
Koordinator[1] 继上次 v0.6版本[2] 发布后,经过 Koordinator 社区的努力,我们迎来了具有重大意义的 v0.7 版本。在这个版本中着重解决机器学习、大数据场景需要的任务调度能力,例如 CoScheduling、ElasticQuota和精细化的 GPU 共享调度能力。并在调度问题诊断分析方面得到了增强,重调度器也极大的提升了安全性,降低了重调度的风险。
版本功能特性解读
1. 任务调度
1.1 Enhanced Coscheduling
Gang scheduling是在并发系统中将多个相关联的进程调度到不同处理器上同时运行的策略,其最主要的原则是保证所有相关联的进程能够同时启动,防止部分进程的异常,导致整个关联进程组的阻塞。例如当提交一个Job时会产生多个任务,这些任务期望要么全部调度成功,要么全部失败。这种需求称为 All-or-Nothing,对应的实现被称作 Gang Scheduling(or Coscheduling) 。
Koordinator 在启动之初,期望支持 Kubernetes 多种工作负载的混部调度,提高工作负载的运行时效率和可靠性,其中就包括了机器学习和大数据领域中广泛存在的具备 All-or-Nothing 需求的作业负载。 为了解决 All-or-Nothing 调度需求,Koordinator v0.7.0 基于社区已有的 Coscheduling 实现了 Enhanced Coscheduling。
Enhanced Coscheduling 秉承着 Koordiantor 兼容社区的原则,完全兼容社区 Coscheduling 和 依赖的 PodGroup CRD。已经使用 PodGroup 的用户可以无缝升级到 Koordinator。
除此之外,Enhanced Coscheduling 还实现了如下增强能力:
支持 Strict 和 NonStrict 两种模式
两种模式的区别在于 Strict模式(即默认模式)下调度失败会 Reject 所有分配到资源并处于 Wait 状态的 Pod,而 NonStrict 模式不会发起 Reject。NonStrict 模式下,同属于一个 PodGroup 的 Pod A 和 PodB 调度时,如果 PodA 调度失败不会影响 PodB 调度, PodB 还会继续被调度。NonStrict 模式对于体量较大的 Job 比较友好,可以让这种大体量 Job 更快的调度完成,但同时也增加了资源死锁的风险。后续 Koordinator 会提供 NonStrict 模式下解决死锁的方案实现。
用户在使用时,可以在 PodGroup 或者 Pod 中追加 annotation gang.scheduling.koordinator.sh/mode=NonStrict开启 NonStrict 模式。
改进 PodGroup 调度失败的处理机制,实现更高效的重试调度
举个例子,PodGroup A 关联了5个Pod,其中前3个Pod通过Filter/Score,进入Wait阶段,第4个Pod调度失败,当调度第5个Pod时,发现第4个Pod已经失败,则拒绝调度。在社区 Coscheduling 实现中,调度失败的PodGroup 会加入到基于cache机制的 lastDeniedPG 对象中,当 cache 没有过期,则会拒绝调度;如果过期就允许继续调度。可以看到 cache 的过期时间很关键,过期时间设置的过长会导致Pod迟迟得不到调度机会,设置的过短会出现频繁的无效调度。
而在Enhanced Coscheduling 中,实现了一种基于 ScheduleCycle 的重试机制。以上场景为例,5个Pod的 ScheduleCycle 初始值为 0,PodGroup 对应的 ScheduleCycle 初始值为1;当每一次尝试调度 Pod 时,都会更新 Pod ScheduleCycle 为 PodGroup ScheduleCycle。如果其中一个 Pod 调度失败,会标记当前的 PodGroup ScheduleCycle 无效,之后所有小于 PodGroup ScheduleCycle 的 Pod 都会被拒绝调度。当同一个 PodGroup 下的所有 Pod 都尝试调度一轮后,Pod ScheduleCycle 都更新为当前 PodGroup ScheduleCycle,并递进 PodGroup ScheduleCycle,并标记允许调度。这种方式可以有效规避基于过期时间的缺陷,完全取决于调度队列的配置重试调度。
支持多个 PodGroup 为一组完成 Gang Scheduling
一些复杂的 Job 有多种角色,每个角色管理一批任务,每个角色的任务要求支持 All-or-Nothing ,每个角色的 MinMember 要求也不一样,并且每个角色之间也要求 All-or-Nothing。这就导致每个角色都有一个对应的 PodGroup ,并且还要求 PodGroup 即使满足了也需要等待其他角色的 PodGroup 必须满足。社区 Coscheduling 无法满足这种场景需求。而 Koordinator 实现的 Enhanced Coscheduling 支持用户在多个 PodGroup 中增加 anntation 相关关联实现,并支持跨Namespace。例如用户有2个PodGroup ,名字分别是PodGroupA和PodGroupB,可以按照如下例子关联两个 PodGroup:
apiVersion: v1alpha1
kind: PodGroup
metadata:
name: podGroupA
namespace: default
annotations:
gang.scheduling.koordinator.sh/groups: ["namespaceA/podGroupA", "namespaceB/podGroupB"]
spec:
...
支持轻量化 Gang 协议
如果用户不希望创建 PodGroup,认为创建 PodGroup 太繁琐,那么可以考虑在一组 Pod 中填充相同 annotation gang.scheduling.koordinator.sh/name=<podGroupName> 表示这一组 Pod 使用 Coscheduling 调度。如果期望设置 minMember ,可以追加 Annotation gang.scheduling.koordinator.sh/min-available=<availableNum>。举个例子:
apiVersion: v1
kind: Pod
metadata:
annotations:
gang.scheduling.koordinator.sh/name: "pod-group-a"
gang.scheduling.koordinator.sh/min-available: "5"
name: demo-pod
namespace: default
spec:
...
