


背景
随着 DeepSeek 等大模型的火爆,AI 和高性能计算领域对异构设备资源调度的需求迅速增长,无论是 GPU、NPU 还是 RDMA 等设备。如何高效管理和调度这些资源成为了行业关注的核心问题。在这一背景下,Koordinator 积极响应社区诉求,持续深耕异构设备调度能力,并在最新的 v1.6 版本中推出了一系列创新功能,帮助客户解决异构资源调度难题。
在 v1.6 版本中,我们完善了设备拓扑调度能力,支持感知更多机型的 GPU 拓扑结构,显著加速 AI 应用内的 GPU 互联性能。与开源项目 HAMi 合作,推出了端到端的 GPU & RDMA 联合分配能力以及 GPU 强隔离能力,有效提升了典型 AI 训练任务的跨机互联效率和推理任务的部署密度,从而更好地保障应用性能并提高集群资源利用率。同时,增强了 Kubernetes 社区的资源插件,使其可以对不同资源配置不同的节点打分策略,该功能在 GPU 任务和 CPU 任务混部在一个集群中时能有效降低 GPU 碎片率。
自 2022 年 4 月正式开源以来,Koordinator 已迭代发布了 14 个大版本,吸引了来自阿里巴巴、蚂蚁科技、Intel、小红书、小米、爱奇艺、360、有赞等众多企业的优秀工程师参与贡献。他们带来了丰富的想法、代码和实际应用场景,极大地推动了项目的发展。特别值得一提的是,在 v1.6.0 版本中,共有 10 位新加入的开发者积极参与到 Koordinator 社区的建设中,他们是 @LY-today、@AdrianMachao、@TaoYang526、@dongjiang1989、@chengjoey、@JBinin、@clay-wangzhi、@ferris-cx、@nce3xin 和 @lijunxin559。感谢他们的贡献,也感谢所有社区成员的持续投入和支持!
核心亮点功能
1、GPU 拓扑感知调度:加速 AI 应用内的 GPU 互联
随着深度学习和高性能计算(HPC)等领域的快速发展,GPU 成为许多计算密集型工作负载的核心资源。在 Kubernetes 集群中,GPU 的高效利用对于提升应用性能至关重要。然而,GPU 资源的性能表现并不均衡,受到硬件拓扑结构和资源配置的影响。例如
- 在多 NUMA 节点的系统中,GPU、CPU 和内存之间的物理连接可能会影响数据传输速度和计算效率。
- 对于 NVIDIA 的 L20、L40S 等卡型,GPU 之间的通信效率取决于它们是否属于同一个 PCIE 或者同一个 NUMANode。
- 对于华为的晟腾 NPU 以及虚拟化环境中采用 SharedNVSwitch 模式的 NVIDIA H系列机器,GPU 的分配需要遵守一些预定义的 Partition 规则。
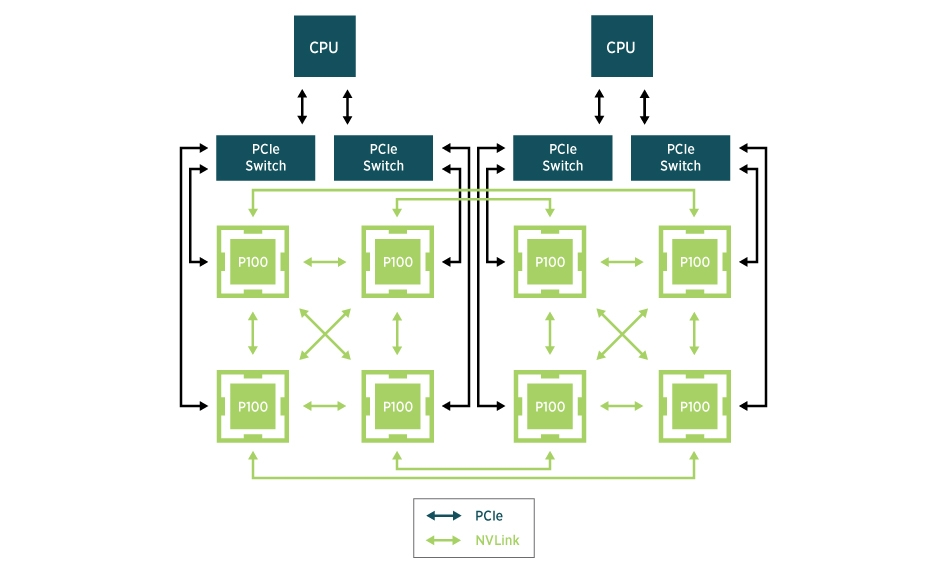
Koordinator 针对上述设备场景,提供了丰富的设备拓扑调度 API 来满足 Pod 对于 GPU 拓扑的诉求。下面是这些 API 的使用举例:
- GPU、CPU、内存等分配在同一个 NUMA Node
apiVersion: v1
kind: Pod
metadata:
annotations:
scheduling.koordinator.sh/numa-topology-spec: '{"numaTopologyPolicy":"Restricted", "singleNUMANodeExclusive":"Preferred"}'
spec:
containers:
- resources:
limits:
koordinator.sh/gpu: 200
cpu: 64
memory: 500Gi
requests:
koordinator.sh/gpu: 200
cpu: 64
memory: 500Gi - GPU 分配在同一个 PCIE
apiVersion: v1
kind: Pod
metadata:
annotations:
scheduling.koordinator.sh/device-allocate-hint: |-
{
"gpu": {
"requiredTopologyScope": "PCIe"
}
}
spec:
containers:
- resources:
limits:
koordinator.sh/gpu: 200 - GPU 分配在同一个 NUMA Node
apiVersion: v1
kind: Pod
metadata:
annotations:
scheduling.koordinator.sh/device-allocate-hint: |-
{
"gpu": {
"requiredTopologyScope": "NUMANode"
}
}
spec:
containers:
- resources:
limits:
koordinator.sh/gpu: 400 - GPU 需按照预定义的 Partition 分配
通常,GPU 预定义 Partition 规则由特定的 GPU 型号或系统配置决定,也可能受到具体节点上的 GPU 配置的影响。调度器无法洞悉硬件型号或 GPU 类型的具体信息;相反,它依靠节点级别的组件将这些预定义规则上报给设备自定义资源 (CR) 来知晓,如下所示:
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Device
metadata:
annotations:
scheduling.koordinator.sh/gpu-partitions: |
{
"1": [
"NVLINK": {
{
# Which GPUs are included
"minors": [
0
],
# GPU Interconnect Type
"gpuLinkType": "NVLink",
# Here we take the bottleneck bandwidth between GPUs in the Ring algorithm. BusBandwidth can be referenced from https://github.com/NVIDIA/nccl-tests/blob/master/doc/PERFORMANCE.md
"ringBusBandwidth": 400Gi
# Indicate the overall allocation quality for the node after the partition has been assigned away.
"allocationScore": "1",
},
...
