Enhanced Scheduler Extension
Summary
This proposal describes how to extend the kubernetes scheduling framework without modify upstream codes to support the scheduling features that Koordinator needs to develop.
Motivation
Although Kubernetes Scheduler provides the scheduling framework to help developer to extend scheduling features. However, it cannot support the features that Koordinator needs to develop, such as Reservation, NUMA Aware Scheduling, problem diagnosis and analysis, etc.
Goals
- Provides scheduling extension point hook mechanism
- Provides a mechanism that allows scheduling plugins to expose their internal state, helping to diagnose and analyze issues.
Non-Goals/Future Work
Proposal
User stories
Story 1
koordinator supports users to use Reservation CRD to reserve resources. We expect Reservation CRD objects to be scheduled like Pods. In this way, the native scheduling capabilities of Kubernetes and other extended scheduling capabilities can be reused. This requires a mechanism to disguise the Reservation CRD object as a Pod, and to extend some scheduling framework extension points to support updating the Reservation Status.
Story 2
Koordinator provides some scheduling plugins, such as Fine-grained CPU Scheduling, Device Share Scheduling, Coscheduling, ElasticQuota, etc. These plugins are brand new, and the supported scenarios are relatively rich, and the internal logic and state of the plugins are also a bit complicated. When we may encounter some problems in the production environment and need to be diagnosed and analyzed, we need to confirm the cause of the problem based on the internal status of the plugin. But currently the kubernetes scheduling framework does not provide a mechanism to export the internal state of the plugin.
Story 3
The scheduler provides many plugins, and most plugins implement Scoring Extension Point. How to configure the weights of these plugins needs to be decided in combination with specific problems. When the optimal node is selected according to the scoring results, the results may not meet expectations. At this point we need to be able to trace or debug these scoring results in some way. But there is currently no good way.
Design Details
Enhancement Kubernetes Scheduling Framework principles
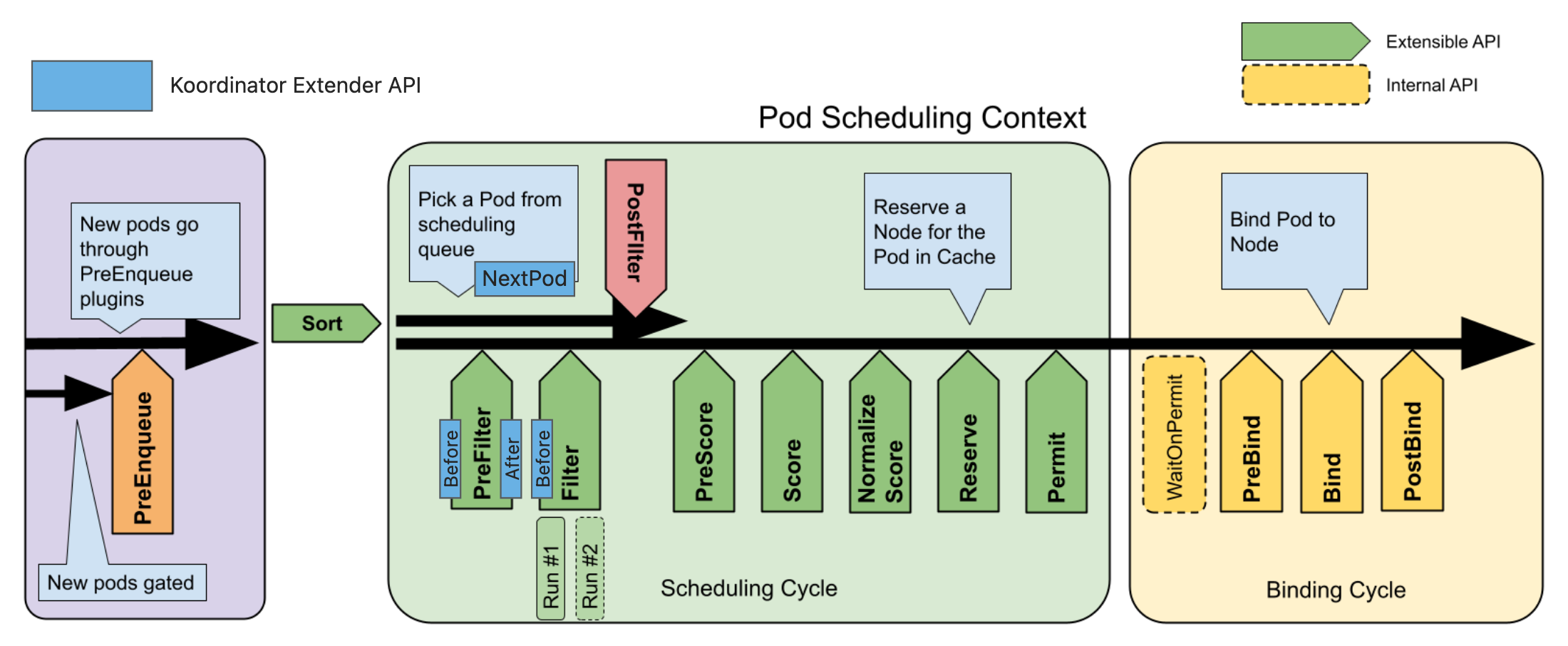
At present, the kube-scheduler provided by Kubernetes can be divided into several parts. The outermost layer is k8s.io/kubernetes/cmd/kube-scheduler, which is the entrance of kube-scheduler; k8s.io/kubernetes/pkg/scheduler is responsible for integrating the framework And execute scheduling workflow, including initializing framework and plugins, scheduling Pod, etc. The core module is k8s.io/kubernetes/pkg/scheduler/framwork, which is the Kubernetes Scheduling Framework.