1.2 ElasticQuota Scheduling
一家中大型公司内有多个产品和研发团队,共用多个比较大规模的 Kubernetes 集群,这些集群内含有的大量 CPU/Memory/Disk 等资源被资源运营团队统一管理。运营团队往往在采购资源前,通过额度预算的机制让公司内每个团队根据自身的需求提交额度预算。业务团队此时一般根据业务当前和对未来的预期做好额度预算。最理想的情况是每一份额度都能够被使用,但现实告诉我们这是不现实的。往往出现的问题是:
- 团队 A 高估了业务的发展速度,申请了太多的额度用不完
- 团队 B 低估了业务的发展速度,申请的额度不够用
- 团队 C 安排了一场活动,手上的额度不够多了,但是活动只持续几周,申请太多额度和资源也会浪费掉。
- 团队 D 下面还有各个子团队和业务,每个子团队内也会出现类似A B C 三个团队的情况,而且其中有些团队的业务临时突发需要提交一些计算任务要交个客户,但是没有额度了,走额度预算审批也不够了。
- ......
以上大家日常经常遇到的场景,在混部场景、大数据场景,临时性突发需求又是时常出现的,这些资源的需求都给额度管理工作带来了极大的挑战。做好额度管理工作,一方面避免过度采购资源降低成本,又要在临时需要额度时不采购资源或者尽量少的采购资源;另一方面不能因为额度问题限制资源使用率,额度管理不好就会导致即使有比较好的技术帮助复用资源,也无法发挥其价值。 总之,额度管理工作是广大公司或组织需长期面对且必须面对的问题。
Kubernetes ResourceQuota 可以解决额度管理的部分问题。 原生 Kubernetes ResourceQuota API 用于指定每个 Namespace 的最大资源额度量,并通过 admission 机制完成准入检查。如果 Namespace 当前资源分配总量超过ResourceQuota 指定的配额,则拒绝创建 Pod。 Kubernetes ResourceQuota 设计有一个局限性:Quota 用量是按照 Pod Requests 聚合的。 虽然这种机制可以保证实际的资源消耗永远不会超过 ResourceQuota 的限制,但它可能会导致资源利用率低,因为一些 Pod 可能已经申请了资源但未能调度。
Kuberenetes Scheduler-Sig 后来给出了一个借鉴 Yarn Capacity Scheduling,称作 ElasticQuota 的设计方案并给出了具体的实现。允许用户设置 max 和 min:
- max 表示用户可以消费的资源上限
- min 表示需要保障用户实现基本功能/性能所需要的最小资源量
通过这两个参数可以帮助用户实现如下的需求:
- 用户设置 min < max 时,当有突发资源需求时,即使当前 ElasticQuota 的总用量超过了 min, 但只要没有达到 max,那么用户可以继续创建新的 Pod 应对新的任务请求。
- 当用户需要更多资源时,用户可以从其他 ElasticQuota 中“借用(borrow)” 还没有被使用并且需要通保障的 min。
- 当一个 ElasticQuota 需要使用 min 资源时,会通过抢占机制从其他借用方抢回来,即驱逐一些其他ElasticQuota 超过 min 用量的 Pod。
ElasticQuota 还有一些局限性:没有很好的保障公平性。假如同一个 ElasticQuota 有大量新建的Pod,有可能会消耗所有其他可以被借用的Quota,从而导致后来的 Pod 可能拿不到 Quota。此时只能通过抢占机制抢回来一些 Quota。
另外 ElasticQuota 和 Kubernetes ResourceQuota 都是面向 Namespace的,不支持多级树形结构,对于一些本身具备复杂组织关系的企业/组织不能很好的使用ElasticQuota/Kubenretes ResourceQuota 完成额度管理工作。
Koordinator 针对这些额度管理问题,给出了一种基于社区 ElasticQuota 实现的支持多级管理方式的弹性Quota管理机制(multi hierarchy quota management)。具备如下特性:
- 兼容社区的 ElasticQuota API。用户可以无缝升级到 Koordinator
- 支持树形结构管理 Quota。
- 支持按照共享权重(shared weight)保障公平性。
- 允许用户设置是否允许借用Quota 给其他消费对象。
Pod 关联 ElasticQuota 方式
用户可以非常使用的使用该能力,可以完全按照 ElasticQuota 的用法,即每个 Namespace 设置一个 ElasticQuota 对象。也可以在 Pod 中追加 Label 关联 ElasticQuota:
apiVersion: v1
kind: Pod
metadata:
labels:
quota.scheduling.koordinator.sh/name: "elastic-quota-a"
name: demo-pod
namespace: default
spec:
...
