meet expectations. Therefore, we need to solve the problem that if the above two modes coexist, the quota mechanism can still work normally.
The above problems will be solved in the next proposal.
Proposal
Key Concept\User Stories
Each quota group declares its own "min" and "max". The semantics of "min" is the quota group's guaranteed resources, if quota group's "request" less than or equal to "min", the quota group can obtain equivalent resources to the "request". The semantics of "max" is the quota group's upper limit of resources. We require "min" to be less than or equal to max.
We define "request" as the sum pod's request in the quota group. When some quota groups "request" is less than "min", and some quota groups "request" is more than "min", the unused resources of the former can be lent to (or you can choose not to share) the latter. The latter should use these resources according to the fair rule. When the former needs to use the "lent-to" resources, the latter should also return the "borrowed-from" resources according to the fair rule.
We define the "runtime" as the current actual resource that can be used by the quota group. For a quota group whose "request" is less than min, the value of "runtime" is equal to "request". That is to say "request" should be unconditionally satisfied if the "request" is less than "min". For a quota group whose "request" is greater than "min", the value of "runtime" is between "min" and "max", and the part exceeding "min" is based on its own "request", the "lent-to" resources, and the ability of other quota groups to compete for "lent-to" resources. This will be described in detail below.
Hierarchy is very important in a resource-shared cluster. Suppose that the cluster shared by multiple departments, and each department has multiple teams. If each team is a quota group, we naturally hope that the relationship between departments and teams is tree shaped. In this way, no matter how to add, delete or adjust quota groups within the department, it is an internal