}
...
],
"2": [
...
],
"4": [
...
],
"8": [
...
]
}
labels:
// 指示 Partition 规则是否必须遵守
node.koordinator.sh/gpu-partition-policy: "Honor"
name: node-1
当同时有多个可选的 Partition 方案时,Koordinator 允许用户决定是否按照最优 Partition 分配:
kind: Pod
metadata:
name: hello-gpu
annotations:
scheduling.koordinator.sh/gpu-partition-spec: |
{
# BestEffort|Restricted
"allocatePolicy": "Restricted",
}
spec:
containers:
- name: main
resources:
limits:
koordinator.sh/gpu: 100
当用户不需要按照最优 Partition 分配时,调度器将会按照尽可能 Binpack 的方式分配。 想要了解关于 GPU 拓扑感知调度的更多细节,请参考如下设计文档:
由衷感谢社区开发者 @eahydra 对该特性的贡献!
2、端到端 GDR 支持:提升跨机任务的互联性能
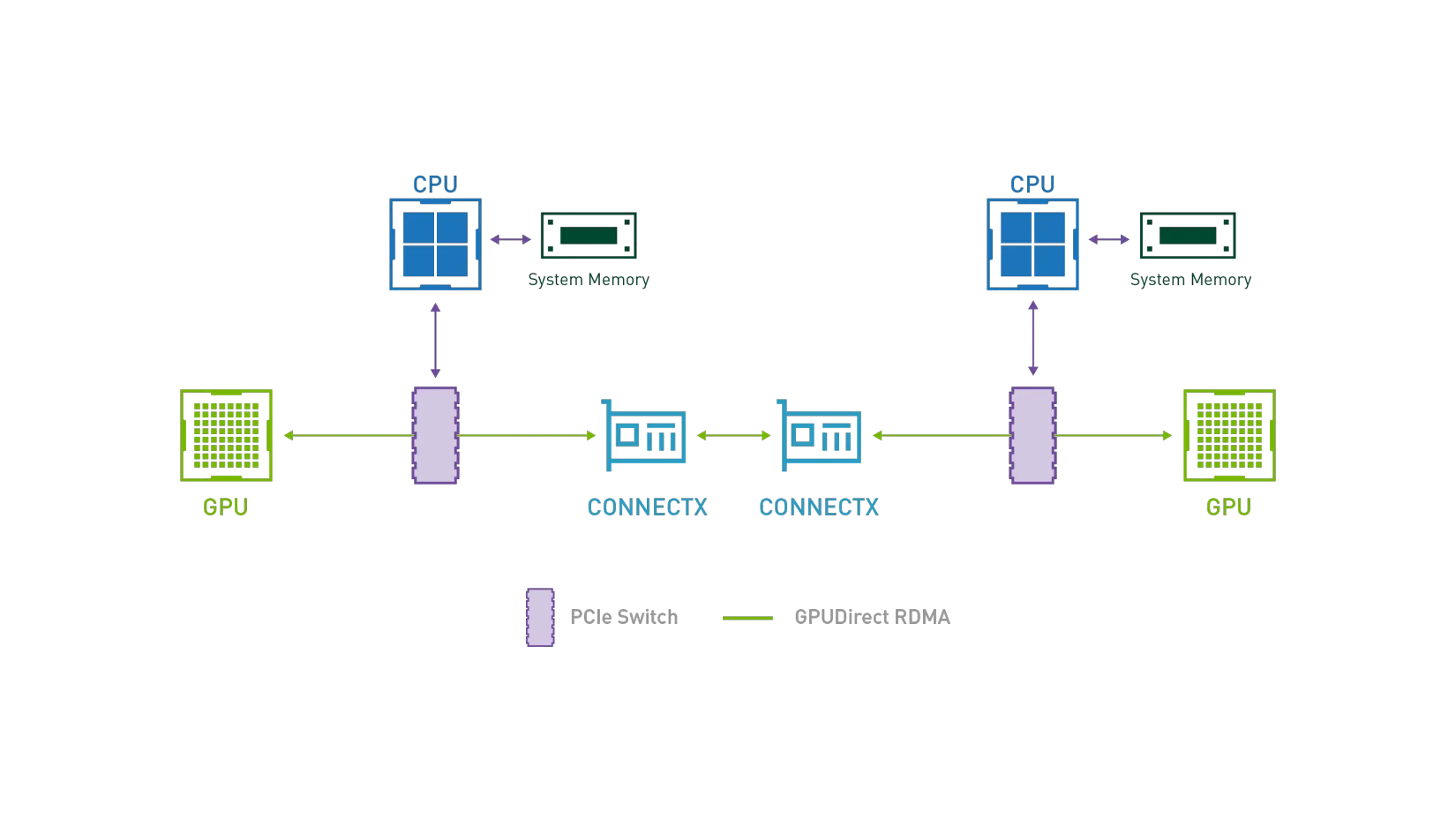 在 AI 模型训练场景中,GPU 之间需要进行频繁的集合通信,以同步训练过程迭代更新的权重。GDR 全称叫做 GPUDirect RDMA,其目的是解决多机 GPU 设备之间交换数据的效率问题。通过 GDR 技术多机之间 GPU 交换数据可以不经过 CPU 和内存,大幅节省 CPU/Memory 开销同时降低延时。为了实现这一目标,Koordinator v1.6.0 版本中设计实现了 GPU/RDMA 设备联合调度特性,整体架构如下:
在 AI 模型训练场景中,GPU 之间需要进行频繁的集合通信,以同步训练过程迭代更新的权重。GDR 全称叫做 GPUDirect RDMA,其目的是解决多机 GPU 设备之间交换数据的效率问题。通过 GDR 技术多机之间 GPU 交换数据可以不经过 CPU 和内存,大幅节省 CPU/Memory 开销同时降低延时。为了实现这一目标,Koordinator v1.6.0 版本中设计实现了 GPU/RDMA 设备联合调度特性,整体架构如下:
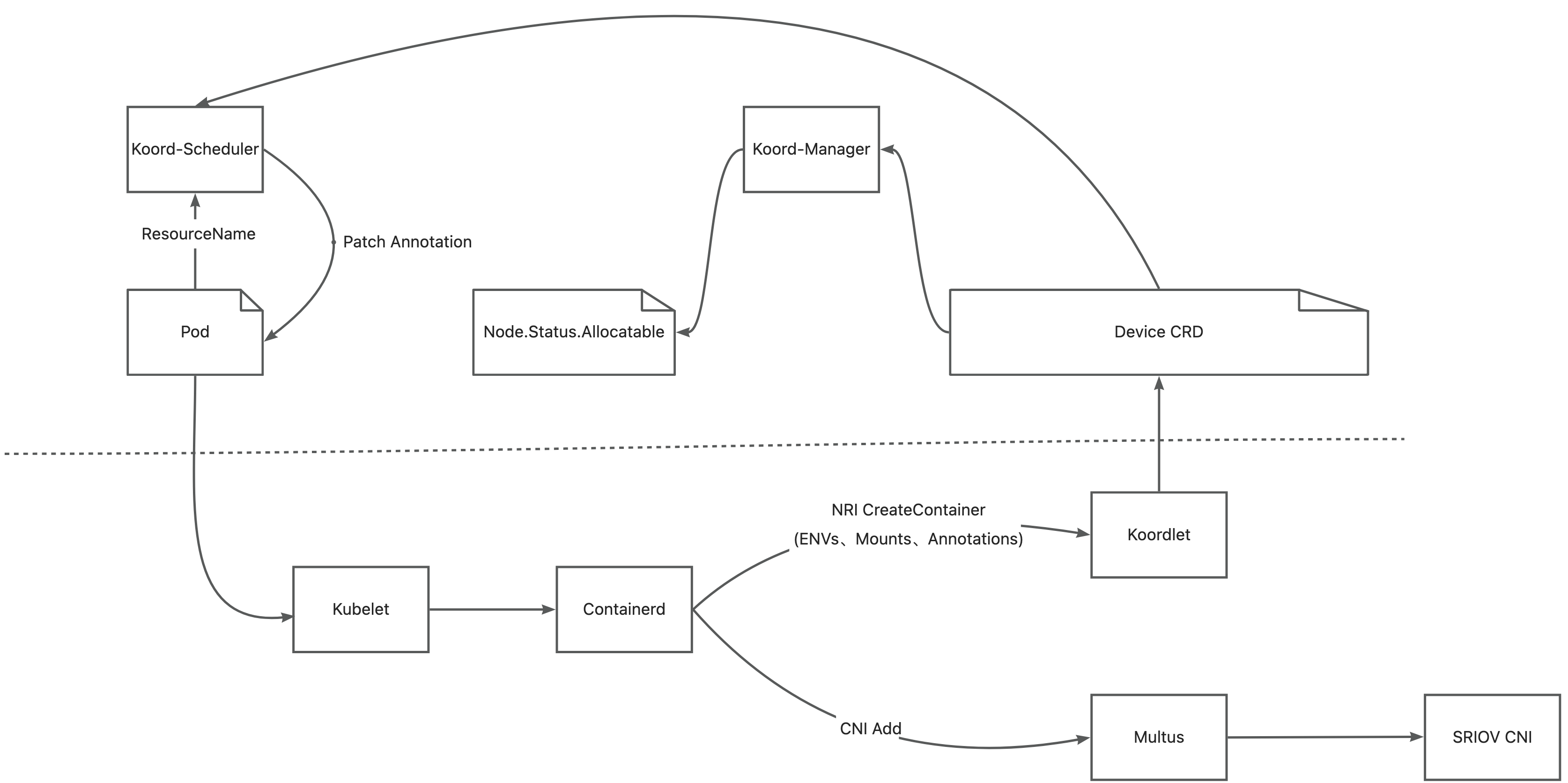
- Koordlet 检测节点上的 GPU 和 RDMA 设备,并将相关信息上报给 Device CR。
- Koord-Manager 从设备 CR 同步资源到 node.status.allocatable。
- Koord-Scheduler 根据设备拓扑为 Pod 分配 GPU 和 RDMA,并将分配结果注解到 Pods 上。
- Multus-CNI 访问 Koordlet PodResources Proxy 以获取分配给 Pods 的 RDMA 设备,并将相应的 NIC 附加到 Pods 的网络命名空间中。
- Koordlet 提供 NRI 插件,将设备挂载到容器中。
由于涉及到众多组件和复杂的环境,Koordinator v1.6.0 提供了最佳实践来展示如何一步步部署 Koordinator、Multus-CNI 和 SRIOV-CNI。在部署好相关组件之后,用户可以简单采用如下的 Pod 协议来请求调度器为它申请的 GPU 和 RDMA 进行联合分配:
apiVersion: v1
kind: Pod
metadata:
name: pod-vf01
namespace: kubeflow
annotations:
scheduling.koordinator.sh/device-joint-allocate: |-
{
"deviceTypes": ["gpu","rdma"]
}
scheduling.koordinator.sh/device-allocate-hint: |-
{
"rdma": {
"vfSelector": {} //apply VF
}
}
spec:
schedulerName: koord-scheduler
containers:
- name: container-vf
resources:
requests:
koordinator.sh/gpu: 100
koordinator.sh/rdma: 100
limits:
koordinator.sh/gpu: 100
koordinator.sh/rdma: 100
想要更进一步地采用 Koordinator 端到端地测试 GDR 任务,大家可以参考最佳实践中的样例一步步进行,在此也由衷感谢社区开发者 @ferris-cx 对该特性的贡献!