树形结构管理机制和使用方法
需要使用树形结构管理 Quota 时,需要在 ElasticQuota 中追加 Label quota.scheduling.koordinator.sh/is-parent表示当前 ElasticQuota 是否是父节点,quota.scheduling.koordinator.sh/parent表示当前 ElasticQuota 的父节点 ElasticQuota 的名字。举个例子: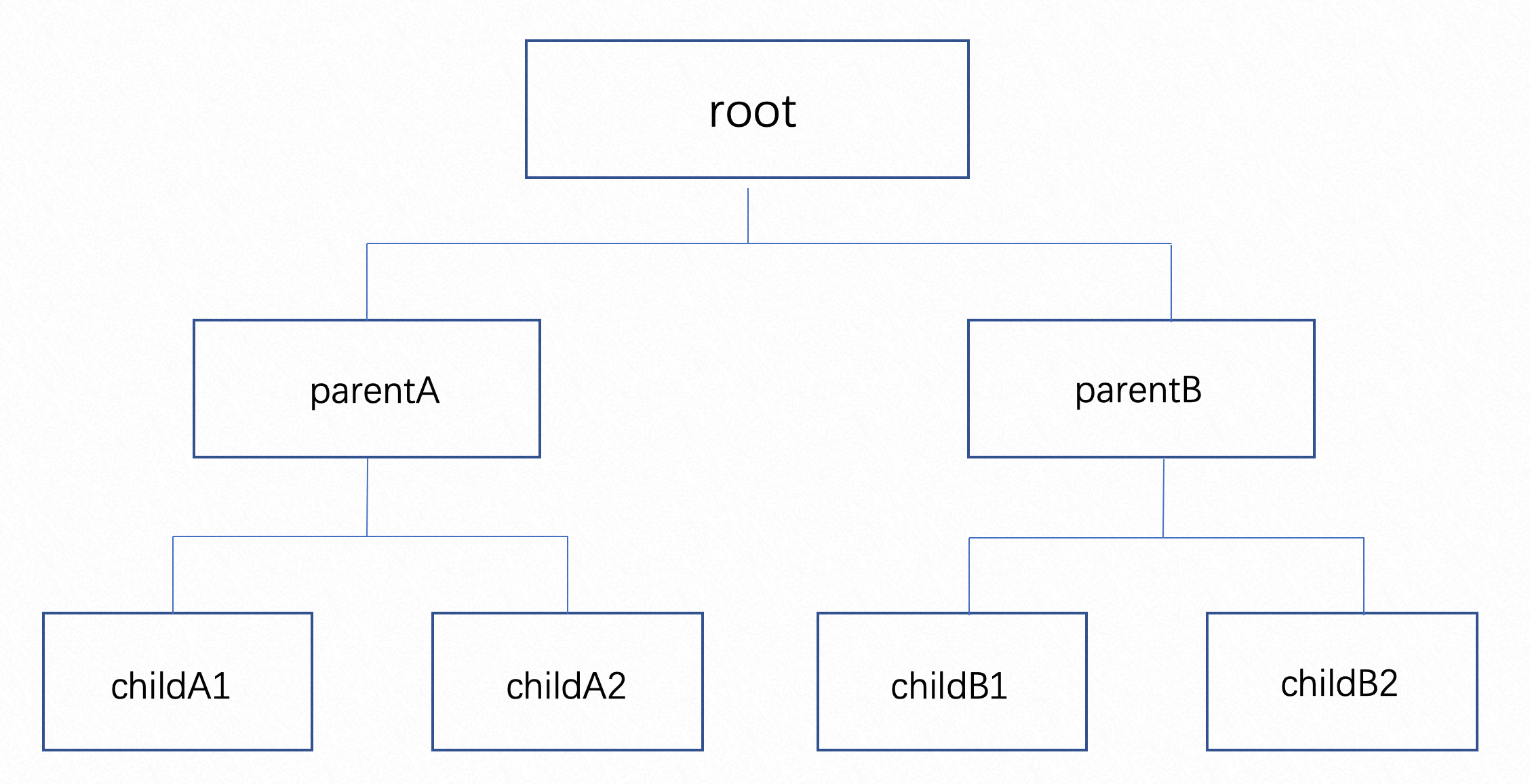
我们创建一个 ElasticQuota Root 作为根节点,资源总量为CPU 100C,内存200Gi,以及子节点 quota-a
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: ElasticQuota
metadata:
name: parentA
namespace: default
labels:
quota.scheduling.koordinator.sh/is-parent: "true"
quota.scheduling.koordinator.sh/allow-lent-resource: "true"
spec:
max:
cpu: 100
memory: 200Gi
min:
cpu: 100
memory: 200Gi
---
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: ElasticQuota
metadata:
name: childA1
namespace: default
labels:
quota.scheduling.koordinator.sh/is-parent: "false"
quota.scheduling.koordinator.sh/parent: "parentA"
quota.scheduling.koordinator.sh/allow-lent-resource: "true"
spec:
max:
cpu: 40
memory: 100Gi
min:
cpu: 20
memory: 40Gi
在使用树形结构管理 ElasticQuota 时,有一些需要遵循的约束:
- 除了根节点,其他所有子节点的 min 之和要小于父节点的 min。
- 不限制子节点 max,允许子节点的 max 大于父节点的 max。考虑以下场景,集群中有 2 个 ElasticQuota 子树:dev-parent 和 production-parent,每个子树都有几个子 ElasticQuota。 当 production-parent 忙时,我们可以通过只降低 dev-parent 的 max 限制 dev-parent 整颗子树的资源使用量,而不是降低 dev-parent 子树的每个子 ElasticQuota 的max限制用量。
- Pod 不能使用父节点ElasticQuota。如果放开这个限制,会导致整个弹性 Quota 的机制变的异常复杂,暂时不考虑支持这种场景。
- 只有父节点可以挂子节点,不允许子节点挂子节点
- 暂时不允许改变 ElasticQuota 的
quota.scheduling.koordinator.sh/is-parent属性
