
背景
Koordinator 是一个开源项目,旨在基于阿里巴巴在容器调度领域的多年经验,提供一个完整的混部解决方案,包含混部工作负载编排、资源调度、资源隔离及性能调优等多方面能力,来帮助用户优化容器性能,充分发掘空闲物理资源,提升资源效率,增强延迟敏感型工作负载和批处理作业的运行效率和可靠性。
在此,我们很高兴地向各位宣布 Koordinator v1.3.0 版本的发布。自 2022 年 4 月发布 v0.1.0 版本以来,Koordinator 迄今迭代发布了共 11 个版本,吸引了了包括阿里巴巴、Intel、小米、小红书、爱奇艺、360、有赞等企业在内的大量优秀工程师参与贡献。在 v1.3.0 版本中,Koordinator 带来了 NRI (Node Resource Interface) 支持、Mid 资源超卖等新特性,并在资源预留、负载感知调度、DeviceShare 调度、负载感知重调度、调度器框架、单机指标采集和资源超卖框架等特性上进行了稳定性修复、性能优化与功能增强。
在 v1.3.0 版本中,共有 12 位新加入的开发者参与到了 Koordinator 社区的建设,他们是 @bowen-intel,@BUPT-wxq,@Gala-R,@haoyann,@kangclzjc,@Solomonwisdom,@stulzq,@TheBeatles1994,@Tiana2018,@VinceCui,@wenchezhao,@zhouzijiang,感谢期间各位社区同学的积极参与和贡献,也感谢所有同学在社区的持续投入。
版本功能特性解读
资源预留增强
资源预留(Reservation)能力自 v0.5.0 版本提出后,经历了一年的打磨和迭代,在 v1.3.0 版本中针对抢占、设备预留、Coscheduling 等场景增强了预留机制,新增 allocatePolicy 字段用于定义不同的预留资源分配策略。最新的资源预留 API 如下:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Reservation
metadata:
name: reservation-demo
spec:
# template字段填写reservation对象的资源需求和affinity信息,就像调度pod一样.
template:
namespace: default
spec:
containers:
- args:
- '-c'
- '1'
command:
- stress
image: polinux/stress
imagePullPolicy: Always
name: stress
resources:
requests:
cpu: 500m
memory: 1Gi
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- cn-hangzhou-i
schedulerName: koord-scheduler # 指定koord-scheduler来负责reservation对象的调度.
# 指定可分配预留资源的owners.
owners:
- labelSelector:
matchLabels:
app: app-demo
ttl: 1h
# 指定预留资源是否仅支持一次性的分配.
allocateOnce: true
# 指定预留资源的分配策略,当前支持以下策略:
# - Default: 缺省配置,不限制对预留资源的分配,pod优先分配自节点上的预留资源;如果预留资源不足,则继续分配节点空闲资源。
# - Aligned: pod优先分配自节点上的预留资源;如果预留资源不足,则继续分配节点空闲资源,但要求这部分资源满足Pod需求。该策略可用于规避pod同时分配多个reservation的资源。
# - Restricted: 对于预留资源包含的各个资源维度,pod必须分配自预留资源;其余资源维度可以分配节点空闲资源。包含了Aligned策略的语义。
# 同一节点尚不支持Default策略和Aligned策略或Restricted策略共存。
allocatePolicy: "Aligned"
# 控制预留资源是否可以使用
unschedulable: false
此外,资源预留在 v1.3.0 中还包含了如下兼容性和性能优化:
