



Background
As artificial intelligence continues to evolve, the scale and complexity of AI model training are growing exponentially. Large language models (LLMs) and distributed AI training scenarios place unprecedented demands on cluster resource scheduling. Efficient inter-pod communication, intelligent resource preemption, and unified heterogeneous device management have become critical challenges that production environments must address.
Since its official open-source release in April 2022, Koordinator has iterated through 15 major versions, consistently delivering comprehensive solutions for workload orchestration, resource scheduling, isolation, and performance optimization. The Koordinator community is grateful for the contributions from outstanding engineers at Alibaba, Ant Technology Group, Intel, XiaoHongShu, Xiaomi, iQiyi, 360, YouZan, and other organizations, who have provided invaluable ideas, code, and real-world scenarios.
Today, we are excited to announce the release of Koordinator v1.7.0. This version introduces groundbreaking capabilities tailored for large-scale AI training scenarios, including Network-Topology Aware Scheduling and Job-Level Preemption. Additionally, v1.7.0 enhances heterogeneous device scheduling with support for Huawei Ascend NPU and Cambricon MLU, providing end-to-end device management solutions. The release also includes comprehensive API Reference Documentation and a complete Developer Guide to improve the developer experience.
In the v1.7.0 release, 14 new developers actively contributed to the Koordinator community: @ditingdapeng, @Rouzip, @ClanEver, @zheng-weihao, @cntigers, @LennonChin, @ZhuZhezz, @dabaooline, @bobsongplus, @yccharles, @qingyuanz, @yyrdl, @hwenwur, and @hkttty2009. We sincerely thank all community members for their active participation and ongoing support!
Key Features
1. Network-Topology Aware Scheduling: Accelerating Communication in Distributed AI Training
In large-scale AI training scenarios, especially for large language models (LLMs), efficient inter-pod communication is critical to training performance. Model parallelism techniques such as Tensor Parallelism (TP), Pipeline Parallelism (PP), and Data Parallelism (DP) require frequent and high-bandwidth data exchange across GPUs—often spanning multiple nodes. Under such workloads, network topology becomes a key performance bottleneck, where communication latency and bandwidth are heavily influenced by the physical network hierarchy (e.g., NVLink, block, spine).
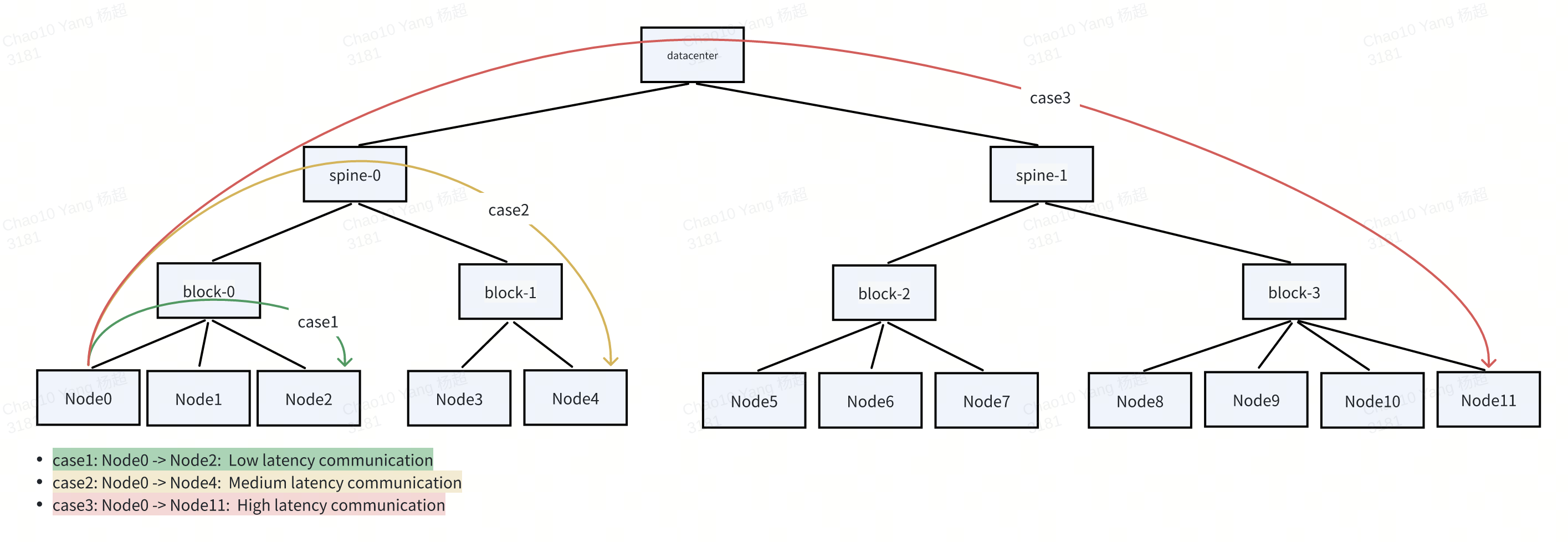
To optimize training efficiency, Koordinator v1.7.0 provides Network-Topology Aware Scheduling capability, which ensures:
- When cluster resources are sufficient, pods with network topology requirements will be scheduled to topology domains with better performance (e.g., lower latency, higher bandwidth) according to user-specified strategies.
- When cluster resources are insufficient, the scheduler will preempt resources for the GangGroup based on network topology constraints through job-level preemption, and record the resource nominations in the
.status.nominatedNodefield to ensure consistent placement.
Cluster Network Topology Configuration
Administrators first label nodes with their network topology positions using tools like NVIDIA's topograph:
apiVersion: v1
kind: Node
metadata:
name: node-0
labels:
network.topology.nvidia.com/block: b1
network.topology.nvidia.com/spine: s1
Then define the topology hierarchy via a ClusterNetworkTopology CR:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: ClusterNetworkTopology
metadata:
name: default
spec:
networkTopologySpec:
- labelKey:
- network.topology.nvidia.com/spine
topologyLayer: SpineLayer
- labelKey:
- network.topology.nvidia.com/block
parentTopologyLayer: SpineLayer
topologyLayer: BlockLayer
- parentTopologyLayer: BlockLayer
topologyLayer: NodeTopologyLayer
Configuring Topology-Aware Gang Scheduling
To leverage network topology awareness, create a PodGroup and annotate it with topology requirements:
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: training-job
namespace: default
annotations:
gang.scheduling.koordinator.sh/network-topology-spec: |
{
"gatherStrategy": [
{
"layer": "BlockLayer",
"strategy": "PreferGather"
}
]
}
spec:
minMember: 8
scheduleTimeoutSeconds: 300
When scheduling pods belonging to this PodGroup, the scheduler will attempt to place all member pods within the same BlockLayer topology domain to minimize inter-node communication latency.
For more information about Network-Topology Aware Scheduling, please see Network Topology Aware Scheduling.
2. Job-Level Preemption: Ensuring All-or-Nothing Resource Acquisition
In large-scale cluster environments, high-priority jobs (e.g., critical AI training tasks) often need to preempt resources from lower-priority workloads when sufficient resources are not available. However, traditional pod-level preemption in Kubernetes cannot guarantee that all member pods of a distributed job will seize resources together, leading to invalid preemption and resource waste.
To solve this, Koordinator v1.7.0 provides Job-Level Preemption, which ensures that:
- Preemption is triggered at the job (GangGroup) level.
- Only when all member pods can be co-scheduled after eviction will preemption occur.
- Resources are reserved via
nominatedNodefor all members to maintain scheduling consistency.
Preemption Algorithm
The job-level preemption workflow consists of the following steps:
- Unschedulable Pod Detection: When a pod cannot be scheduled, it enters the PostFilter phase.