我们将在下个版本中通过 webhook 机制实现这些约束。
公平性保障机制
为了方便阅读和理解将要介绍的公平性保障机制,先明确几个新概念:
- request 表示同一个 ElasticQuota 关联的所有 Pod 的资源请求量。如果一个 ElasticQuota A 的 request 小于 min,ElasticQuota B 的 request 大于 min,那么 ElasticQuota A 未使用的部分,即 min - request 剩余的量通过公平性保障机制借用给 ElasticQuota B. 当 ElasticQuota A 需要使用这些借走的量时,要求 ElasticQuota B 依据公平性保障机制归还给 ElasticQuota A。
- runtime 表示 ElasticQuota 当前可以使用的实际资源量。如果 request 小于 min,runtime 等于 request。这也意味着,需要遵循 min 语义,应无条件满足 request。如果 request 大于 min,且 min 小于 max,公平性保障机制会分配 runtime 在min 与 max 之前,即 max >= runtime >= min。
- shared-weight 表示一个 ElasticQuota 的竞争力,默认等于 ElasticQuota Max。
通过几个例子为大家介绍公平性保障机制的运行过程,假设当前集群的 CPU 总量为100C,并且有4个ElasticQuota,如下图所示,绿色部分为 Request 量:A 当前的request 为5,B当前的request为20,C当前的Request为30,D当前的Request为70。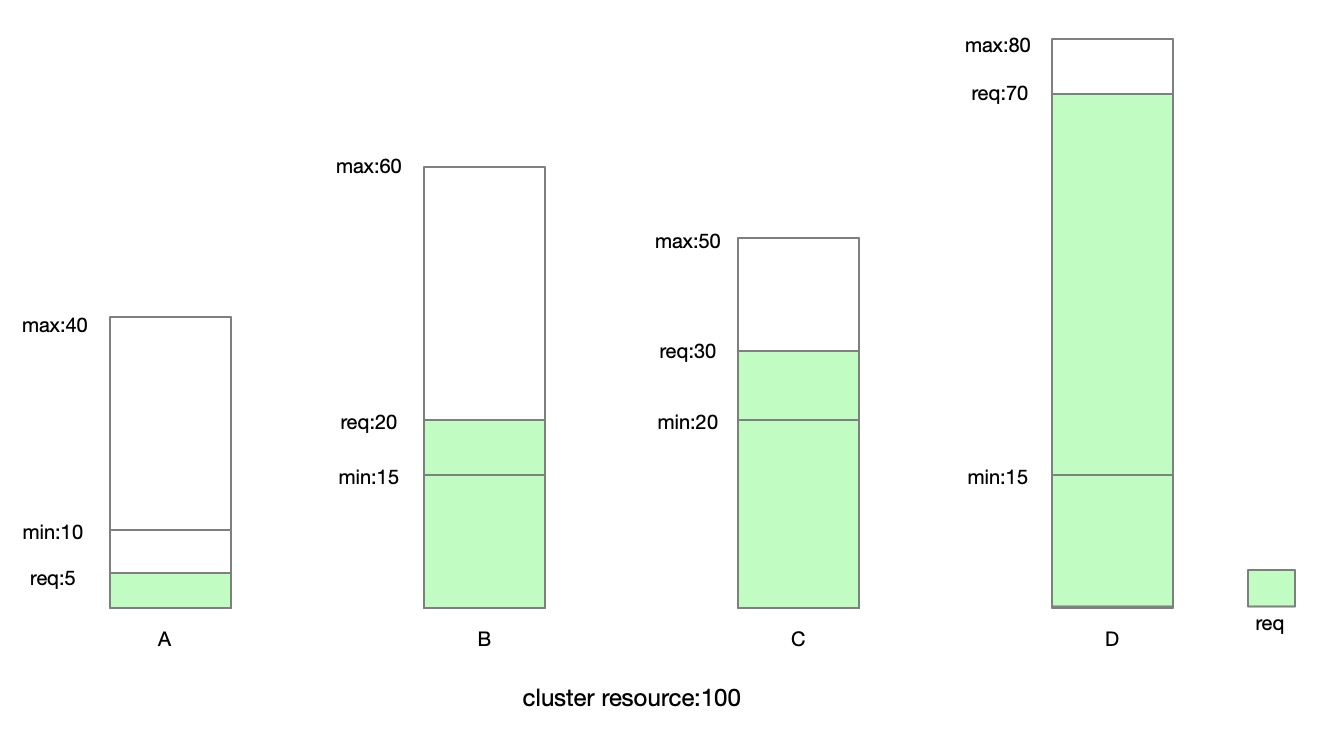
并且我们注意到, A, B, C, D 的 min 之和是60,剩下 40 个空闲额度, 同时 A 还可以借给 B, C, D 5个额度,所以一共有45个额度被B,C,D共享,根据各个ElasticQuota的 shared-weight,B,C,D分别对应60,50和80,计算出各自可以共享的量:
- B 可以获取 14个额度, 45 * 60 / (60 + 50 + 80) = 14
- C 可以获取 12个额度, 45 * 50 / (60 + 50 + 80) = 12
- D 可以获取 19个额度, 45 * 80 / (60 + 50 + 80) = 19
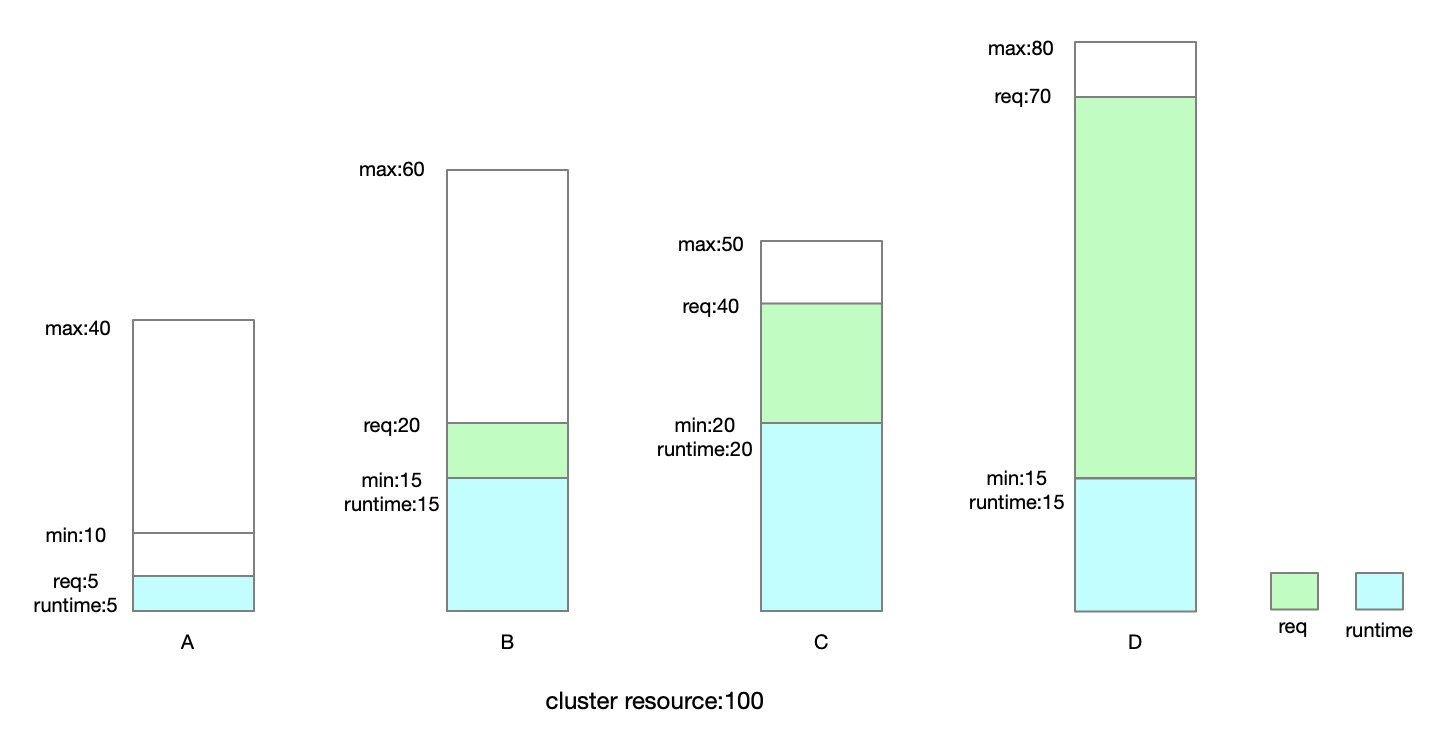
但我们也要注意的是,C和D需要更多额度,而 B只需要5个额度就能满足 Request,并且 B 的min是15,也就意味着我们只需要给 B 5个额度,剩余的9个额度继续分给C和D。
- C 可以获取 3个额度, 9 * 50 / (50 + 80) = 3
- D 可以获取 6个额度, 9 * 80 / (50 + 80) = 6

最终我们得出如下的分配结果结果:
- A runtime = 5
- B runtime = 20
- C runtime = 35
- D runtime = 40

总结整个过程可以知道:
- 当前 request < min 时,需要借出 lent-to-quotas;当 request > min 时,需要借入 borrowed-qutoas
