使用自定义优先级重调度
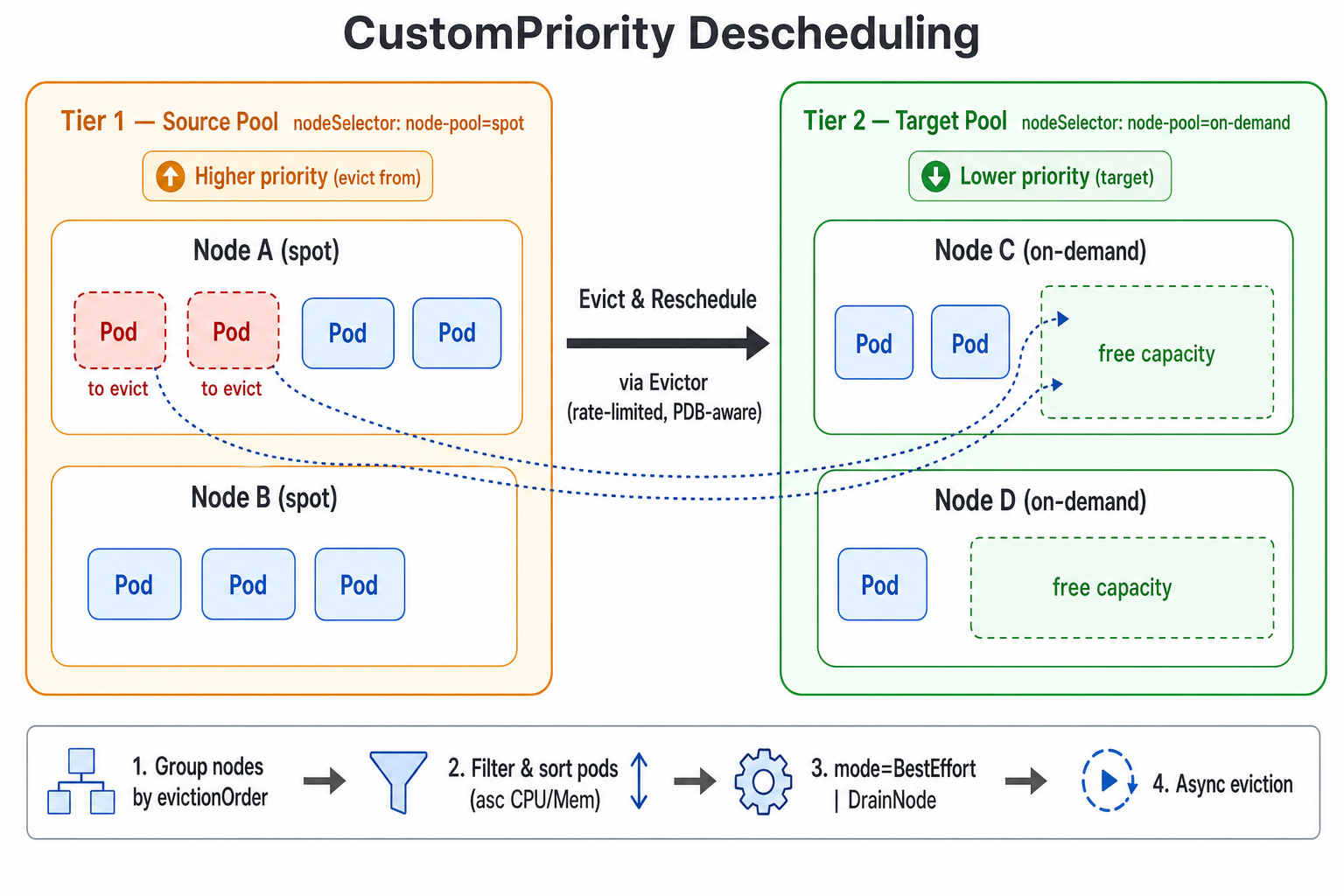
Koordinator Descheduler 提供 CustomPriority 插件,支持基于用户自定义的节点优先级顺序进行重调度。用户可以将集群中的节点按业务语义(例如按量付费 vs 包年包月、共享池 vs 专属池、Spot 实例 vs 常规实例等)划分为多个优先级组,当低优先级(更便宜或更易回收)的节点组上的资源能够容纳高优先级(更昂贵或更稀缺)节点组上的 Pod 时,重调度器会主动将 Pod 从高优先级节点驱逐,使其重新调度到低优先级节点上,从而帮助用户优化资源成本、释放高价资源或腾空指定节点池。
简介
CustomPriority 是 koord-descheduler 中的一个 balance 插件,它根据用户配置的节点优先级顺序决定“选谁驱逐”。
典型使用场景:
- 成本优化:例如将业务从按量付费节点迁移到包年包月节点。
- 资源规整:希望先把某一类节点的负载逐步下沉到另一类节点,以便缩容、维护或归还资源。
- 租户/池分层:根据多组节点池之间的优先级关系,进行 Pod 的按序下沉。
CustomPriority 插件在每个重调度周期内的执行流程如下:
- 将集群中的节点,按照
evictionOrder中定义的顺序进行分组。同一个节点只会被归入第一个匹配上的优先级组。 - 从最高优先级(
evictionOrder中靠前)的节点组开始,依次将其作为“源节点池”,把后续所有更低优先级的节点组作为“目标节点池候选”。 - 对每个源节点上的 Pod 进行筛选(命名空间、PodSelector、Evictor 过滤器等),并且按 CPU、Memory request 将待驱逐Pod进行升序排列。
- 根据
mode决定具体的驱逐策略:BestEffort(默认):只要单个 Pod 能在某个目标节点上找到位置,就发起驱逐。DrainNode:仅当源节点上所有候选 Pod 都能在目标节点池中找到合适位置时,才会驱逐该节点上的所有候选 Pod,达到“整节点腾空”的效果;否则跳过该节点。
- 实际的 Pod 驱逐由
Evictor异步发起,遵循Evictor的限流等所有保护机制。
使用自定义优先级重调度
通过插件参数全局配置
CustomPriority 插件默认未启用。您可以修改 ConfigMap koord-descheduler-config,开启该插件并提供节点优先级配置。新配置在 koord-descheduler 重启后生效。
下面是一个完整的、最小可运行的示例:将节点划分为两组(spot 与 on-demand),把 spot 节点上的 Pod 优先驱逐回 on-demand 节点(请按需调换顺序,配置中“靠前 = 驱逐源”,“靠后 = 目标候选”)。
apiVersion: v1
kind: ConfigMap
metadata:
name: koord-descheduler-config
namespace: koordinator-system
data:
koord-descheduler-config: |
apiVersion: descheduler/v1alpha2
kind: DeschedulerConfiguration
enableContentionProfiling: true
enableProfiling: true
healthzBindAddress: 0.0.0.0:10251
metricsBindAddress: 0.0.0.0:10251
leaderElection:
resourceLock: leases
resourceName: koord-descheduler