- Job Identification: The scheduler checks if the pod belongs to a PodGroup/GangGroup and fetches all member pods.
- Preemption Eligibility Check: Verifies that
pods.spec.preemptionPolicy≠ Never and ensures no terminating victims exist on currently nominated nodes. - Candidate Node Selection: Finds nodes where preemption may help by simulating the removal of potential victims (lower-priority pods).
- Job-Aware Cost Model: Selects the optimal node and minimal-cost victim set based on a job-aware cost model.
- Preemption Execution: Deletes victims and sets
status.nominatedNodefor all member pods.
Usage Example
Define priority classes for preemptors and victims:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
preemptionPolicy: PreemptLowerPriority
description: "Used for critical AI training jobs that can preempt others."
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: 1000
preemptionPolicy: PreemptLowerPriority
description: "Used for non-critical jobs that can be preempted."
Create a high-priority gang job:
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: hp-training-job
namespace: default
spec:
minMember: 2
scheduleTimeoutSeconds: 300
---
apiVersion: v1
kind: Pod
metadata:
name: hp-worker-1
namespace: default
labels:
pod-group.scheduling.sigs.k8s.io: hp-training-job
spec:
schedulerName: koord-scheduler
priorityClassName: high-priority
preemptionPolicy: PreemptLowerPriority
containers:
- name: worker
resources:
limits:
cpu: 3
memory: 4Gi
requests:
cpu: 3
memory: 4Gi
When the high-priority job cannot be scheduled, the scheduler will preempt low-priority pods across multiple nodes to make room for all member pods of the job.
For more information about Job-Level Preemption, please see Job Level Preemption.
3. Heterogeneous Device Scheduling: Support for Huawei Ascend NPU and Cambricon MLU