- 统计所有 runtime < min 的 Quota,这些总量就是接下来可被借出的量。
- 根据 shared-weight 计算每个ElasticQuota可以借入的量
- 如果最新的 runtime > reuqest,那么 runtime - request 剩余的量可以借给更需要的对象。
另外还有一种日常生产时会遇到的情况:即集群内资源总量会随着节点故障、资源运营等原因降低,导致所有ElasticQuota的 min 之和大于资源总量。当出现这种情况时,我们无法确保 min 的资源述求。此时我们会按照一定的比例调整各个ElasticQuota的min,确保所有min之和小于或者等于当前实际的资源总量。
抢占机制
Koordinator ElasticQuota 机制在调度阶段如果发现 Quota 不足,会进入抢占阶段,按照优先级排序,抢占属于同一个ElasticQuota 内的 低优先级 Pod。 同时,我们不支持跨 ElasticQuota 抢占其他 Pod。但是我们也提供了另外的机制支持从借用 Quota 的 ElasticQuota 抢回。
举个例子,在集群中,有两个 ElasticQuota,ElasticQuota A {min = 50, max = 100}, ElasticQuota B {min = 50, max = 100}。用户在上午10点使用 ElasticQuota A 提交了一个 Job, Request = 100 ,此时因为 ElasticQuota B 无人使用,ElasticQuota A 能从 B 手里借用50个Quota,满足了 Request = 100, 并且此时 Used = 100。在11点钟时,另一个用户开始使用 ElasticQuota B 提交Job,Request = 100,因为 ElasticQuota B 的 min = 50,是必须保障的,通过公平性保障机制,此时 A 和 B 的 runtime 均为50。那么此时对于 ElasticQuota A ,Used = 100 是大于当前 runtime = 50 的,因此我们会提供一个 Controller,驱逐掉一部分 Pod ,使得当前 ElasticQuota A 的 Used 降低到 runtime 相等的水位。
2. 精细化资源调度
Device Share Scheduling
机器学习领域里依靠大量强大算力性能的 GPU 设备完成模型训练,但是 GPU 自身价格十分昂贵。如何更好地利用GPU设备,发挥GPU的价值,降低成本,是一个亟待解决的问题。 Kubernetes 社区现有的 GPU 分配机制中,GPU 是由 kubelet 分配的,并只支持分配一个或多个完整的 GPU 实例。 这种方法简单可靠,但类似于 CPU 和 Memory,GPU 并不是一直处于高利用率水位,同样存在资源浪费的问题。 因此,Koordinator 希望支持多工作负载共享使用 GPU 设备以节省成本。 此外,GPU 有其特殊性。 比如下面的 NVIDIA GPU 支持的 NVLink 和超卖场景,都需要通过调度器进行中央决策,以获得全局最优的分配结果。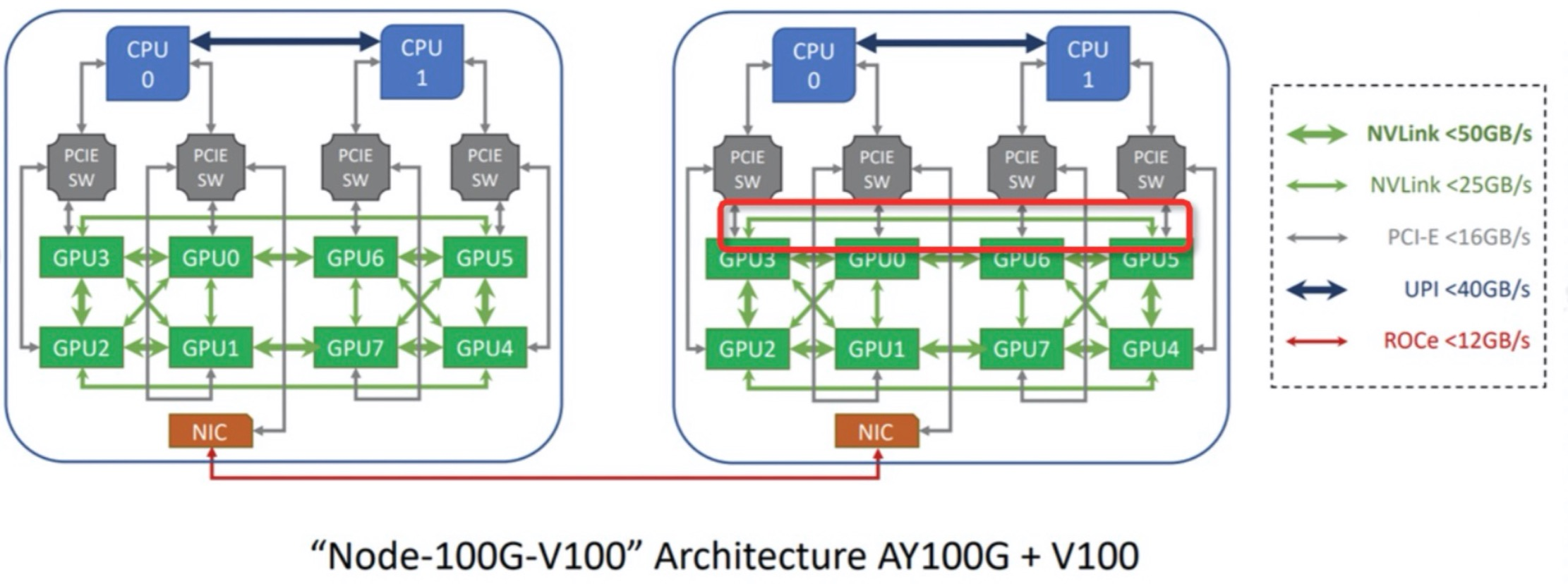