matter of the department. The cluster administrator only needs to be responsible for the quota configuration at the level of departments, and the quota group's configuration can delegate power to the department itself. Moreover, tree can help us easily see the summary of resources from the perspective of departments when there are lots of teams in one department.
Another advantage of tree structure is that we can control the scope of the "lent-to" resource. For example, a department only wants to its quota groups can borrow resources from each other, while the resources of the department do not want to be lent to other departments. This is very convenient for the tree structure. It should be pointed out that although two levels can meet most scenarios (the more levels, the higher the maintenance complexity), we will support that the height of the quota-tree is arbitrary.
Implementation Details
Calculate RuntimeQuota
We use an example to introduce how to calculate "runtime". Suppose the cluster total resource is 100, and has 4 quotas, the configuration and "request" of each quota group described as below:
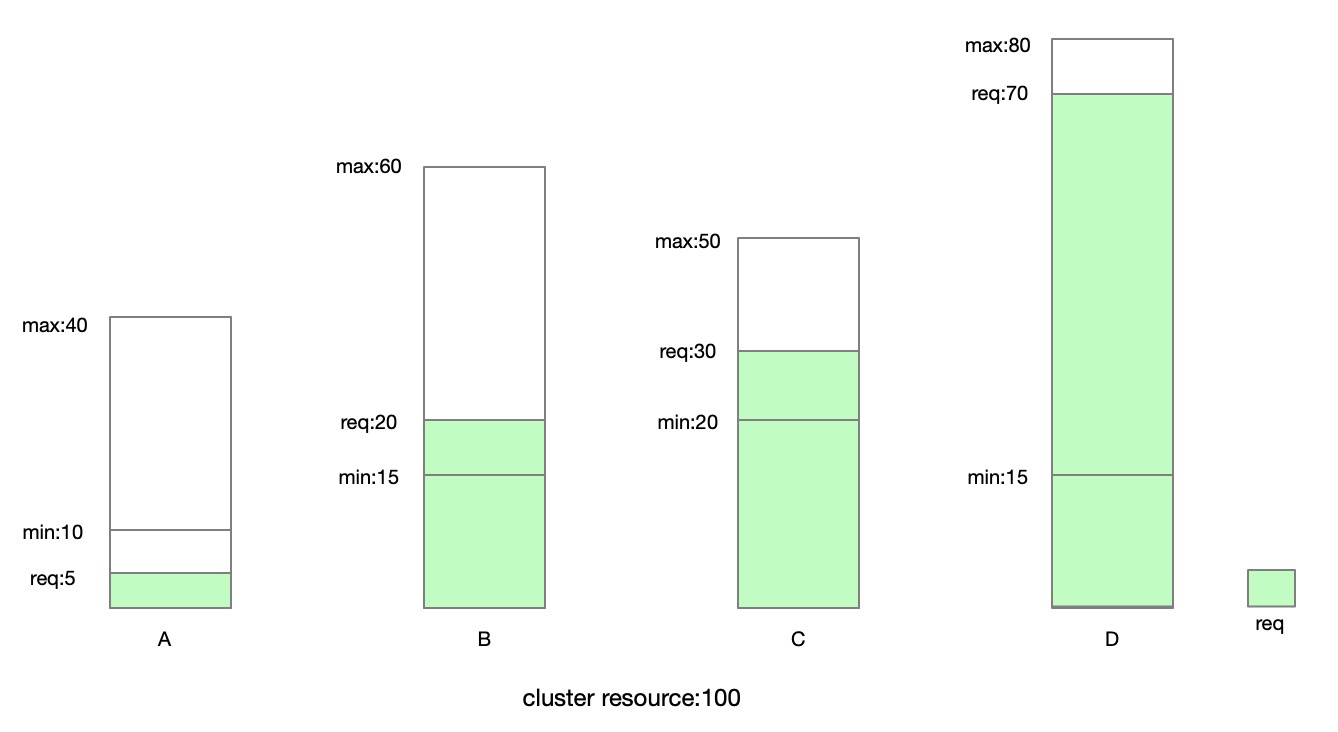
We first calculate the "min" part of "runtime". It should be like as below:
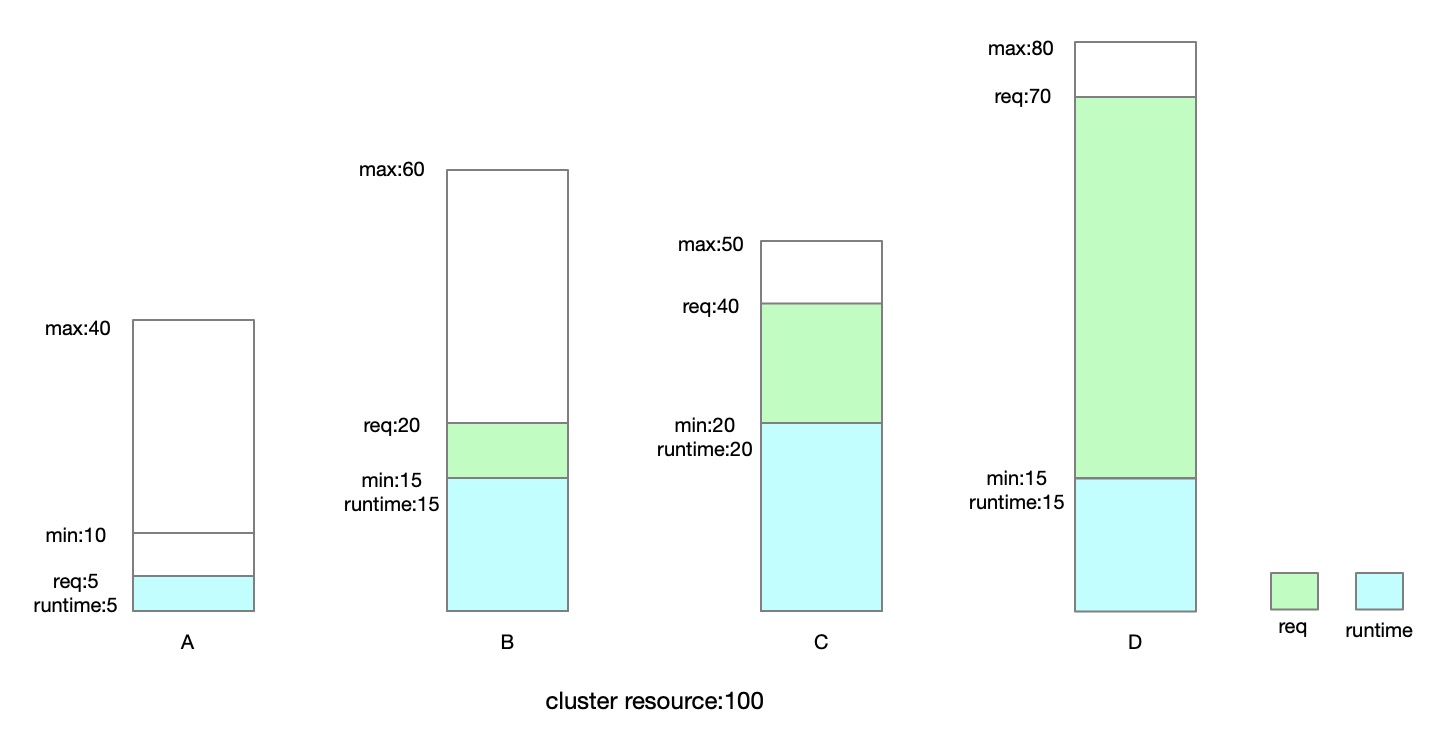
Then we find quota groupA can lent 5 quotas to B\C\D, and the cluster has 40 quotas to allocate, so the sum is 45 for B\C\D to share. We introduce a new field to represent the allocation fairness, which is called "shared-weight". "shared-weight" determines the ability of quota groups to compete for shared resources. That is to say, B/C/D will allocate resources in the cluster according to its "shared-weight".
For example, assuming that the weights of B\C\D are 60\50\80
B can get 45 * 60 / (60 + 50 + 80) = 14
C can get 45 * 50 / (60 + 50 + 80) = 12
D can get 45 * 80 / (60 + 50 + 80) = 19
However, quota group B only need 5 more due to request is 20 and min is 15, and quota group C and D are still hungry, so quota group B can share 14 - 5 = 9 to C and D.