Building on the strong foundation of GPU scheduling in v1.6, Koordinator v1.7.0 extends heterogeneous device scheduling to support Huawei Ascend NPU and Cambricon MLU, providing unified device management and scheduling capabilities across multiple vendors.
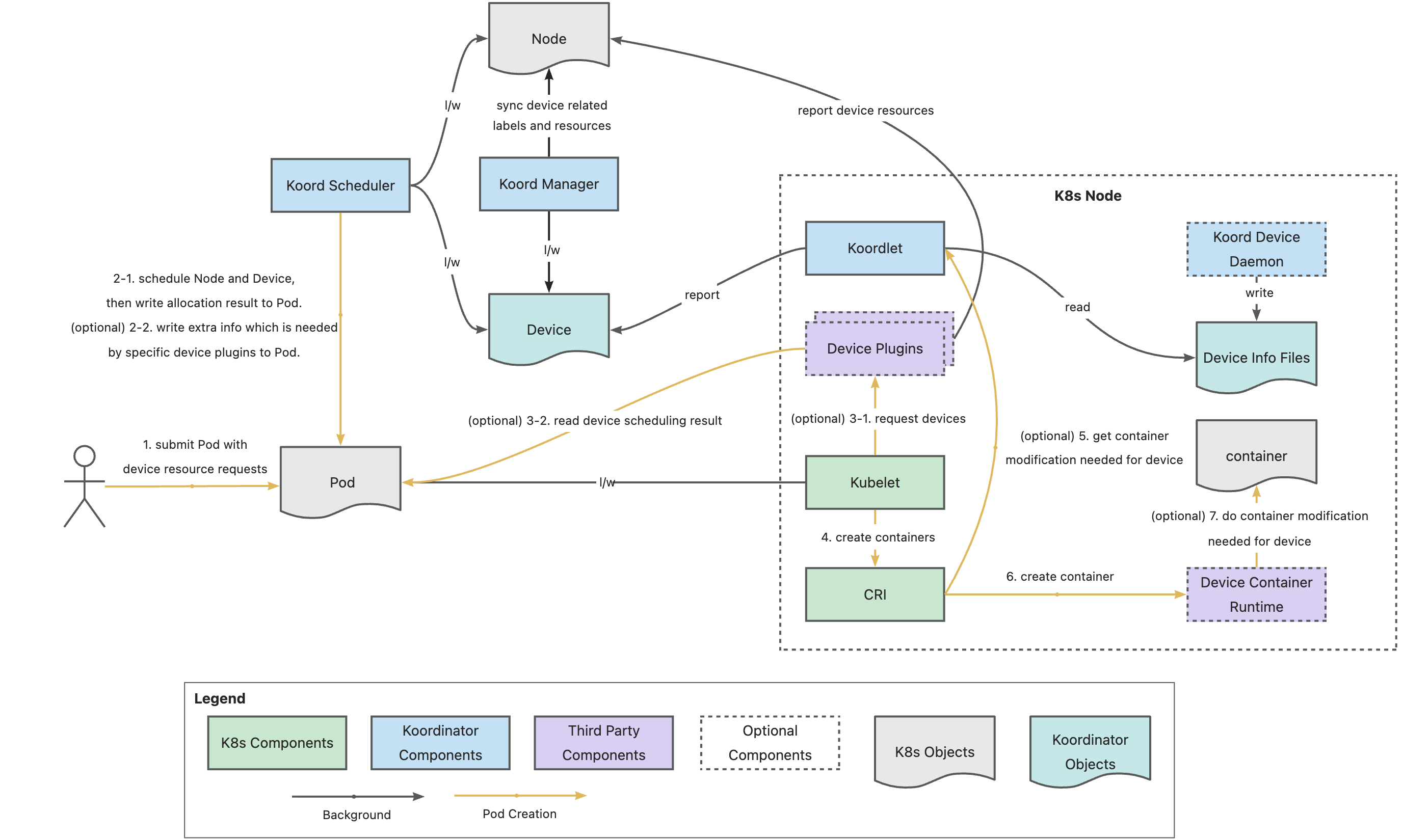
Huawei Ascend NPU Support
Koordinator v1.7.0 supports both Ascend virtualization templates and full cards through the koord-device-daemon and koordlet components. Key features include:
- Device Reporting: Automatically detects and reports Ascend NPU information to the Device CR.
- Partition-Aware Scheduling: Respects predefined GPU partition rules for HCCS affinity.
- Topology Scheduling: Allocates NPUs based on PCIe and NUMA topology.
Example Device CR for Ascend NPU:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Device
metadata:
labels:
node.koordinator.sh/gpu-model: Ascend-910B3
node.koordinator.sh/gpu-vendor: huawei
annotations:
scheduling.koordinator.sh/gpu-partitions: |
{
"4": [
{
"minors": [0,1,2,3],
"gpuLinkType": "HCCS",
"allocationScore": "1"
}
]
}
name: node-1
spec:
devices:
- health: true
id: GPU-fd971b33-4891-fd2e-ed42-ce6adf324615
minor: 0
resources:
huawei.com/npu-core: "20"
huawei.com/npu-cpu: "7"
huawei.com/npu-dvpp: "100"
koordinator.sh/gpu-memory: 64Gi
koordinator.sh/gpu-memory-ratio: "100"
topology:
busID: 0000:3b:00.0
nodeID: 0
pcieID: pci0000:3a
type: gpu
Cambricon MLU Support
Koordinator v1.7.0 supports Cambricon MLU cards in both full-card and virtualization (dynamic-smlu) modes. Key features include:
- Device Reporting: Detects and reports Cambricon MLU information.
- Virtualization Support: Enables GPU sharing through dynamic-smlu mode.
- Unified Resource Naming: Uses
koordinator.sh/gpu-*resources for consistent scheduling.