从图中我们可以发现,虽然该节点有8个 GPU 实例,型号为A100/V100,但 GPU 实例之间的数据传输速度是不同的。 当一个 Pod 需要多个 GPU 实例时,我们可以为 Pod 分配具有最大数据传输速度组合关系的 GPU 实例。 此外,当我们希望一组 Pod 中的 GPU 实例具有最大数据传输速度组合关系时,调度器应该将最佳 GPU 实例批量分配给这些 Pod,并将它们分配到同一个节点。
GPU 资源协议
Koordinator 兼容社区已有的 nvidia.com/gpu资源协议,并且还自定义了扩展资源协议,支持用户更细粒度的分配 GPU 资源。
- kubernetes.io/gpu-core 代表GPU的计算能力。 与 Kuberetes MilliCPU 类似,我们将 GPU 的总算力抽象为100,用户可以根据需要申请相应数量的 GPU 算力。
- kubernetes.io/gpu-memory 表示 GPU 的内存容量,以字节为单位。
- kubernetes.io/gpu-memory-ratio 代表 GPU 内存的百分比。
假设一个节点有4个GPU设备实例,每个GPU设备实例有 8Gi 显存。用户如果期望申请一个完整的 GPU 实例,除了使用 nvidia.com/gpu之外,还可以按照如下方式申请:
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
spec:
containers:
- name: main
resources:
limits:
kubernetes.io/gpu-core: 100
kubernetes.io/gpu-memory: "8Gi"
requests:
kubernetes.io/gpu-core: 100
kubernetes.io/gpu-memory: "8Gi"
如果期望只使用一个 GPU 实例一半的资源,可以按照如下方式申请:
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
spec:
containers:
- name: main
resources:
limits:
kubernetes.io/gpu-core: 50
kubernetes.io/gpu-memory: "4Gi"
requests:
kubernetes.io/gpu-core: 50
kubernetes.io/gpu-memory: "4Gi"
设备信息和设备容量上报
在 Koordinator v0.7.0 版本中,单机侧 koordlet 安装后会自动识别节点上是否含有 GPU 设备,如果存在的话,会上报这些 GPU 设备的 Minor ID、 UUID、算力和显存大小到一个类型为 Device CRD 中。每个节点对应一个 Device CRD 实例。Device CRD 不仅支持描述 GPU,还支持类似于 FPGA/RDMA等设备类型,目前 v0.7.0 版本只支持 GPU, 暂未支持这些设备类型。