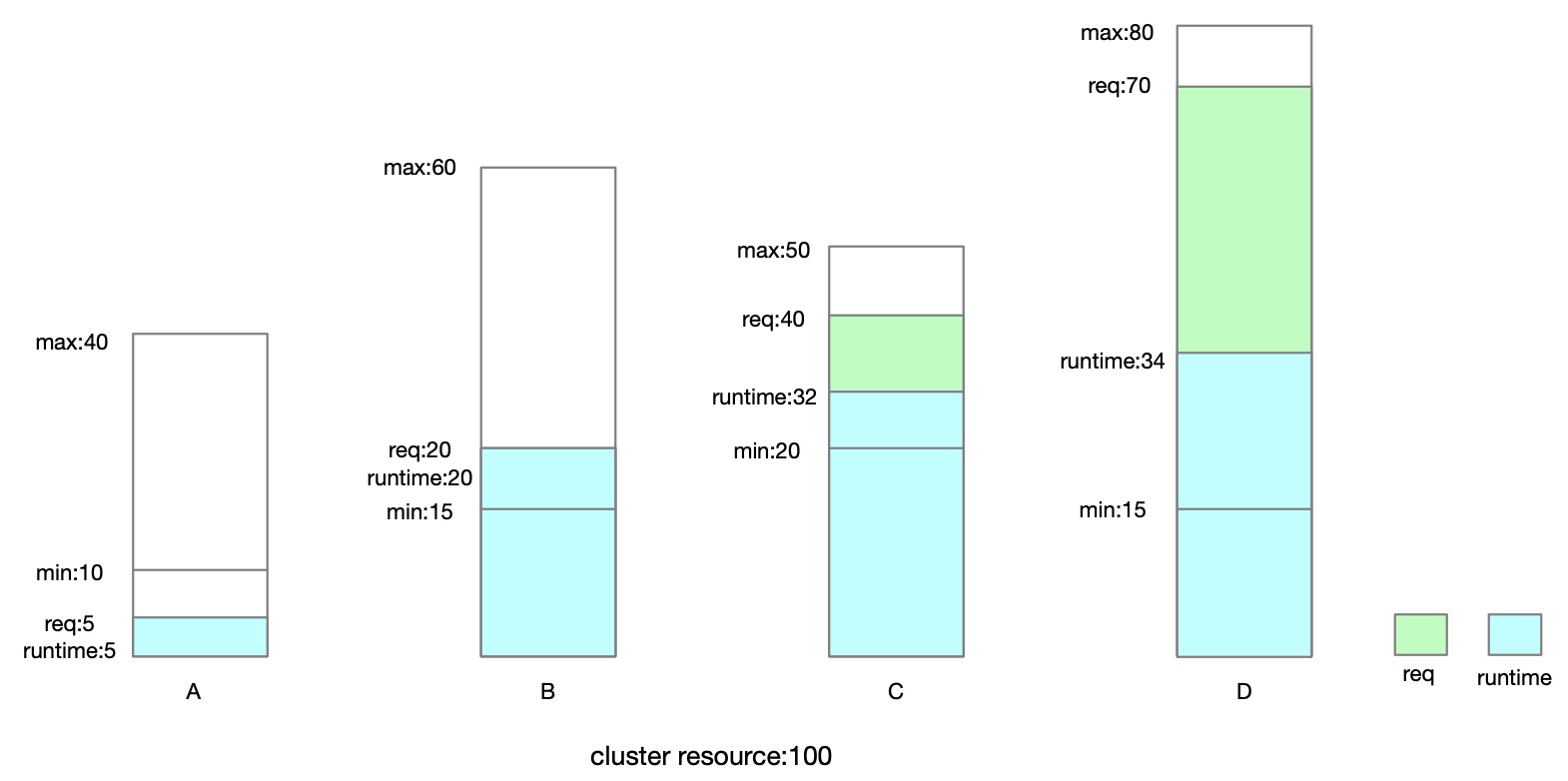
quota group C and D can still share the remained quota of 9 by allocation proportion, which C get 9 50 / (50 + 80) = 3, D get 9 80 / (50 + 80) = 6, and we get the runtime of each quota group finally.
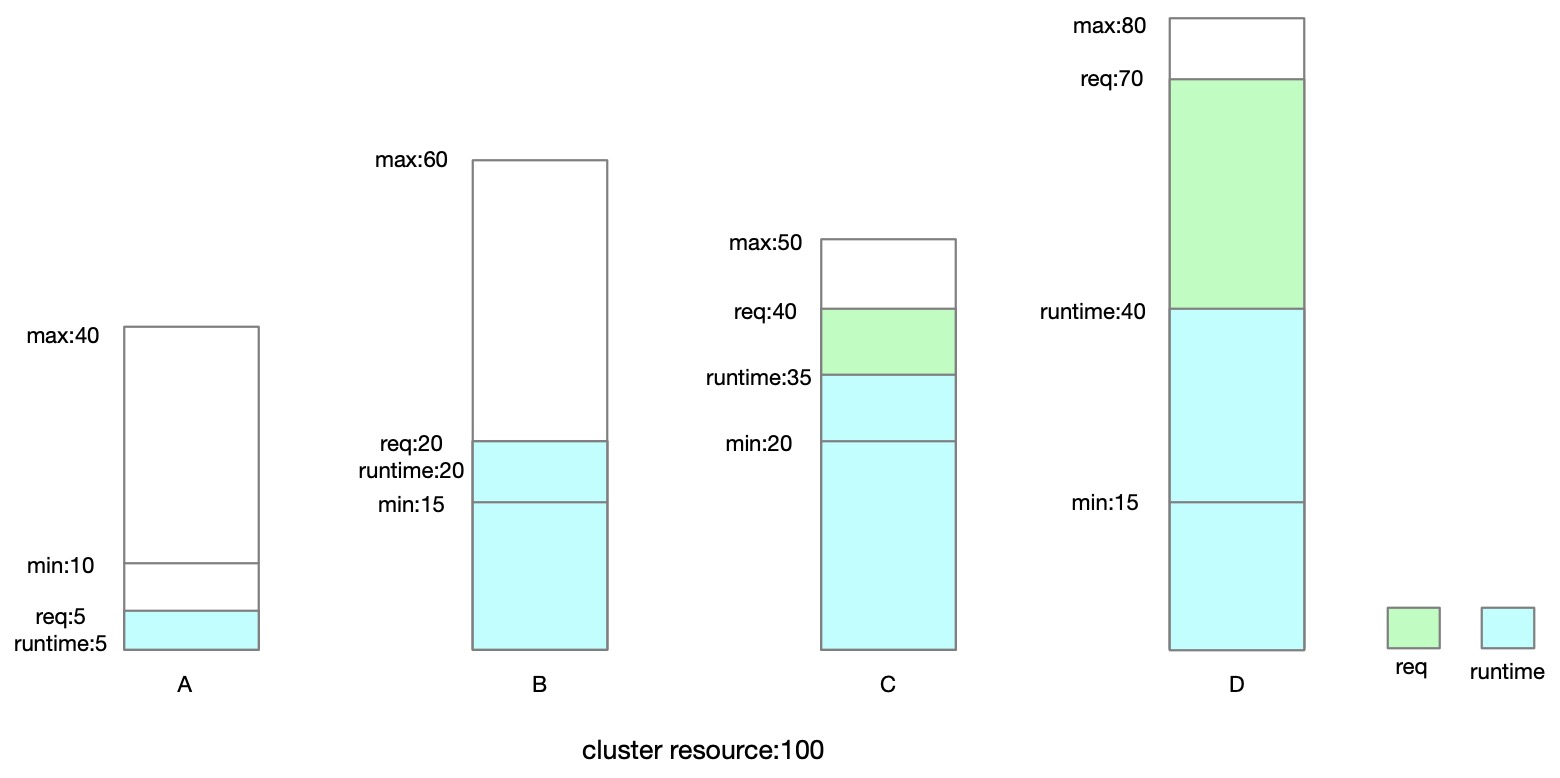
The whole process can be summarized as follows:
The quota divided into two categories, one is whose "request" is less than "min", we call it "lent-to-quotas". The other is whose "request" is greater than "min", we call it "borrowed-quotas".
Calculate the "runtime" of each quota group not exceed "min", so we can get how many resources can be lent to "borrowed-quotas".
The "borrowed-quotas" share the resources by allocation proportion.
If the new "runtime" is larger than "request", there will be new resources which can be lent to the rest "borrowed-quotas".
It is very difficult to manage the weight of thousands of quota groups in a company. Therefore, we need to set a default value for the "shared-weight". According to our experience in online operations, using max as the default "shared-weight" of the quota group can satisfy most