3、GPU 共享强隔离:提高 AI 推理任务的资源利用率
在 AI 应用中,GPU 是大模型训练和推理不可或缺的核心设备,能够为计算密集型任务提供强大的算力支持。然而,这种强大的算力往往伴随着高昂的成本。在实际生产环境中,我们经常会遇到这样的情况:一些小模型或轻量级推理任务仅需占用 GPU 的一小部分资源(例如 20% 的算力或 GPU 内存),但为了运行这些任务,却不得不独占一张高性能 GPU 卡。这种资源使用方式不仅浪费了宝贵的 GPU 算力,还显著增加了企业的成本。
这种情况在以下场景中尤为常见:
- 在线推理服务:许多在线推理任务的计算需求较低,但对延迟要求较高,通常需要部署在高性能 GPU 上以满足实时性需求。
- 开发与测试环境:开发者在调试模型时,往往只需使用少量 GPU 资源,但传统调度方式会导致资源利用率低下。
- 多租户共享集群:在多用户或多团队共享的 GPU 集群中,每个任务独占 GPU 会导致资源分配不均,难以充分利用硬件能力。
为了解决这一问题,Koordinator 结合 HAMi 为用户提供了 GPU 共享隔离的能力,允许多个 Pod 共享同一张 GPU 卡。通过这种方式,不仅可以显著提高 GPU 的资源利用率,还能降低企业成本,同时满足不同任务对资源的灵活需求。例如,在 Koordinator 的 GPU 共享模式下,用户可以精确分配 GPU 核心数或显存比例,确保每个任务都能获得所需的资源,同时避免相互干扰。
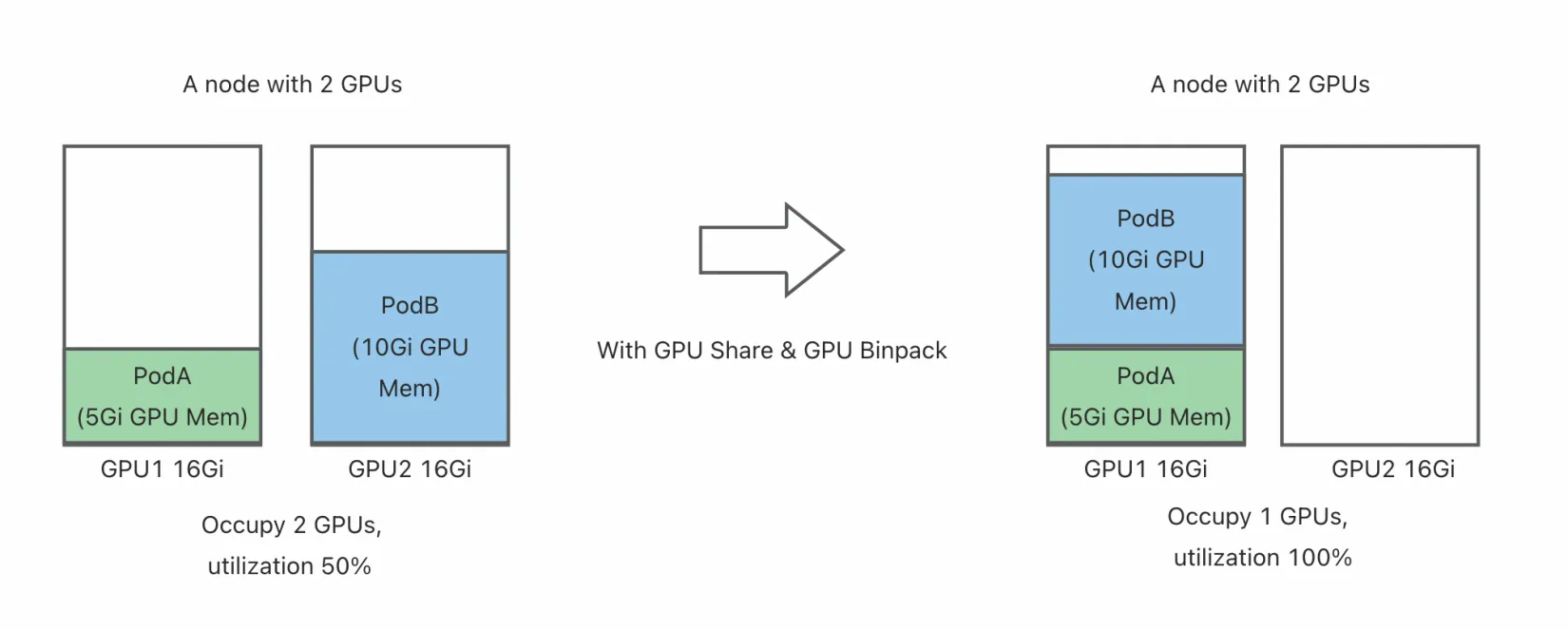
HAMi 是 CNCF Sandbox 项目,旨在为 Kubernetes 提供一个设备管理中间件。HAMi-Core 是它的核心模块,通过劫持 CUDA-Runtime(libcudart.so)和 CUDA-Driver(libcuda.so)之间的 API 调用提供 GPU 共享隔离能力。在 v1.6.0 版本中,Koordinator 利用 HAMi-Core 的 GPU 隔离功能,提供端到端的 GPU 共享解决方案。
大家可以通过下面的 YAML 文件部署 DaemonSet 直接在对应节点上安装 HAMi-core。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: hami-core-distribute
namespace: default
spec:
selector:
matchLabels:
koord-app: hami-core-distribute
template:
metadata:
labels:
koord-app: hami-core-distribute
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-type
operator: In
values:
- "gpu"
containers:
- command:
- /bin/sh
- -c
- |
cp -f /k8s-vgpu/lib/nvidia/libvgpu.so /usl/local/vgpu && sleep 3600000
image: docker.m.daocloud.io/projecthami/hami:v2.4.0
imagePullPolicy: Always
name: name
resources:
limits:
cpu: 200m
memory: 256Mi
requests:
cpu: "0"
memory: "0"
volumeMounts:
- mountPath: /usl/local/vgpu
name: vgpu-hook
- mountPath: /tmp/vgpulock
name: vgpu-lock
tolerations:
- operator: Exists
volumes:
- hostPath:
path: /usl/local/vgpu
type: DirectoryOrCreate
name: vgpu-hook
# https://github.com/Project-HAMi/HAMi/issues/696
- hostPath:
path: /tmp/vgpulock
type: DirectoryOrCreate
name: vgpu-lock
Koordinator 调度器的 GPU Binpack 能力是默认开启状态,在安装好 Koordinator 和 HAMi-Core 之后,用户可以通过如下方式申请 GPU 共享卡并启用 HAMi-Core 隔离。
apiVersion: v1
kind: Pod
metadata:
name: pod-example
namespace: default
labels:
koordinator.sh/gpu-isolation-provider: hami-core
spec:
schedulerName: koord-scheduler
containers:
- command:
- sleep
- 365d
image: busybox
imagePullPolicy: IfNotPresent