- 增强 Reservation 的抢占,允许 Reservation 内的 Pod 间抢占,拒绝 Reservation 外的 Pod 抢占 Reservation 内的 Pod。
- 增强设备预留场景,如果节点上设备资源被部分预留并被 pod 使用,支持剩余资源的分配。
- 支持 Reservation 使用 Coscheduling。
- 新增 Reservation Affinity协议,允许用户一定从Reservation内分配资源。
- 优化 Reservation 兼容性,修复因 Reservation 导致原生打分插件失效的问题。
- 优化因引入 Reservation 导致的调度性能回归问题。
- 修复 Reservation 预留端口误删除的问题。
关于资源预留的设计,详见Designs - Resource Reservation。
其他调度增强
在 v1.3.0 中,koordinator 在调度和重调度方面还包含如下增强:
DeviceShare 调度
- 更改 GPU 资源使用方式,使用 GPU Share API 时,必须声明
koordinator.sh/gpu-memory或koordinator.sh/gpu-memory-ratio,允许不声明koordinator.sh/gpu-core。 - 支持打分,可用于实现 GPU Share 场景和整卡分配场景的 bin-packing 或 spread,并支持卡粒度 binpacking 或 spread。
- 修复用户误删除 Device CRD 导致调度器内部状态异常重复分配设备的问题。
- 更改 GPU 资源使用方式,使用 GPU Share API 时,必须声明
负载感知调度:修复对仅填写 Request 的 Pod 的调度逻辑。
调度器框架:优化 PreBind 阶段的 Patch 操作,将多个插件的 Patch 操作合并为一次提交,提升操作效率,降低 APIServer 压力。
重调度
- LowNodeLoad 支持按节点池设置不同的负载水位和参数等。自动兼容原有配置。
- 跳过 schedulerName 不是 koord-scheduler 的Pod,支持配置不同的 schedulerName。
NRI 资源管理模式
Koordinator 的 runtime hooks 支持两种模式,standalone 和 CRI proxy,然而这两种模式各自有着一些限制。当前,尽管在 standalone 模式做了很多优化,但当想获得更加及时的 Pod 或容器的事件或者环境变量的注入时还是需要依赖 proxy 模式。然而, proxy 模式要求单独部署 koord-runtime-proxy 组件来代理 CRI (Container Runtime Interface) 请求, 同时需要更改 Kubelet 的启动参数并重启 Kubelet。
NRI(Node Resource Interface),即节点资源接口,是 CRI 兼容的容器运行时插件扩展的通用框架,独立于具体的容器运行时(e.g. containerd, cri-o), 提供不同生命周期事件的接口,允许用户在不修改容器运行时源代码的情况下添加自定义逻辑。特别的是,2.0 版本 NRI 只需要运行一个插件实例用于处理所有 NRI 事件和请求,容器运行时通过 Unix-Domain Socket 与插件通信,使用基于 Protobuf 的协议数据,和 1.0 版本 NRI 相比拥有更高的性能,能够实现有状态的 NRI 插件。
通过 NRI 的引入,既能及时的订阅 Pod 或者容器的生命周期事件,又避免了对 Kubelet 的侵入修改。在 Koordinator v1.3.0 中,我们引入 NRI 这种社区推荐的方式来管理 runtime hooks 来解决之前版本遇到的问题,大大提升了 Koordinator 部署的灵活性和处理的时效性,提供了一种优雅的云原生系统的资源管理标准化模式。
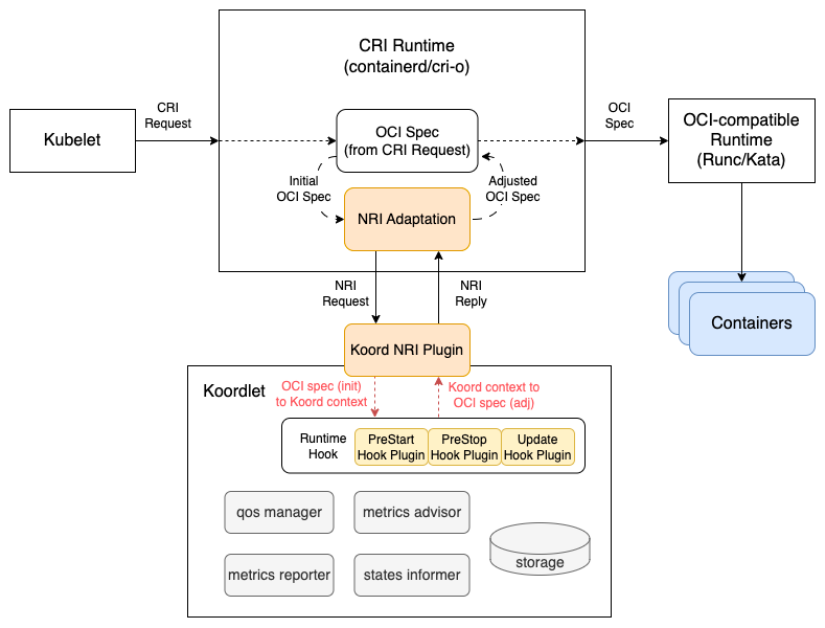
注:NRI 模式不支持 docker 的容器运行时,使用 docker 的用户请继续使用 standalone 模式或 proxy 模式。
关于 Koordinator 启用 NRI 的部署方式,请见Installation - Enable NRI Mode Resource Management。
节点画像和 Mid 资源超卖