scenarios. In this way, "max" has both the meaning of resource ceiling and allocation proportion: the larger the "max" is, the more resources it wants. For individual special scenarios, the resource administrator can adjust the weight.
It must be pointed out that if the cluster resources suddenly decrease due to node failure, the sum of "min" may be greater than the total resources of the cluster. If this case happens, we can't grantee "min" of each quota group actually. So we will reduce the "min" of each quota group in a moderate proportion, which is to ensure that the sum of "min" actually in effect is less than the total resources of the cluster.
We need to introduce the concept of "sys-group". "sys-group" means that the "min" of this quota group is infinite, and its request will never be bound by the quota. It is usually used for system level pods. When the scheduler starts, the "sys-group" will be created by default not only in scheduler memory, but also try create the quota group crd. Its "min" and "max" are INT_MAX. At the same time, its "min" will not be reduced in proportion to the above process. The real available total resource of normal quota groups is the cluster total resource minus the "used" of the "sys-group".
We also need to introduce the concept of "default-group". If the pod cannot find a matching quota group, it will be matched to the "default-group". the "default-group" will be created by default not only in scheduler memory, but also try create the quota group crd. Its "min" and "max" has default value, users can modify them on demand.
Hierarchy
We can organize quota groups using quota-tree, each quota group has its own configuration. Currently, we only allow leaf nodes to submit jobs. An example is as below:
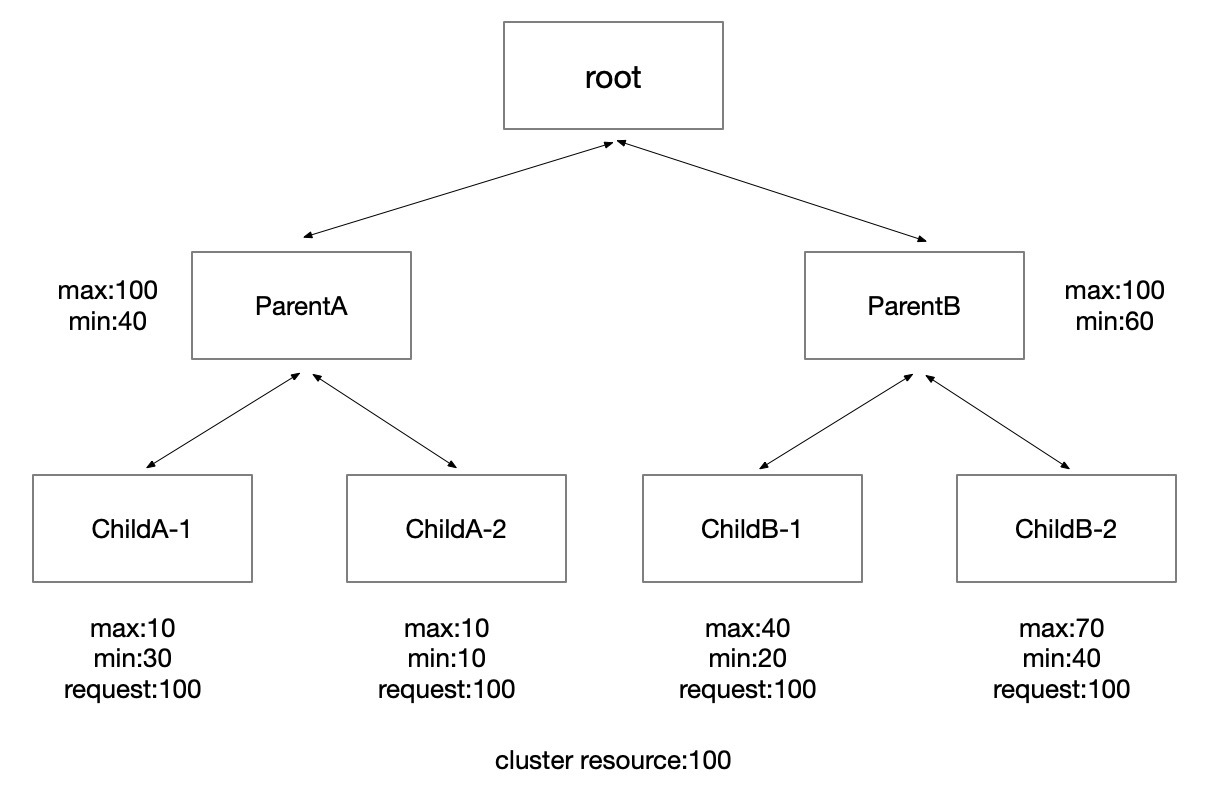
When we calculate the "request" of each quota group. We first count the requests of each parent group from the bottom up, which is the accumulation of mathematical min(child group request, child group max).
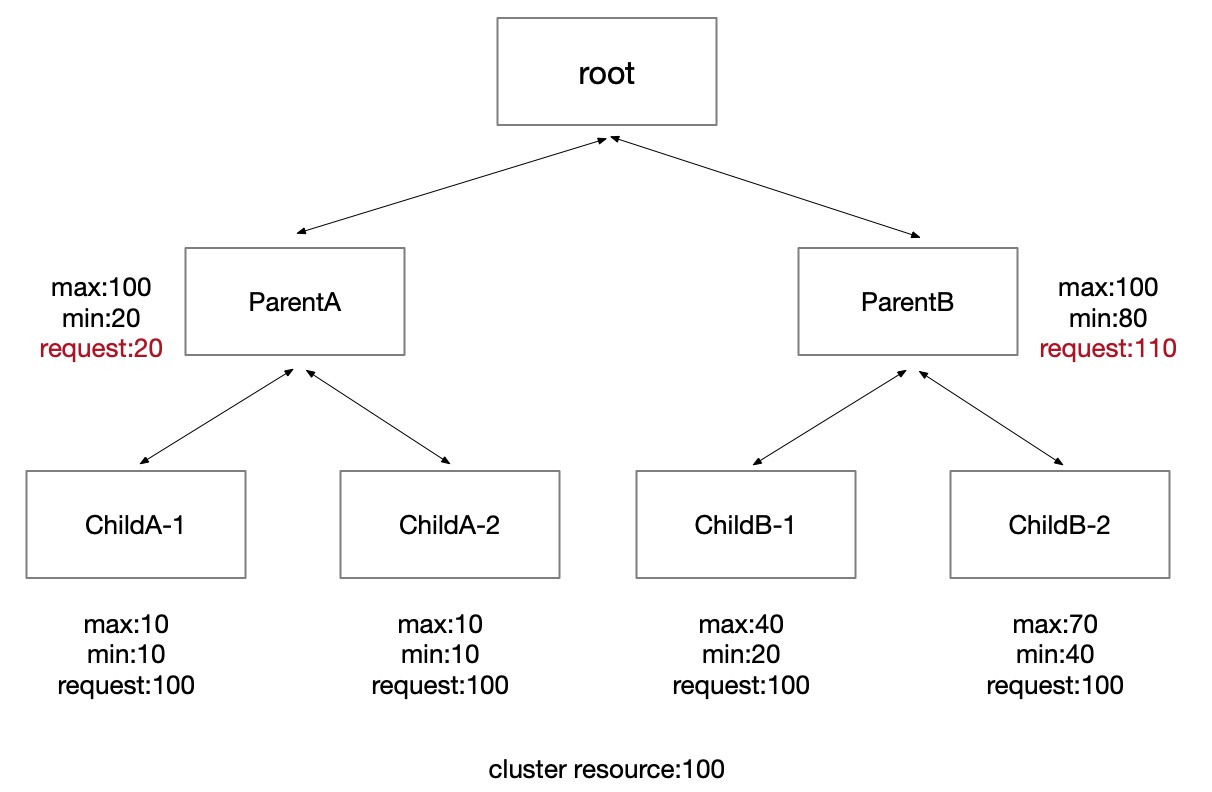
Then we calculate the "runtime" from top to bottom. The "runtime" of the parent quota group is the total resources of the child quota groups. First we calculate parent quota group's "runtime".