name: curlimage
resources:
limits:
cpu: 40m
memory: 40Mi
koordinator.sh/gpu-shared: 1
koordinator.sh/gpu-core: 50
koordinator.sh/gpu-memory-ratio: 50
requests:
cpu: 40m
memory: 40Mi
koordinator.sh/gpu-shared: 1
koordinator.sh/gpu-core: 50
koordinator.sh/gpu-memory-ratio: 50
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
restartPolicy: Always
关于在 Koordinator 启用 HAMi GPU 共享隔离能力的使用指导,请参考:
由衷感谢 HAMi 社区同学 @wawa0210 对该特性的支持!
4、差异化 GPU 调度策略:有效降低 GPU 碎片率
在现代 Kubernetes 集群中,多种类型资源(如 CPU、内存、GPU 等)通常在一个统一的平台上进行管理。然而,不同类型资源的使用模式和需求往往存在显著差异,这导致了对资源堆叠(Packing)和打散(Spreading)的不同策略需求。例如:
- GPU 资源:在 AI 模型训练或推理任务中,为了最大化 GPU 的利用率并减少碎片化,用户通常希望将 GPU 任务优先调度到已经分配了 GPU 的节点上(即“堆叠”策略)。这种策略可以避免因 GPU 分布过于分散而导致资源浪费。
- CPU 和内存资源:相比之下,CPU 和内存资源的需求更多样化。对于一些在线服务或批处理任务,用户更倾向于将任务分散到多个节点上(即“打散”策略),以避免单个节点上的资源热点问题,从而提高整体集群的稳定性和性能。
此外,在混合工作负载场景中,不同任务对资源的需求也会相互影响。例如:
- 在一个同时运行 GPU 训练任务和普通 CPU 密集型任务的集群中,如果 CPU 密集型任务被调度到 GPU 节点上并消耗了大量 CPU 和内存资源,可能会导致后续的 GPU 任务因非 CPU 资源不足而无法启动,最终处于 Pending 状态。
- 在多租户环境中,某些用户可能只申请 CPU 和内存资源,而另一些用户则需要 GPU 资源。如果调度器不能区分这些需求,可能会导致资源争用和不公平的资源分配。
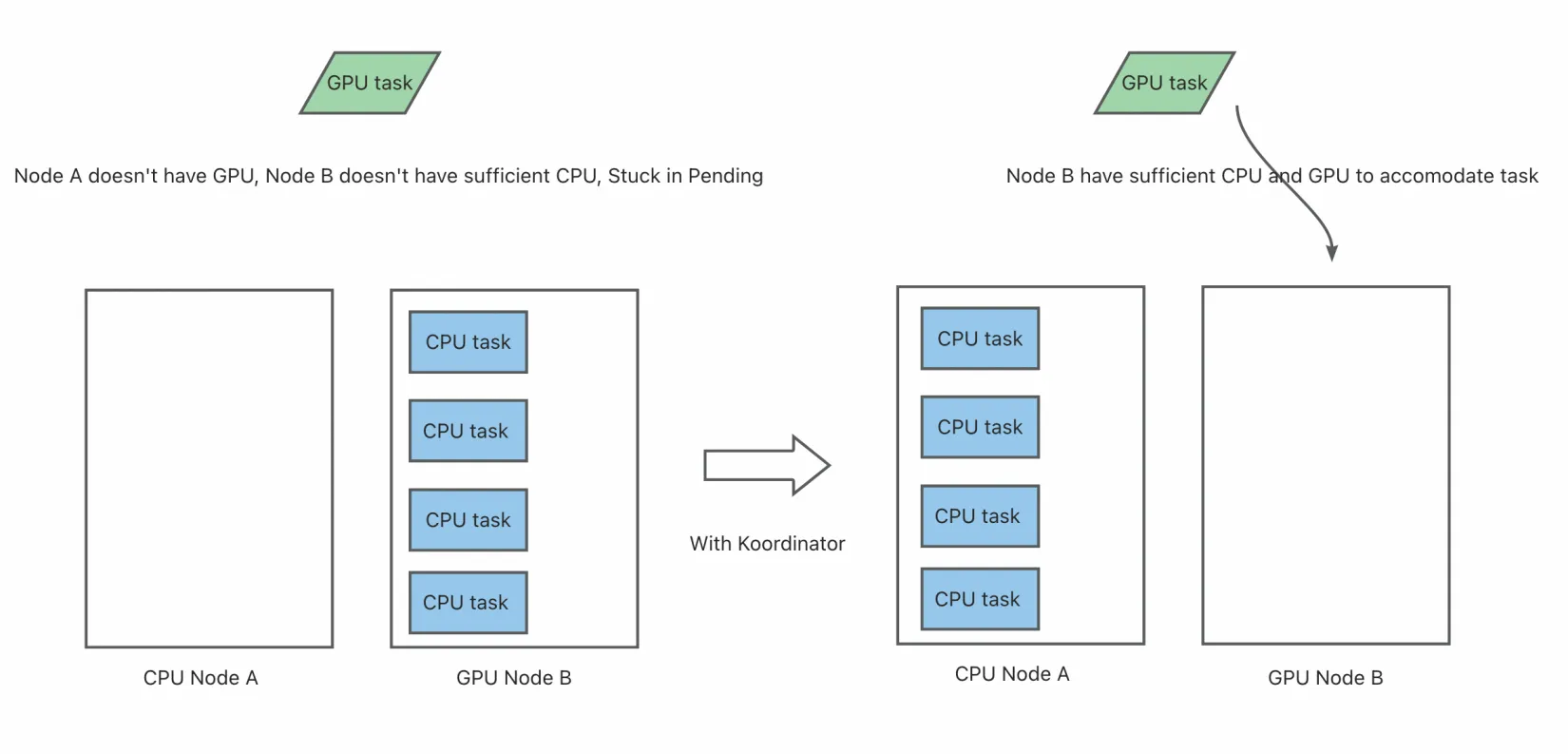
Kubernetes 原生的 NodeResourcesFit 插件目前对不同资源只支持配置同样的打分策略,举例如下:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- name: NodeResourcesFit
args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: NodeResourcesFitArgs
scoringStrategy:
type: LeastAllocated
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: nvidia.com/gpu
weight: 1
但在生产实践中,有些场景并不适用这种设计。例如:在 AI 场景中,申请 GPU 的业务希望优先占用整个 GPU 机器,防止 GPU 碎片化;申请 CPU&MEM 的业务希望优先 Spread,以降低 CPU 热点。Koordinator 在 v1.6.0 版本中引入了 NodeResourceFitPlus 插件以支持为不同资源配置差异化的打分策略,用户在安装 Koordinator 调度器时可配置如下:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: NodeResourcesFitPlusArgs
resources:
nvidia.com/gpu:
type: MostAllocated
weight: 2
cpu:
type: LeastAllocated
weight: 1
memory:
type: LeastAllocated
weight: 1
name: NodeResourcesFitPlus
plugins:
score:
enabled:
- name: NodeResourcesFitPlus
weight: 2
schedulerName: koord-scheduler
另外,申请 CPU&MEM 的业务会希望优先分散到非 GPU 机器,防止 GPU 机器上 CPU&MEM 消耗过大,导致真正的申请 GPU 任务因非 GPU 资源不足而处于 Pending 状态。Koordinator 在 v1.6.0 当中引入了 ScarceResourceAvoidance 插件以支持该需求,用户可配置调度器如下,表示 nvidia.com/gpu 是稀缺资源,当 Pod 没有申请该稀缺资源时尽量避免调度到上面。