Device CRD 会被 koord-manager 内的 NodeResource controller 和 koord-scheduler 消费。NodeResource controller 会根据 Device CRD 中描述的信息,换算成 Koordinator 支持的资源协议 kubernetes.io/gpu-core,kubernetes.io/gpu-memory 更新到 Node.Status.Allocatable 和 Node.Status.Capacity 字段,帮助调度器和 kubelet 完成资源调度。gpu-core 表示GPU 设备实例的算力,一个实例的完整算力为100。假设一个节点有 8 个 GPU 设备实例,那么节点的 gpu-core 容量为 8 100 = 800; gpu-memory 表示 GPU 设备实例的显存大小,单位为字节,同样的节点可以分配的显存总量为 设备数量 每个实例的单位容量,例如一个 GPU 设备的显存是 8G,节点上有8 个 GPU 实例,总量为 8 * 8G = 64G。
apiVersion: v1
kind: Node
metadata:
name: node-a
status:
capacity:
koordinator.sh/gpu-core: 800
koordinator.sh/gpu-memory: "64Gi"
koordinator.sh/gpu-memory-ratio: 800
allocatable:
koordinator.sh/gpu-core: 800
koordinator.sh/gpu-memory: "64Gi"
koordinator.sh/gpu-memory-ratio: 800
中心调度分配设备资源
Kuberetes 社区原生提供的设备调度机制中,调度器只负责校验设备容量是否满足 Pod,对于一些简单的设备类型是足够的,但是当需要更细粒度分配 GPU 时,需要中心调度器给予支持才能实现全局最优。
Koordinator 调度器 koord-scheduler 新增了调度插件 DeviceShare,负责精细度设备资源调度。DeviceShare 插件消费 Device CRD,记录每个节点可以分配的设备信息。DeviceShare 在调度时,会把 Pod 的GPU资源请求转换为 Koordinator 的资源协议,并过滤每个节点的未分配的 GPU 设备实例。确保有资源可用后,在 Reserve 阶段更新内部状态,并在 PreBind 阶段更新 Pod Annotation,记录当前 Pod 应该使用哪些 GPU 设备。
DeviceShare 将在后续版本支持 Binpacking 和 Spread 策略,实现更好的设备资源调度能力。
单机侧精准绑定设备信息
Kubernetes 社区在 kubelet 中提供了 DevicePlugin 机制,支持设备厂商在 kubelet 分配好设备后有机会获得设备信息,并填充到环境变量或者更新挂载路径。但是不能支持 中心化的 GPU 精细化调度场景。
针对这个问题, Koordinator 扩展了 koord-runtime-proxy ,支持在 kubelet 创建容器时更新环境变量,注入调度器分配的 GPU 设备信息。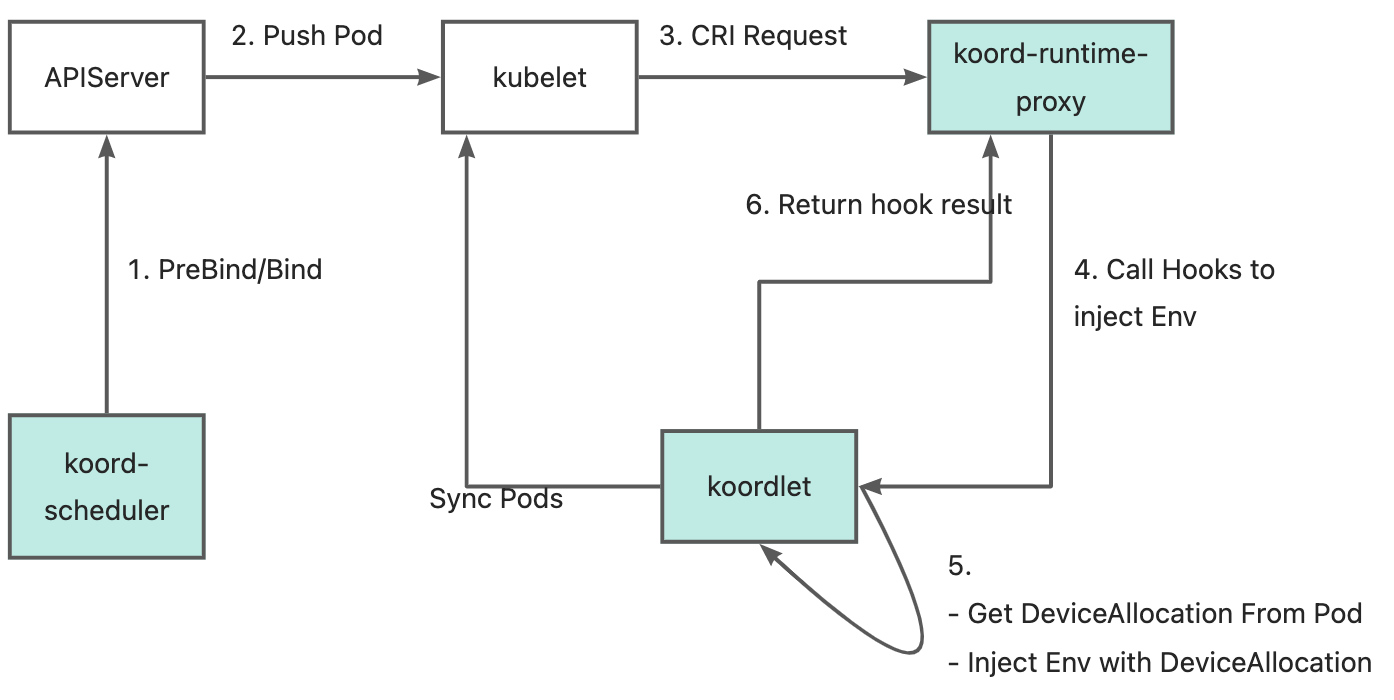
3. 调度器诊断分析
大家在使用 Kubernetes 时经常会遇到一些调度相关的问题:
- 我这个 Pod 为什么不能调度?
- 这个 Pod 为什么会调度到这个节点,不是应该被另一个打分插件影响到么?