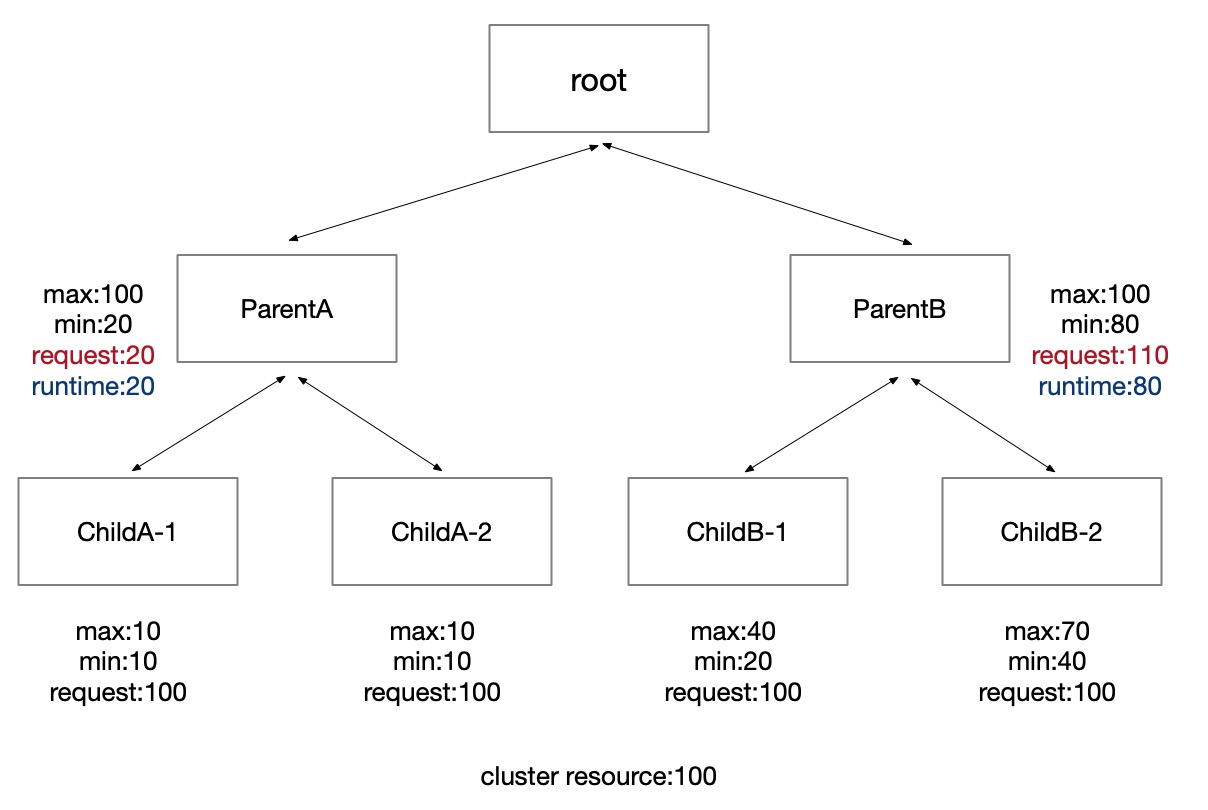
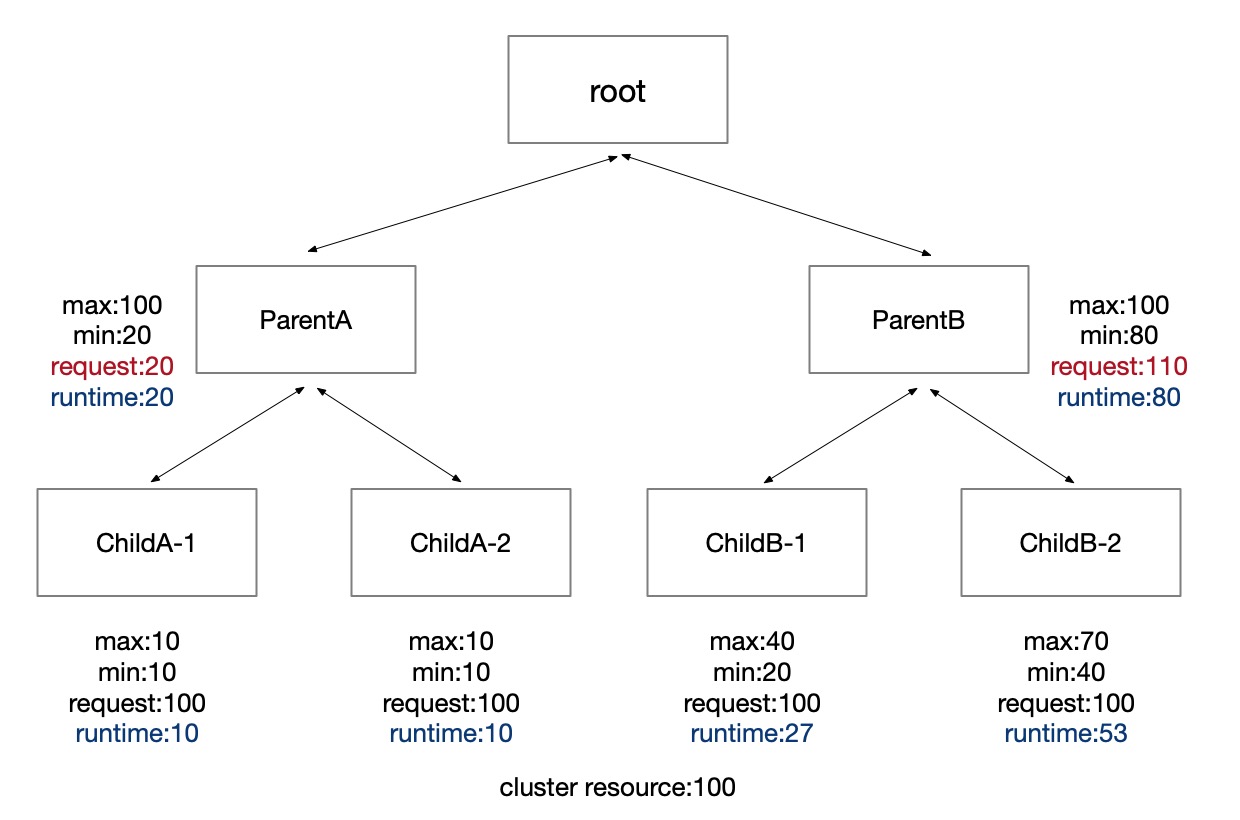
Then we calculate child quota group's "runtime".