resourceNamespace: koordinator-system
deschedulingInterval: 60s
dryRun: false
profiles:
- name: koord-descheduler
plugins:
deschedule:
disabled:
- name: "*"
evict:
disabled:
- name: "*"
enabled:
- name: MigrationController
balance:
enabled:
- name: CustomPriority # 配置启用 CustomPriority 插件
pluginConfig:
- name: MigrationController
args:
apiVersion: descheduler/v1alpha2
kind: MigrationControllerArgs
evictionPolicy: Eviction
namespaces:
exclude:
- kube-system
- koordinator-system
- name: CustomPriority
args:
apiVersion: descheduler/v1alpha2
kind: CustomPriorityArgs
evictableNamespaces:
exclude:
- kube-system
- koordinator-system
nodeFit: true
mode: BestEffort
evictionOrder:
- name: "spot" # 优先级名(自定义即可),靠前 → 驱逐源
nodeSelector:
matchLabels:
node-pool: "spot"
- name: "on-demand" # 靠后 → 目标节点池候选
nodeSelector:
matchLabels:
node-pool: "on-demand"
应用配置并重启 koord-descheduler 使其生效:
$ kubectl apply -f koord-descheduler-config.yaml
$ kubectl -n koordinator-system rollout restart deploy/koord-descheduler
CustomPriorityArgs 的完整字段如下:
| 参数 | 说明 |
|---|---|
| evictableNamespaces | 控制可参与重调度的命名空间,不填表示所有Pod均可参与。include 与 exclude 二选一:include 表示仅处理列表中的命名空间;exclude 表示忽略列表中的命名空间,处理其他所有命名空间。 |
| nodeFit | 是否在驱逐前进行调度可行性检查(NodeAffinity、Selector、Toleration、可分配资源等)。默认值为 true。 |
| evictionOrder | 节点优先级数组。配置顺序即优先级顺序,靠前的层级会作为驱逐源,靠后的所有层级共同作为目标候选池。 |
| mode | 工作模式,可选值:BestEffort(默认,逐个 Pod 评估并驱逐)、DrainNode(整节点腾空策略,仅在节点上所有候选 Pod 都能装下时才驱逐该节点)。 |
| autoCordon | 仅在 mode: DrainNode 下生效。开启后,节点被判定可整节点腾空时,会先 cordon 源节点再发起 Pod 驱逐,避免新 Pod 调度回该节点;若驱逐失败会尝试自动 uncordon。 |
CustomPriority 至少需要 2 个