- 我新开发了一个插件,发现调度结果不符合预期,但是有不知道哪里出了问题。
要诊断分析这些问题,除了要掌握 Kubernetes 基本的调度机制和资源分配机制外,还需要调度器自身给予支持。但是 Kubernetes kube-scheduler 提供的诊断能力比较有限,有时候甚至没有什么日志可以查看。kube-scheduler 原生是支持通过 HTTP 更改日志等级,可以获得更多日志信息,例如执行如下命令可以更改日志等级到5:
$ curl -X PUT schedulerLeaderIP:10251/debug/flags/v --data '5'
successfully set klog.logging.verbosity to 5
Koordinator 针对这些问题,实现了一套 Restful API ,帮助用户提升问题诊断分析的效率
分析 Score 结果
PUT /debug/flags/s 允许用户打开 Debug Score 开关,在打分结束后,以Markdown 格式打印 TopN 节点各个插件的分值。例如:
$ curl -X PUT schedulerLeaderIP:10251/debug/flags/s --data '100'
successfully set debugTopNScores to 100
当有新 Pod 调度时,观察 scheduler log 可以看到如下信息
| # | Pod | Node | Score | ImageLocality | InterPodAffinity | LoadAwareScheduling | NodeAffinity | NodeNUMAResource | NodeResourcesBalancedAllocation | NodeResourcesFit | PodTopologySpread | Reservation | TaintToleration |
| --- | --- | --- | ---:| ---:| ---:| ---:| ---:| ---:| ---:| ---:| ---:| ---:| ---:|
| 0 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.51 | 577 | 0 | 0 | 87 | 0 | 0 | 96 | 94 | 200 | 0 | 100 |
| 1 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.50 | 574 | 0 | 0 | 85 | 0 | 0 | 96 | 93 | 200 | 0 | 100 |
| 2 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.19 | 541 | 0 | 0 | 55 | 0 | 0 | 95 | 91 | 200 | 0 | 100 |
| 3 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.18 | 487 | 0 | 0 | 15 | 0 | 0 | 90 | 82 | 200 | 0 | 100 |
找个 Markdown 工具,就可以转为如下表格
| # | Pod | Node | Score | LoadAwareScheduling | NodeNUMAResource | NodeResourcesFit | PodTopologySpread |
|---|---|---|---|---|---|---|---|
| 0 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.51 | 577 | 87 | 0 | 94 | 200 |
| 1 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.50 | 574 | 85 | 0 | 93 | 200 |
| 2 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.19 | 541 | 55 | 0 | 91 | 200 |
| 3 | default/curlimage-545745d8f8-rngp7 | cn-hangzhou.10.0.4.18 | 487 | 15 | 0 | 82 | 200 |
调度插件导出内部状态
像 koord-scheduler 内部的 NodeNUMAResource 、 DeviceShare和ElasticQuota等插件内部都有维护一些状态帮助调度。 koord-scheduler 自定义了一个新的插件扩展接口(定义见下文),并会在初始化插件后,识别该插件是否实现了该接口并调用该接口,让插件注入需要暴露的 RestfulAPI。以 NodeNUMAResource 插件为例,会提供 /cpuTopologyOptions/:nodeName和 /availableCPUs/:nodeName两个Endpoints,可以查看插件内部记录的 CPU 拓扑信息和分配结果。
type APIServiceProvider interface {
RegisterEndpoints(group *gin.RouterGroup)
}
用户在使用时,按照 /apis/v1/plugins/<pluginName>/<pluginEndpoints>方 式构建 URL 查看数据,例如要查看 /cpuTopologyOptions/:nodeName:
$ curl schedulerLeaderIP:10252/apis/v1/plugins/NodeNUMAResources/cpuTopologyOptions/node-1
{"cpuTopology":{"numCPUs":32,"numCores":16,"numNodes":1,"numSockets":1,"cpuDetails":....
查看当前支持的插件 API
为了方便大家使用,koord-scheduler 提供了 /apis/v1/__services__ 查看支持的 API Endpoints
$ curl schedulerLeaderIP:10251/apis/v1/__services__
{
"GET": [
"/apis/v1/__services__",
"/apis/v1/nodes/:nodeName",
"/apis/v1/plugins/Coscheduling/gang/:namespace/:name",
"/apis/v1/plugins/DeviceShare/nodeDeviceSummaries",
"/apis/v1/plugins/DeviceShare/nodeDeviceSummaries/:name",
"/apis/v1/plugins/ElasticQuota/quota/:name",
"/apis/v1/plugins/NodeNUMAResource/availableCPUs/:nodeName",
"/apis/v1/plugins/NodeNUMAResource/cpuTopologyOptions/:nodeName"
]
}
4. 更安全的重调度
在 Koordinator v0.6 版本中我们发布了全新的 koord-descheduler,支持插件化实现需要的重调度策略和自定义驱逐机制,并内置了面向 PodMigrationJob 的迁移控制器,通过 Koordinator Reservation 机制预留资源,确保有资源的情况下发起驱逐。解决了 Pod 被驱逐后无资源可用影响应用的可用性问题。
Koordinator v0.7 版本中,koord-descheduler 实现了更安全的重调度
- 支持 Evict 限流,用户可以根据需要配置限流策略,例如允许每分钟驱逐多少个 Pod
- 支持配置 Namespace 灰度重调度能力,让用户可以更放心的灰度
- 支持按照 Node/Namespace 配置驱逐数量,例如配置节点维度最多只驱逐两个,那么即使有插件要求驱逐该节点上的更多Pod,会被拒绝。
- 感知 Workload ,如果一个 Workload 正在发布、缩容、已经有一定量的 Pod 正在被驱逐或者一些Pod NotReady,重调度器会拒绝新的重调度请求。目前支持原生的 Deployment,StatefulSet 以及 Kruise CloneSet,Kruise AdvancedStatefulSet。
后续重调度器还会提升公平性,防止一直重复的重调度同一个 workload ,尽量降低重调度对应用的可用性的影响。
5. 其他改动
- Koordinator 进一步增强了 CPU 精细化调度能力,完全兼容 kubelet ( <= v1.22) CPU Manager static 策略。调度器分配 CPU 时会避免分配被 kubelet 预留的 CPU,单机侧koordlet完整适配了kubelet从1.18到1.22版本的分配策略,有效避免了 CPU 冲突。
- 资源预留机制支持 AllocateOnce 语义,满足单次预留场景。并改进了 Reservation 状态语义,更加准确描述 Reservation 对象当前的状态。
- 改进了离线资源(Batch CPU/Memory) 的声明方式,支持limit大于request的资源描述形式,可以方便原burstable类型的任务直接转换为混部模式运行。
你可以通过 Github release[6] 页面,来查看更多的改动以及它们的作者与提交记录。