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: ScarceResourceAvoidanceArgs
resources:
- nvidia.com/gpu
name: ScarceResourceAvoidance
plugins:
score:
enabled:
- name: NodeResourcesFitPlus
weight: 2
- name: ScarceResourceAvoidance
weight: 2
disabled:
- name: "*"
schedulerName: koord-scheduler
关于 GPU 资源差异化调度策略的详细设计和使用指导,请参考:
由衷感谢社区开发者 @LY-today 对该特性的贡献。
5、精细化资源预留:满足 AI 任务的高效运行需求
异构资源的高效利用往往依赖于与其紧密耦合的 CPU 和 NUMA 资源的精确对齐。例如:
- GPU 加速任务:在多 NUMA 节点的服务器中,如果 GPU 与 CPU 或内存之间的物理连接跨越了 NUMA 边界,可能会导致数据传输延迟增加,从而显著降低任务性能。因此,这类任务通常要求 GPU、CPU 和内存分配在同一 NUMA 节点上。
- AI 推理服务:在线推理任务对延迟非常敏感,需要确保 GPU 和 CPU 的资源分配尽可能靠近,以减少跨 NUMA 节点的通信开销。
- 科学计算任务:一些高性能计算任务(如分子动力学模拟或天气预测)需要高带宽、低延迟的内存访问,因此必须严格对齐 CPU 核心和本地内存。
这些需求不仅适用于任务调度,也延伸到了资源预留场景。在生产环境中,资源预留是一种重要的机制,用于为关键任务提前锁定资源,确保其在未来的某个时间点能够顺利运行。然而,在异构资源场景下,简单的资源预留机制往往无法满足精细化的资源编排需求。例如:
- 某些任务可能需要预留特定 NUMA 节点上的 CPU 和 GPU 资源,以保证任务启动后能够获得最佳性能。
- 在多租户集群中,不同用户可能需要预留不同类型的资源组合(如 GPU + CPU + 内存),并且希望这些资源能够严格对齐。
- 当预留资源未被完全使用时,如何灵活地将剩余资源分配给其他任务,同时避免影响预留任务的资源保障,也是一个重要挑战。
为了应对这些复杂的场景,Koordinator 在 v1.6 版本中对资源预留功能进行了全面增强,提供了更精细化和灵活的资源编排能力。具体包括以下改进:
- 支持精细化 CPU、GPU 资源的预留和抢占。
- 支持 Pod 对预留资源量的精确匹配。
- 资源预留亲和性支持指定预留名称和污点容忍属性。
- 资源预留支持 Pods 数限制。
- 支持资源预留抢占低优先级 Pod。
插件扩展接口变动:
- 预留资源校验接口 ReservationFilterPlugin 从 PreScore 阶段前置到 Filter 阶段以确保过滤结果更准确。
- 预留资源账本归还接口 ReservationRestorePlugin 废弃了不需要的方法以提升调度效率。
以下是新功能的使用示例:
- 预留资源量精确匹配(Exact-Match Reservation) 指定 Pod 精确匹配预留资源量,可以用于缩小一组 Pod 和一组预留资源的匹配关系,让预留资源的分配更可控。
apiVersion: v1
kind: Pod
metadata:
annotations:
# 指定Pod精确匹配预留的资源类别,Pod只能匹配在这些资源类别下预留资源量和Pod规格完全相等的Reservation对象;比如指定"cpu","memory","nvidia.com/gpu"
scheduling.koordinator.sh/exact-match-reservation: '{"resourceNames":{"cpu","memory","nvidia.com/gpu"}}'
- 忽略资源预留(reservation-ignored) 指定 Pod 忽略资源预留,可以让 Pod 填充已预留但未分配的节点空闲资源,配合抢占使用可以更减少资源碎片。
apiVersion: v1
kind: Pod
metadata:
labels:
# 指定Pod的调度可以忽略掉资源预留
scheduling.koordinator.sh/reservation-ignored: "true"
- 指定资源预留名称的亲和性(ReservationAffinity)
apiVersion: v1
kind: Pod
metadata:
annotations:
# 指定Pod匹配的资源预留名称
scheduling.koordinator.sh/reservation-affinity: '{"name":"test-reservation"}'
- 指定资源预留的污点和容忍
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: Reservation
metadata:
name: test-reservation
spec:
# 指定Reservation的Taints,其预留资源只能分配给容忍该污点的Pod
taints:
- effect: NoSchedule
key: test-taint-key
value: test-taint-value
# ...
---
apiVersion: v1
kind: Pod
metadata:
annotations:
# 指定Pod对资源预留的污点容忍
scheduling.koordinator.sh/reservation-affinity: '{"tolerations":[{"key":"test-taint-key","operator":"Equal","value":"test-taint-value","effect":"NoSchedule"}]}'
- 开启 reservation 抢占
注:当前不支持高优 Pod 抢占低优 Reservation 的用法。
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- pluginConfigs:
- name: Reservation
args:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: ReservationArgs
enablePreemption: true
# ...
plugins:
postFilter:
# 调度器配置中,关闭DefaultPreemption插件的抢占,开启Reservation插件的抢占
- disabled:
- name: DefaultPreemption
# ...
- enabled:
- name: Reservation
由衷感谢社区开发者 @saintube 对该特性的贡献!
6、混部:Mid tier 支持空闲资源再分配,增强 Pod 级别 QoS 配置
在现代数据中心中,混部技术已经成为提升资源利用率的重要手段。通过将延迟敏感型任务(如在线服务)与资源密集型任务(如离线批处理)混合部署在同一集群中,企业可以显著降低硬件成本并提高资源使用效率。然而,随着混部集群资源水位的不断提高,如何确保不同类型任务之间的资源隔离成为关键挑战。
在混部场景中,资源隔离能力的核心目标是:
- 保障高优先级任务的性能:例如,在线服务需要稳定的 CPU、内存和 I/O 资源,以满足低延迟要求。
- 充分利用空闲资源:离线任务应尽可能利用高优先级任务未使用的资源,但不能对高优先级任务造成干扰。
- 动态调整资源分配:根据节点负载的变化实时调整资源分配策略,避免资源争抢或浪费。
为了实现这些目标,Koordinator 持续构建和完善资源隔离能力。在 v1.6 版本中,我们主要围绕资源超卖和混部 QoS 展开了一系列功能优化和问题修复,具体包括以下内容:
- Mid 资源超卖和节点画像特性优化计算逻辑,支持超卖节点未分配资源,避免对节点资源进行二次超卖。
- 负载感知调度优化指标降级逻辑。
- CPU QoS、Resctrl QoS 支持 pod 维度配置。
- 带外负载管理补充 prometheus metrics,以增强可观测性。
- Blkio QoS、资源放大等特性的 bugfixes。
Mid 资源超卖从 Koordinator v1.3 版本开始引入,提供基于节点画像的动态资源超卖能力。但是,为了确保超卖资源的稳定性,Mid 资源完全从节点上已分配的 Prod pods 中获取,意味着空节点一开始是没有 Mid 资源的,这给一些工作负载使用 Mid 资源带来了诸多不便,Koordinator 社区也收到了一些企业用户的反馈和贡献。
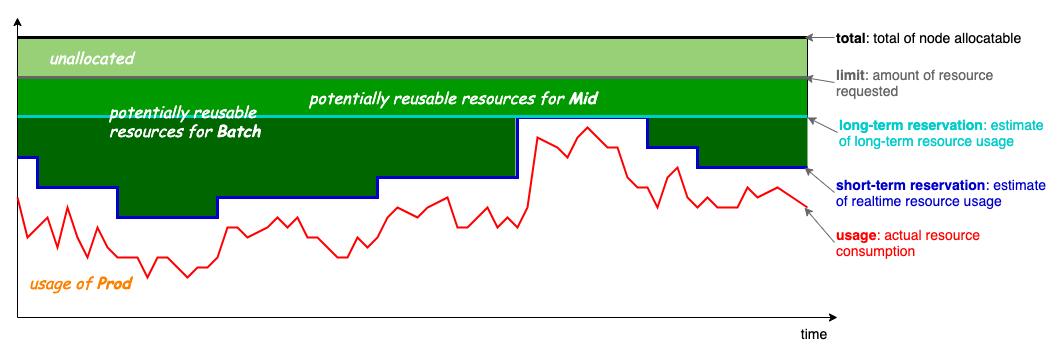 在 v1.6 版本中,Koordinator 更新了超卖计算公式,如下:
在 v1.6 版本中,Koordinator 更新了超卖计算公式,如下:
MidAllocatable := min(ProdReclaimable, NodeAllocatable * thresholdRatio) + ProdUnallocated * unallocatedRatio
ProdReclaimable := min(max(0, ProdAllocated - ProdPeak * (1 + safeMargin)), NodeUnused)
计算逻辑有两点变化:
- 支持按静态比例对未分配资源进行超卖,以改善冷启动问题。
- 不允许超卖实际已使用的节点资源,避免因二次超卖场景导致预估值过大;例如,一些用户使用了 Koordinator 的节点资源放大能力以调度更多 Prod pods,使得节点上 ProdAllocated > NodeAllocatable,导致 MidAllocatable 的预估值已经偏离真实的节点负载。
此外,在混部 QoS 方面,Koordinator v1.6 增强了 Pod 粒度的 QoS 策略配置能力,适用于例如混部节点上加黑干扰 Pod 以及灰度调整混部 QoS 的使用场景:
- Resctrl 特性,支持 Pod 维度的 LLC 和内存带宽隔离能力
- CPU QoS 特性,支持 Pod 维度的 CPU QoS 配置
Resctrl 特性可通过以下方式在 Pod 维度启用:
- 在 Koordlet 中 feature-gate 中启用 Resctrl 特性。
- 通过 Pod Annotation 协议node.koordinator.sh/resctrl,配置 LLC 及内存带宽(MB)限制策略。例如,
apiVersion: v1
kind: Pod
metadata:
annotations:
node.koordinator.sh/resctrl: '{"llc": {"schemata": {"range": [0, 30]}}, "mb": {"schemata": {"percent": 20}}}'
Pod 维度的 CPU QoS 配置则可通过以下方式启用:
- 启用 CPU QoS,请参照:https://koordinator.sh/docs/user-manuals/cpu-qos/
- 通过 Pod Annotation 协议koordinator.sh/cpuQOS,配置 Pod 的 CPU QoS 策略。例如,
apiVersion: v1
kind: Pod
metadata:
annotations:
koordinator.sh/cpuQOS: '{"groupIdentity": 1}'
由衷感谢 @kangclzjc、@j4ckstraw、@lijunxin559、@tan90github、@yangfeiyu20102011 等社区开发者在混部相关特性上的贡献!