Each layer provides some interfaces or methods to support developers to extend some capabilities, and the evolution speed of each layer is also different. Generally speaking, the evolution speed of the more core modules should be slower, and the evolution of core modules tends to extend rather than modify the existing interface or extension mechanism, otherwise it will bring very large cost and reliability to external dependencies. question. But each layer does not support implementing some features for some reason. But as far as the problems Koordinator is currently experiencing, there are still some workarounds. However, some principles need to be followed to reduce future conflicts with the evolution of the upstream Kubernetes community.
- Prefer NOT modify the Kubernetes Scheduling Framework. The scheduling framework is the core module of kube-scheduler and is still evolving. In order to avoid conflict with the upstream community between Koordinator's enhanced capabilities.
- DO NOT modify the
k8s.io/kubernetes/pkg/schedulerbut can implements supported interfaces or high-order functions, such asSchedulePod,NextPod,ErrorandProfiles. TheProfilescontains an instance of the Framework interface corresponding to each KubeSchedulerProfile. We can implement the Framework and replace the instances in Profiles to get the opportunity to participate in the scheduling process to do something. - Extend
k8s.io/kubernetes/cmd/kube-scheduleras simply as possible.
Custom Extension Overview
ExtendedHandle
ExtendedHandle extends the k8s scheduling framework Handle interface to facilitate plugins to access Koordinator's resources and states.
Before constructs the k8s.io/kubernetes/pkg/scheduler.Scheduler object, we should build an ExtendedHandle object and pass the object to each custom plugins.
type ExtendedHandle interface {
framework.Handle
KoordinatorClientSet() koordinatorclientset.Interface
KoordinatorSharedInformerFactory() koordinatorinformers.SharedInformerFactory
SnapshotSharedLister() framework.SharedLister
}
Intercept plugin initialization process
In order to pass the ExtendedHandle object to each custom plugins, we should intercept the plugin initialization process.
And we expect that any customized plugins can be directly and seamlessly integrated into the koordinator scheduler, so the PluginFactory of the plugin will not be changed. Therefore, we can modify the prototype of k8s.io/kubernetes/cmd/kube-scheduler/app.Option and the implementation of k8s.io/kubernetes/cmd/kube-scheduler/app.WithPlugin as the follows to get the opportunity to intercept the plugin initialization process.
When the custom plugin is registered to the out-of registry using WithPlugin, it will use frameworkext.PluginFactoryProxy to wrap the plugin's original PluginFactory. We finally complete the interception of the plugin initialization process in frameworkext.PluginFactoryProxy.
Of course, we will not modify k8s.io/kubernetes/cmd/kube-scheduler directly. Considering that the logic of k8s.io/kubernetes/cmd/kube-scheduler itself is not complicated, it will basically not bring us additional maintenance costs, so we will copy the relevant code to Koordinator for separate maintenance.