Example Pod requesting Cambricon virtual card:
apiVersion: v1
kind: Pod
metadata:
name: test-cambricon-partial
namespace: default
spec:
schedulerName: koord-scheduler
containers:
- name: demo-sleep
image: ubuntu:18.04
resources:
limits:
koordinator.sh/gpu.shared: "1"
koordinator.sh/gpu-memory: "1Gi"
koordinator.sh/gpu-core: "10"
cambricon.com/mlu.smlu.vcore: "10"
cambricon.com/mlu.smlu.vmemory: "4"
requests:
koordinator.sh/gpu.shared: "1"
koordinator.sh/gpu-memory: "1Gi"
koordinator.sh/gpu-core: "10"
cambricon.com/mlu.smlu.vcore: "10"
cambricon.com/mlu.smlu.vmemory: "4"
For more information, please see Device Scheduling - Ascend NPU and Device Scheduling - Cambricon MLU.
4. Other Enhancements and Improvements
Koordinator v1.7.0 also includes the following key enhancements:
GPU Share with HAMi Enhancements:
- Upgraded to HAMi v2.6.0 with support for NVIDIA drivers above 570.
- Introduced Helm-based installation via
hami-daemonchart (version 0.1.0) replacing manual DaemonSet deployment for easier management. - Added vGPUmonitor component for comprehensive GPU monitoring with Prometheus metrics including
HostGPUMemoryUsage,HostCoreUtilization,vGPU_device_memory_usage_in_bytes,vGPU_device_memory_limit_in_bytes, and container-level device metrics.
Load-Aware Scheduling Optimization:
- Added PreFilter extension point for caching calculation results to significantly improve scheduling performance.
- Introduced new configuration options including
dominantResourceWeightfor dominant resource fairness,prodUsageIncludeSysfor comprehensive prod usage calculation,enableScheduleWhenNodeMetricsExpiredfor expired metrics handling,estimatedSecondsAfterPodScheduledandestimatedSecondsAfterInitializedfor precise resource estimation timing,allowCustomizeEstimationfor pod-level estimation customization, andsupportedResourcesfor extended resource type support.
Enhanced ElasticQuota with Quota Hook Plugin framework:
- Allows custom quota validation and enforcement logic
- Supports hook plugins in ReplaceQuotas and OnQuotaUpdate methods
- Enhanced pod update hook that runs regardless of whether used resources have changed
For a complete list of changes, please see v1.7.0 Release.
5. Comprehensive API Reference and Developer Guide
To improve the developer experience and facilitate community contributions, Koordinator v1.7.0 introduces comprehensive API Reference Documentation and a complete Developer Guide.
API Reference
The new API Reference provides detailed documentation for:
- Custom Resource Definitions (CRDs): Comprehensive schema definitions, field descriptions, validation rules, and usage patterns for all Koordinator CRDs, including Recommendation, ClusterColocationProfile, ElasticQuota, Reservation, Device, NodeMetric, and more.
- Client Libraries: Guidelines for using Koordinator's client libraries in Go, Python, and other languages.
- Metrics Endpoints: Complete documentation of Prometheus metrics exposed by Koordinator components.
- Webhook Endpoints: Detailed specifications of webhook endpoints for extending Koordinator's functionality.
Example from the Custom Resource Definitions documentation:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Device
metadata:
name: worker01
labels:
node.koordinator.sh/gpu-model: NVIDIA-H20
node.koordinator.sh/gpu-vendor: nvidia
spec:
devices:
- health: true
id: GPU-a43e0de9-28a0-1e87-32f8-f5c4994b3e69
minor: 0
resources:
koordinator.sh/gpu-core: "100"
koordinator.sh/gpu-memory: 97871Mi
koordinator.sh/gpu-memory-ratio: "100"
topology:
busID: 0000:0e:00.0
nodeID: 0
pcieID: pci0000:0b
type: gpu
Developer Guide
The Developer Guide provides comprehensive resources for contributors, including:
- Component Guide: Architecture and design of Koordinator components.