Koordinator 中将节点资源分为4种资源优先级模型 Prod、Mid、Batch 和 Free,低优先级资源可以复用高优先级已分配但未使用的物理资源,以提升物理资源利用率;同时,资源优先级越高,提供的资源也越稳定,例如 Batch 资源采用高优先级资源短期(short-term)已分配但未使用的超卖资源,而 Mid 资源采用高优先级资源长周期(long-term)已分配但未使用的超卖资源。不同资源优先级模型如下图所示:
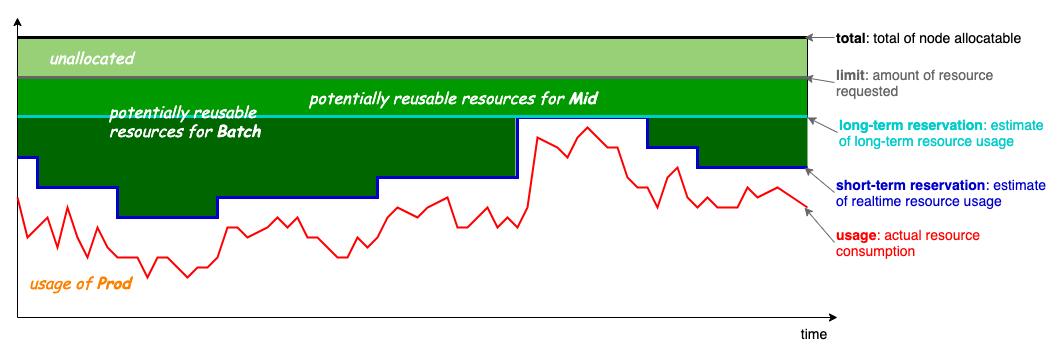
Koordinator v1.3.0 新增了节点画像能力,基于 Prod 的历史资源用量进行峰值预测,以支持 Mid-tier 的资源超卖调度。Mid 资源的超卖计算公式如下:
MidAllocatable := min(ProdReclaimable, NodeAllocatable * thresholdRatio)
ProdReclaimable := max(0, ProdAllocated - ProdPeak * (1 + safeMargin))
ProdPeak:通过节点画像,预估的节点上已调度 Prod Pod 在中长周期内(e.g. 12h)的用量峰值。ProdReclaimable:基于节点画像结果,预估在中长周期内可复用的 Prod 资源。MidAllocatable:节点上可分配的 Mid 资源。
此外,Mid 资源的单机隔离保障将在下个版本得到完善,相关动态敬请关注Issue #1442。 在 v1.3.0 版本中,用户可以查看和提交 Mid-tier 的超卖资源,也可以通过以下 Prometheus metrics 来观测节点画像的趋势变化。
# 查看节点的CPU资源画像,reclaimable指标表示预测的可回收资源量,predictor对应不同的预测模型
koordlet_node_predicted_resource_reclaimable{node="test-node", predictor="minPredictor", resource="cpu", unit="core"}
# 查看节点的内存资源画像,reclaimable指标表示预测的可回收资源量,predictor对应不同的预测模型
koordlet_node_predicted_resource_reclaimable{node="test-node", predictor="minPredictor", resource="memory", unit="byte"}
$ kubectl get node test-node -o yaml
apiVersion: v1
kind: Node
metadata:
name: test-node
status:
# ...
allocatable:
cpu: '32'
memory: 129636240Ki
pods: '110'
kubernetes.io/mid-cpu: '16000' # allocatable cpu milli-cores for Mid-tier pods
kubernetes.io/mid-memory: 64818120Ki # allocatable memory bytes for Mid-tier pods
capacity:
cpu: '32'
memory: 129636240Ki
pods: '110'
kubernetes.io/mid-cpu: '16000'
kubernetes.io/mid-memory: 64818120Ki
关于 Koordinator 节点画像的设计,详见Design - Node Prediction。
其他功能
通过 v1.3.0 Release 页面,可以看到更多包含在 v1.3.0 版本的新增功能。
未来计划
在接下来的版本中,Koordinator 目前规划了以下功能:
- 硬件拓扑感知调度,综合考虑节点 CPU、内存、GPU 等多个资源维度的拓扑关系,在集群范围内进行调度优化。
- 提供节点可分配资源的放大机制。
- NRI 资源管理模式的完善和增强。
更多信息,敬请关注 Milestone v1.4.0。
结语
最后,Koordinator 是一个开放的社区,欢迎广大云原生爱好者们随时通过各种方式参与共建,无论您在云原生领域是初学乍到还是驾轻就熟,我们都非常期待听到您的声音!