// Option configures a framework.Registry.
type Option func(frameworkext.ExtendedHandle, runtime.Registry) error
// WithPlugin creates an Option based on plugin name and factory. Please don't remove this function: it is used to register out-of-tree plugins,
// hence there are no references to it from the kubernetes scheduler code base.
func WithPlugin(name string, factory runtime.PluginFactory) Option {
return func(handle frameworkext.ExtendedHandle, registry runtime.Registry) error {
return registry.Register(name, frameworkext.PluginFactoryProxy(handle, factory))
}
}
// frameworkext.PluginFactoryProxy
func PluginFactoryProxy(extendHandle ExtendedHandle, factoryFn frameworkruntime.PluginFactory) frameworkruntime.PluginFactory {
return func(args runtime.Object, handle framework.Handle) (framework.Plugin, error) {
impl := extendHandle.(*frameworkExtendedHandleImpl)
impl.once.Do(func() {
impl.Handle = handle
})
return factoryFn(args, extendHandle)
}
}
Expose the internal state of plugins
We will define a new extension interface to help the plugin expose the internal state through the Restful API, and provide some built-in Restful APIs to query which APIs are exposed by the current scheduler and some commonly used internal data, such as NodeInfo, etc.
The new extension interface named APIServiceProvider. The plugins can implement this interface to register the API to be exposed as needed. When the plugin is initialized, frameworkext.PluginFactoryProxy will check whether the newly constructed plugin implements APIServiceProvider, and if so, it will call the RegisterEndpoints method of the interface to register the API. The Restful APIs exposed by these plugins will be bound to the URL path /apis/v1/plugins/ and will be prefixed with the name of each plugin. For example, the API /availableCPUs/:nodeName exposed by the plugin NodeNUMAResource will be converted to /apis/v1/plugins/NodeNUMAResource/availableCPUs/:nodeName.
type APIServiceProvider interface {
RegisterEndpoints(group *gin.RouterGroup)
}
type ErrorMessage struct {
Message string `json:"message,omitempty"`
}
func ResponseErrorMessage(c *gin.Context, statusCode int, format string, args ...interface{}) {
var e ErrorMessage
e.Message = fmt.Sprintf(format, args...)
c.JSON(statusCode, e)
}
Users can use the built-in API /apis/v1/__services__ to query how many Restful APIs are provided by the current scheduler. The response as the follows:
{
"GET": [
"/apis/v1/__services__",
"/apis/v1/nodes/:nodeName",
"/apis/v1/plugins/Coscheduling/gang/:namespace/:name",
"/apis/v1/plugins/Coscheduling/gangs",
"/apis/v1/plugins/NodeNUMAResource/availableCPUs/:nodeName",
"/apis/v1/plugins/NodeNUMAResource/cpuTopologyOptions/:nodeName"
]
}
Koordinator scheduler also provides /apis/v1/nodes/:nodeNa to expose internal NodeInfo to developers.
Support plugin to create Controllers
Similar to Coscheduling/ElasticQuota Scheduling, these scheduling plugins have a matching Controller to synchronize the status of the related CRD. The most common way is to deploy these controllers independently of the scheduler. This method will not only bring additional maintenance costs and resource costs, but also if there are more states in the scheduling plugin that need to be synchronized to the CRD Status, the logic in the Controller and the logic in the plugin need to be more closely coordinated. The best way is that the Controller and the scheduling plugin are in the same process.
We can define a new interface called ControllerProvider. When the plugin is initialized, frameworkext.PluginFactoryProxy will check whether the newly constructed plugin implements ControllerProvider, and if so, it will call the NewControllers method of the interface to get the instances of Controllers, and save these instances in the ExtendedHandle. When the scheduler gets the leader role, it can trigger the ExtendedHandle to start these controllers.
type ControllerProvider interface {
NewControllers() ([]Controller, error)
}
type Controller interface {
Start()
Name() string
}
Debug Scoring Result
If we want to support debug scoring results, the easiest way is to directly modify Framework.RunScorePlugins and print the results after scoring. But this goes against the extend principles we laid out earlier. But we can think differently. When scheduler.Scheduler executes scheduleOne, it obtains an instance of the framework.Framework interface from Profiles and calls the method RunScorePlugins. At the same time, considering that we have maintained the initialization code of scheduler separately, then we can customize the implementation of the framework.Framework interface, implement the method RunScorePlugins and take over the Profiles in scheduler.Scheduler. In this way, we can first call the RunScorePlugins method of the original framework.Framework interface instance in the custom implemented RunScorePlugins, and then print the result.
For the processing of the results, we can simply print it to the log in markdown format. When needed, enable Scoring Result debugging capability through the HTTP interface /debug/flags/s like /debug/flags/v. The developers also enable the capability via flags --debug-scores.