Min Guarantee and Preemption
Considering the following situations, suppose that the cluster has two quotas group A\B. At t0 time, only quota groupA has job submission, it can borrow from quota group B's resource, and the "request" and "used" of quota group are both 100 as below:
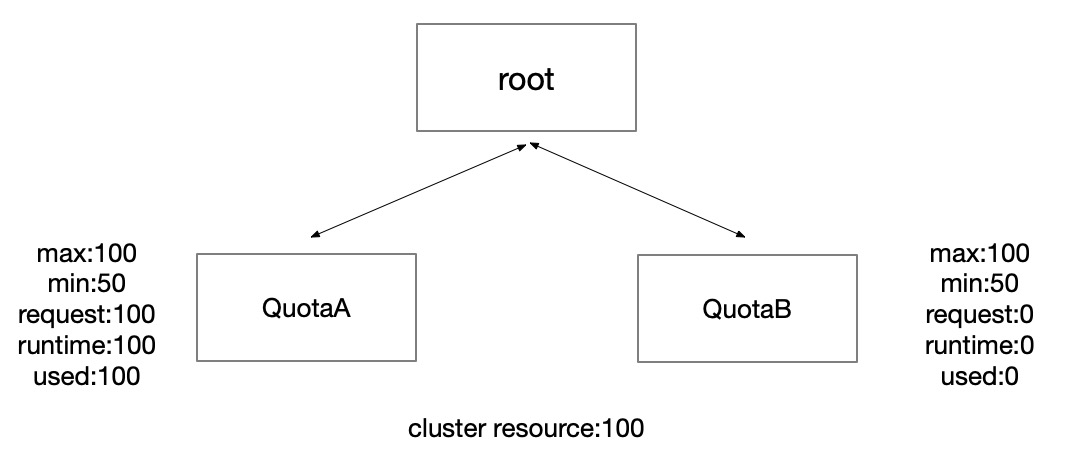
At t1 time, quota groupB has job submission too, so the "runtime" of quota group A\B is both 50. However, if quota groupA don't return resource back, quota groupB can't assign any resource cause node resource occupied by the quota groupA.
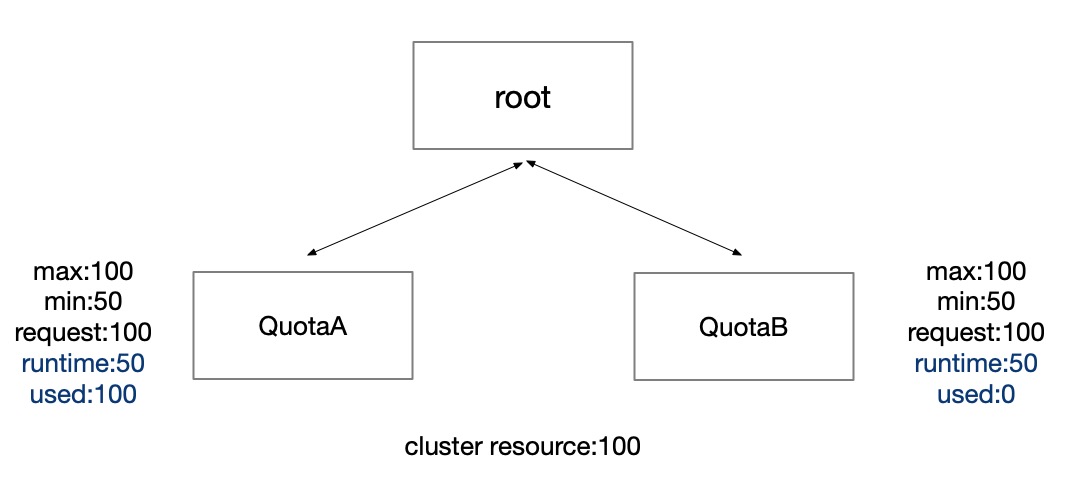
The solution is that we will monitor the relationship between "used" and "runtime" of each quota group in the background thread. If quota group's "used" continues to be greater than "runtime", we will start the forced recycling mechanism to kill several pods in the order of priority from low to high until the "used" is less than or equal to "runtime". If some pods in the quota group do not want to be recycled, we require such pods can only use resource up to "min". By default, we assume all pods can use resource beyond "min" if "runtime" larger than "min".
We do not adopt the cross quota preemption method to solve the problem that when quota group "used" is less than "runtime" (to preempt the quota group whose "used" is greater than the "runtime"). Due to each quota group has an accurate runtime, we can accurately recycle the overused resources of each quota group. This is more direct than preemption.