evictionOrder条目,否则插件不会执行任何动作并打印 INFO 级日志提示。
使用示例
下面演示一个最小验证流程:将 node-pool=spot 节点上的 Pod 重调度到 node-pool=on-demand 节点。示例集群中有 2 个 spot 节点与 2 个 on-demand 节点。
- 先给节点打上标签(按您实际的节点池规划替换):
$ kubectl label node <spot-node-1> node-pool=spot
$ kubectl label node <spot-node-2> node-pool=spot
$ kubectl label node <ondemand-node-1> node-pool=on-demand
$ kubectl label node <ondemand-node-2> node-pool=on-demand
- 创建一个测试 Deployment,让其首先调度到
spot节点上(例如借助 NodeAffinity,或在创建时仅给spot节点打标签):
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress-demo
namespace: default
labels:
app: stress-demo
spec:
replicas: 4
selector:
matchLabels:
app: stress-demo
template:
metadata:
name: stress-demo
labels:
app: stress-demo
spec:
schedulerName: koord-scheduler
containers:
- name: stress
image: polinux/stress
command: ["stress"]
args: ["--cpu", "1", "--vm", "1", "--vm-bytes", "256M", "--timeout", "3600s"]
resources:
limits:
cpu: "1"
memory: "512Mi"
requests:
cpu: "1"
memory: "512Mi"
$ kubectl create -f stress-demo.yaml
deployment.apps/stress-demo created
- 观察 Pod 状态直到其全部 Running,确认其首先调度到了
spot节点上。
$ kubectl get pod -o wide -l app=stress-demo
更新
koord-descheduler-config启用CustomPriority插件(参考上面的通过插件参数全局配置章节),并重启koord-descheduler。观察 Pod 分布与重调度过程。
koord-descheduler会通过MigrationController发起迁移,每一次迁移都可以通过PodMigrationJobCR 跟踪。
$ kubectl get pod -o wide -l app=stress-demo
$ kubectl get podmigrationjob -A
预期效果:
BestEffort模式下,运行在spot节点上的stress-demoPod 会被逐个驱逐,并在on-demand节点上重新调度成功。DrainNode模式下,只有当某个spot节点上所有候选 Pod 都能装入on-demand节点池时,该节点上的所有候选 Pod 才会被一并驱逐;若同时配置了autoCordon: true,被排空的源节点会被 cordon。当前还无法整节点腾空的源节点不受影响,仍可继续承载新调度的 Pod。