# print top 100 score results.
$ curl -X POST schedulerIP:10251/debug/flags/s --data '100'
successfully set debugTopNScores to 100
The following are the specific scoring results:
| # | Pod | Node | Score | ImageLocality | InterPodAffinity | LoadAwareScheduling | NodeAffinity | NodeNUMAResource | NodeResourcesBalancedAllocation | NodeResourcesFit | PodTopologySpread | Reservation | TaintToleration |
| --- | --- | --- | ---:| ---:| ---:| ---:| ---:| ---:| ---:| ---:| ---:| ---:| ---:|
| 0 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.51 | 577 | 0 | 0 | 87 | 0 | 0 | 96 | 94 | 200 | 0 | 100 |
| 1 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.50 | 574 | 0 | 0 | 85 | 0 | 0 | 96 | 93 | 200 | 0 | 100 |
| 2 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.19 | 541 | 0 | 0 | 55 | 0 | 0 | 95 | 91 | 200 | 0 | 100 |
| 3 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.18 | 487 | 0 | 0 | 15 | 0 | 0 | 90 | 82 | 200 | 0 | 100 |
| # | Pod | Node | Score | ImageLocality | InterPodAffinity | LoadAwareScheduling | NodeAffinity | NodeNUMAResource | NodeResourcesBalancedAllocation | NodeResourcesFit | PodTopologySpread | Reservation | TaintToleration |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.51 | 577 | 0 | 0 | 87 | 0 | 0 | 96 | 94 | 200 | 0 | 100 |
| 1 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.50 | 574 | 0 | 0 | 85 | 0 | 0 | 96 | 93 | 200 | 0 | 100 |
| 2 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.19 | 541 | 0 | 0 | 55 | 0 | 0 | 95 | 91 | 200 | 0 | 100 |
| 3 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.18 | 487 | 0 | 0 | 15 | 0 | 0 | 90 | 82 | 200 | 0 | 100 |
Custom Hook Extend Points to Support Reservation Scheduling
If we want to schedule the Reservation CRD object in the form of Pod, we need to solve several problems:
- Before calling
PreFilter, check whether the Pod has a matching Reservation. If there is a matching Reservation, and if the Pod is set withPod Affinity/AntiAffinityorTopologySpreadConstraints, we need to modify the Pod to remove these fields. The reason is that when the Reservation CRD object is created, the user generally sets these fields, and expects to find suitable nodes to reserve resources according to these scheduling constraints. Therefore, if the Pod is scheduled with the same fields, it will cause the scheduling to fail. To do this, it cannot be achieved by implementing thePreFilterextension point, because the scheduler has already obtained the appropriate Pod to start executing when callingPreFilter, and we have lost the opportunity to modify the Pod to affect other plugins. - In the
Filterphase, we also need to update the NodeInfo. If there is a Reservation CRD object on NodeInfo, and the current Pod matches the Reservation CRD object, then the resources applied for by the Reservation CRD object should be returned to NodeInfo. Only in this way can it pass the resource check of the scheduler, including the network port check.
To solve these problems, we define the Hook interface. The plugin can be implemented on demand, and the Pod or NodeInfo can be modified when the PreFilter/Filter is executed. Similar to the custom implementation method RunScorePlugins mentioned above, we can customize the implementation methods RunPreFilterPlugins and RunFilterPluginsWithNominatedPods. Before executing the real extension point logic, first execute the Hook interface and modify the Pod and NodeInfo.
If necessary, you can modify the Pod or Node before executing the Score Extension Point by implementing ScorePhaseHook.
Considering that there may be multiple different Hooks to modify the Pod or NodeInfo requirements, when the Hook is called, the Hook will be called cyclically, and the modification result of the previous Hook and the input of the next Hook will continue to be executed.
Here are some additional explanations for the scenarios in which these new extension points should be used. If you can complete the scheduling function through the extension points such as Filter/Score provided by the K8s Scheduling Framework without modifying the incoming NodeInfo/Pod and other objects, you do not need to use these new extension points.
type SchedulingPhaseHook interface {
Name() string
}
type PreFilterPhaseHook interface {
SchedulingPhaseHook
PreFilterHook(handle ExtendedHandle, state *framework.CycleState, pod *corev1.Pod) (*corev1.Pod, bool)
}
type FilterPhaseHook interface {
SchedulingPhaseHook
FilterHook(handle ExtendedHandle, cycleState *framework.CycleState, pod *corev1.Pod, nodeInfo *framework.NodeInfo) (*corev1.Pod, *framework.NodeInfo, bool)
}
type ScorePhaseHook interface {
SchedulingPhaseHook
ScoreHook(handle ExtendedHandle, cycleState *framework.CycleState, pod *corev1.Pod, nodes []*corev1.Node) (*corev1.Pod, []*corev1.Node, bool)
}
Alternatives
Use Filter instead of Filter Hook
We can change the order of Filter plugins to support Reservation Scheduling to update NodeInfo earlier, which can replace Filter Hook. Subsequent implementations can be implemented as an optimization.