In addition, we do not think that cross quota preemption is worth recommending. In principle, the priorities of different quota groups are not comparable, because they may come from different business lines. The high priority of this business line is not more important than the low priority of other business lines. Only priorities within a quota group have comparative significance. So we will not support cross quota preemption temporary. Moreover, in inner quota preemption, we will limit existUsed - preempted + preempt smaller than runtime.
It can be seen from the above, if "min" of the quota group is not equal to "max", the "runtime" part exceeding "min" may recycled by the scheduler.
Configuration Limit
We introduce several constraints to ensure that the quota mechanism works properly.
Except for the first level quota group, we require that the sum of "min" of all sub quota groups should be less than or equal to the "min" of parent group. The reason for excluding the first level quota group is that the cluster resources cannot avoid jitter. If the cluster resource reduced, we don't want to hinder the update of the quota groups.
The "max" of child quota group can be larger than the "max" of parent group. Consider the following scenario, there are 2 subtrees in the cluster, "dev-parent" and "production-parent". Each subtree has several "quota-groups". When "production" is busy, we can limit the resource use of the "dev" by only decreasing the "max" of "dev-parent", instead of decreasing the "max" of each sub quota group of "dev-parent".
Parent group cannot run pod. We did receive a request to allow the parent group to submit jobs. The priority of the parent group's self jobs is higher than that of all the sub-groups, which means that the parent group's self jobs can preempt the "runtime" of the sub-group's jobs at any time. This is somewhat similar to the hierarchical relationship of "Town City province". Due to complexity,we do not support this issue for now.
The parent of node can only be parent group, not child group.
A quota group can't be converted on the attribute of parent group\child group.
We allow a node on the quota tree to freely change its parent node, as long as it does not break the existing detection rules.
We will introduce a new "web-hook" to check the configuration limitation.
Extension Point
PreFilter
We will check if the (Pod.request + Quota.Used) is less than Quota.Runtime. If not, the scheduling cycle of Pod will fail.
PostFilter
We will re-implement the method selectVictimsOnNode in defaultPreempt. The original selectVictimsOnNode method selects all the pods with the lower priority than the preemptor’s priority as potential victims in a node. For now, we only allow inner-quota-group preemption.
Cache and Controller
- We will watch the event of quota group and pod to calculate "runtime" of each quota group.
- We will create a thread to update quota group crd to display "request\used\runtime" periodicity.
- We will create a thread to monitor "used" and "runtime" of each quota group. If quota group's "used" continues to be greater than "runtime", we will start the forced recycling mechanism to kill several pods in the order of priority from low to high until the "used" is less than or equal to "runtime".
API
Quota
We will reuse Elastic Quota 's crd to declare quota group.
type ElasticQuota struct {
metav1.TypeMeta
metav1.ObjectMeta
Spec ElasticQuotaSpec
Status ElasticQuotaStatus
}
type ElasticQuotaSpec struct {
Min v1.ResourceList
Max v1.ResourceList
}
type ElasticQuotaStatus struct {
Used v1.ResourceList
}
we will also add new annotation and labels to achieve our desired functionality.
annotations:
quota.scheduling.koordinator.sh/runtime: {cpu:4, memory: 8Gi}
quota.scheduling.koordinator.sh/shared-weight: {cpu:4, memory: 8Gi}
labels:
quota.scheduling.koordinator.sh/is-parent: false
quota.scheduling.koordinator.sh/parent-quota-name: "parent"
quota.scheduling.koordinator.sh/allow-lent-resource: true
quota.scheduling.koordinator.sh/runtimeis updated by the scheduler. It reflects the "runtime" of the quota group.quota.scheduling.koordinator.sh/is-parentis disposed by the user. It reflects the "child\parent" attribute of the quota group. Default is child.quota.scheduling.koordinator.sh/parent-quota-nameis disposed by the user. It reflects the parent quota name. Default is root.quota.scheduling.koordinator.sh/shared-weightis disposed by the user. It reflects the ability to share the "lent to" resource. Default equals to "max".quota.scheduling.koordinator.sh/allow-lent-resourceis disposed by the user. It reflects whether quota group allows lent unused "min" to others.
Here is a example:
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: ElasticQuota
metadata:
name: test
namespace: test
annotations:
quota.scheduling.koordinator.sh/runtime: {cpu:4, memory: 8Gi}
quota.scheduling.koordinator.sh/shared-weight: {cpu:4, memory: 8Gi}
labels:
quota.scheduling.koordinator.sh/is-parent: false
quota.scheduling.koordinator.sh/parent-quota-name: "parent"
quota.scheduling.koordinator.sh/allow-lent-resource: true
spec:
max:
cpu: 20
memory: 40Gi
nvidia.com/gpu: 2
min:
cpu: 10
memory: 20Gi
nvidia.com/gpu: 1
Pod
We introduce a new label on the pod to associate pod with quota group:
labels:
quota.scheduling.koordinator.sh/name: "test1"
if pod's don't have the label, we will follow Elastic Quota using namespace to associate pod with quota group.
Compatibility
We are fully compatible with Elastic Quota 's interface. If pod's don't have the "quota-name" label, we will use the namespace to associate pod with quota group. If the pod has the "quota-name" label, we will use it to associate pod with quota group instead of namespace. If we can't find the matched quota group, we force the pod to associate with the "default-group".
Unsolved Problems
Please see Non-goals/Future work.