7、调度、重调度:持续提升的运行效率
在云原生技术持续发展的今天,越来越多的企业将核心业务迁移到 Kubernetes 平台,集群规模和任务数量呈现爆发式增长。这种趋势带来了显著的技术挑战,尤其是在调度性能和重调度策略方面:
- 调度性能需求:随着集群规模的扩大,调度器需要处理的任务数量急剧增加,这对调度器的性能和扩展性提出了更高要求。例如,在大规模集群中,如何快速完成 Pod 的调度决策、降低调度延迟成为关键问题。
- 重调度策略需求:在多租户环境下,资源竞争加剧,频繁的重调度可能导致工作负载在不同节点之间反复迁移,进而增加系统负担并影响集群稳定性。此外,如何在保障生产任务稳定运行的同时,合理分配资源以避免热点问题,也成为重调度策略设计的重要考量。
为了应对这些挑战,Koordinator 在 v1.6.0 版本中对调度器和重调度器进行了全面优化,旨在提升调度性能、增强重调度策略的稳定性和合理性。以下是我们在当前版本中针对调度器性能的优化:
- 将 PodGroup 的 MinMember 检查提前到 PreEnqueue,减少不必要的调度周期。
- 将 Reservation 的资源归还延迟到 AfterPreFilter 阶段,只在 PreFilterResult 允许的节点上做资源归还,降低算法复杂度。
- 优化 NodeNUMAResource、DeviceShare、Reservation 等插件的 CycleState 分布,降低内存开销。
- 为 Koordinator 额外增加的扩展点如 BeforePreFilter、AfterPreFilter 新增延迟指标。
随着集群规模的不断扩大,重调度过程的稳定性和合理性成为核心关注点。频繁的驱逐可能导致工作负载在节点间反复迁移,增加系统负担并引发稳定性风险。为此,我们在 v1.6.0 版本中对重调度器进行了多项优化:
- LowNodeLoad 插件优化:
- LowNodeLoad 插件现在支持配置 ProdHighThresholds 和 ProdLowThresholds,结合 Koordinator 优先级(Priority)对工作负载的资源利用率进行差异化管理,能够减少生产应用引起的热点问题,从而实现更细粒度的负载均衡;
- 优化了对待驱逐 Pod 的排序逻辑,通过分段函数打分算法选出最适合驱逐的 Pod,确保合理的资源分配,避免因驱逐资源利用率最大的Pod而造成的稳定性问题;
- 优化了 Pod 驱逐前的检查逻辑,LowNodeLoad 在驱逐 Pod 前逐一检查目标节点是否会因重调度成为新的热点节点,这一优化有效避免了反复重调度的发生。
- 驱逐控制器 MigrationController 增强:
- MigrationController 具有 ObjectLimiter 的能力,能够控制某段时间内工作负载的驱逐频率。现在支持配置 namespace 级别的驱逐限流,对 namespace 下的驱逐进行更加精细化的控制;同时将ObjectLimiter从Arbitrator 迁移到 MigrationController 内部,修复了在并发场景下可能出现的限流失效问题;
- 新增 EvictAllBarePods 配置项,允许用户开启驱逐没有 OwnerRef 的 Pod,从而提高了重调度的灵活性;
- 新增 MaxMigratingGlobally 配置项,MigrationController 可以单独控制Pod的最大驱逐数量,从而降低了稳定性风险;
- 优化了 GetMaxUnavailable 方法的计算逻辑,当计算工作负载的最大不可用副本数向下取整为 0 时,默认将其调整为 1,避免导致用户对副本不可用数的控制失去预期的准确性和一致性。
- 新增重调度全局配置参数 MaxNoOfPodsToEvictTotal,可以确保重调度器全局的 Pod 最大驱逐数量,减少对集群的负担并提升稳定性;
由衷感谢社区开发者 @AdrianMachao、@songtao98、@LY-today、@zwForrest、@JBinin、@googs1025、@bogo-y 在调度重调度优化上的贡献!
未来计划
Koordinator 社区将继续专注于加强 GPU 资源管理和调度功能,提供重调度插件进一步解决资源分配不均衡导致的 GPU 碎片问题,并计划在下一个版本中引入更多新的功能和特性,以支持更复杂的工作负载场景;同时,在资源预留和混部方面,我们将进一步优化,以支持更细粒度的场景。
目前社区已经在规划的 Proposal 如下:
着重解决的使用问题如下:
长期规划的 Proposal 如下:
我们鼓励用户反馈使用体验,并欢迎更多开发者参与 Koordinator 项目,共同推动其发展!