- Metrics Collection: How to add and expose new metrics.
- Extensibility: Extension points and plugin development patterns.
- Plugin Development: Step-by-step guide to developing custom plugins.
- Custom Scheduling Policies: How to implement custom scheduling policies.
- Webhook Extensions: Developing webhook extensions for validation and mutation.
- Custom Descheduler Plugins: Building custom descheduler plugins.
These resources significantly lower the barrier to entry for new contributors and enable developers to extend Koordinator's capabilities more easily.
For more information, please see API Reference and Developer Guide.
6. Best Practices: Batch Colocation Quick Start
To help users quickly get started with Koordinator's colocation capabilities, v1.7.0 introduces a new best practice guide: Batch Colocation Quick Start. This guide provides step-by-step instructions for:
- Deploying Koordinator in a Kubernetes cluster.
- Configuring colocation profiles for online and batch workloads.
- Observing resource utilization improvements through batch resource overcommitment.
- Monitoring and troubleshooting colocation scenarios.
This guide complements the existing best practices for Spark job colocation, Hadoop YARN colocation, and fine-grained CPU orchestration, providing a comprehensive resource library for production deployments.
For more information, please see Batch Colocation Quick Start.
Contributors
Koordinator is an open source community. In v1.7.0, there are 14 new developers who contributed to the Koordinator main repo:
@ditingdapeng made their first contribution in #2353
@Rouzip made their first contribution in #2005
@ClanEver made their first contribution in #2405
@zheng-weihao made their first contribution in #2409
@cntigers made their first contribution in #2434
@LennonChin made their first contribution in #2449
@ZhuZhezz made their first contribution in #2423
@dabaooline made their first contribution in #2483
@bobsongplus made their first contribution in #2524
@yccharles made their first contribution in #2474
@qingyuanz made their first contribution in #2584
@yyrdl made their first contribution in #2597
@hwenwur made their first contribution in #2621
@hkttty2009 made their first contribution in #2641
Thanks for the elders for their consistent efforts and the newbies for their active contributions. We welcome more contributors to join the Koordinator community.
Future Plan
In the next versions, Koordinator plans the following works:
- Queue and Quota Management: Integrate Kube-Queue with Koordinator for comprehensive queue scheduling support (#2662)
- Queue and Quota Management: Support PreEnqueue and QueueHint in Quota plugin (#2581)
- Queue and Quota Management: Enhance Quota resource reclamation with PDB awareness (#2651)
- Task Scheduling: Discuss with upstream developers about how to support Coscheduling and find a more elegant way to solve the following problems
- Addressing the issue where PreEnqueue interception of Gang Pods prevents Pod events from being generated until the Gang MinMember requirement is met. (#2480)
- Address GatedMetric Negative issues (kubernetes#133464)
- Heterogeneous Scheduling Strategy: Consider GPU allocation in rescheduling for cluster resource consolidation (#2332)
- Heterogeneous Resources Scheduling: Introduce Dynamic Resource Allocation (DRA) framework support
- Heterogeneous Resources Scheduling: Expand support for more types of heterogeneous resources
- Infrastructure and Compatibility: Upgrade to Kubernetes 1.33
- Utils: Support PreAllocation in Reservation (#2150)
- Utils: Implement Pod scheduling audit for pods in schedulingQueue (#2552)
- Utils: Provide tooling for Pod scheduling audit analysis
We encourage user feedback on usage experiences and welcome more developers to participate in the Koordinator project, jointly driving its development!
Acknowledgement
Since the project was open-sourced, Koordinator has been released for more than 15 versions, with 110+ contributors involved. The community continues to grow and improve. We thank all community members for their active participation and valuable feedback. We also want to thank the CNCF organization and related community members for supporting the project.
Welcome more developers and end users to join us! It is your participation and feedback that make Koordinator keep improving. Whether you are a beginner or an expert in the Cloud Native communities, we look forward to hearing your voice!